





Authors:
Tiancheng Shi、Yuanchen Wei、John R. Kender
Paper:
https://arxiv.org/abs/2408.07791
Introduction
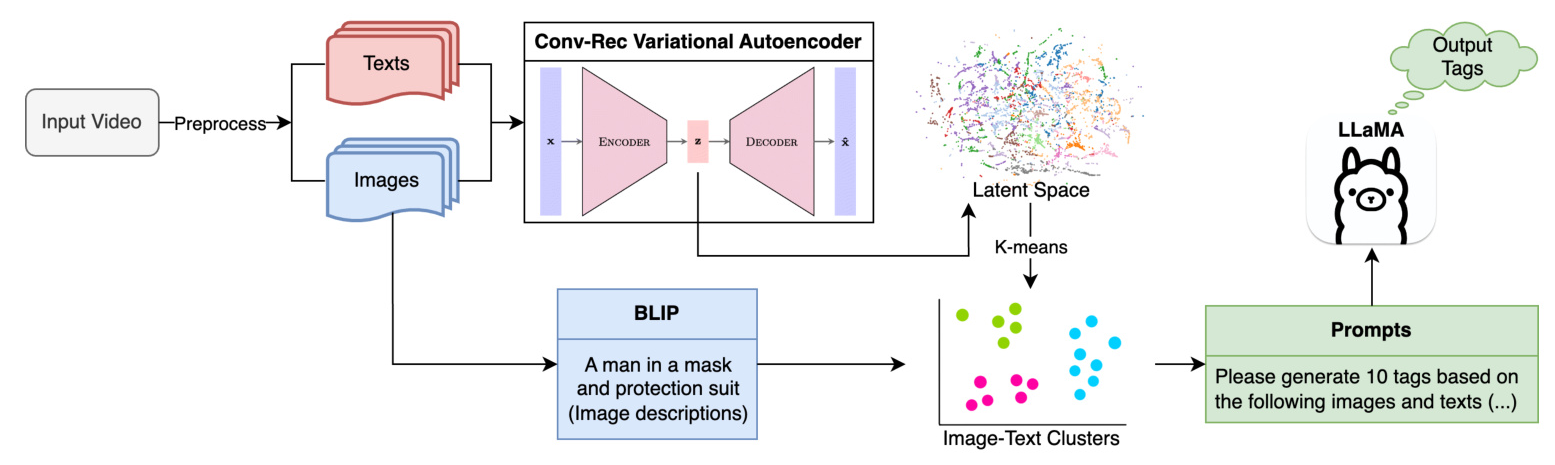
Videos are rich sources of information, combining both visual and auditory data. Extracting and summarizing this content efficiently is crucial, especially for comparing different cultural perspectives on the same event. This paper introduces a novel Convolutional-Recurrent Variational Autoencoder (CRVAE) model that integrates image and text data to generate thematic clusters from videos. The system aims to provide a quick and insightful comparison of videos from different cultures, focusing on international news events.
Related Works
Convolutional Variational Autoencoder
Previous research has utilized Convolutional Variational Autoencoders (CVAE) for image representation and clustering. However, these models often struggle with high-resolution images due to dimensionality issues. The paper discusses the limitations of using Global Max Pooling layers in CVAEs and proposes the use of dense layers to retain more spatial information.
Multimodal Representation Learning
Multimodal Representation Learning (MRL) aims to reduce the dimensionality of heterogeneous data while retaining essential information. The paper categorizes MRL frameworks into Joint Representation, Coordinated Representation, and Encoder-Decoder Frameworks. The proposed CRVAE model uses a modality-fusion method within an encoder-decoder framework, combining the strengths of these approaches.
Bimodal Deep Autoencoder
The Bimodal Autoencoder model, proposed by Ngiam et al., fuses image and audio data into a shared representation layer. The CRVAE model builds on this concept but focuses on learning shared representations of videos for further analysis without using zero-masks.
Methods
CRVAE Architecture
The CRVAE model processes images and text in parallel using Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) networks, respectively. The multimodal input vectors are combined through fully-connected layers, following an encoder-decoder structure. The latent space vectors, with reduced dimensions, are used for clustering and interpretation.


Encoder
Images
The image encoder uses convolution and max-pooling layers to process input images of dimensions 200 × 120 × 3. The number of filters is uniformly set to 32 to reduce the model size.
Text
The text encoder is an RNN-based model with pre-trained embedding weights. The LSTM model, with a hidden state vector length of 512 and two stacked layers, outperforms the vanilla RNN model.
Latent Layers
The outputs of the convolution and LSTM layers are flattened and normalized before being concatenated into a vector of dimension 14,048. This vector is then reduced to a latent layer with 2,000 neurons.
Resampling
The latent mean and standard deviation are used to resample across the latent space, and the resulting vector is passed to the decoder network for reconstruction.
Decoder
The decoder network mirrors the encoder network, gradually reconstructing the images and text from the latent space vectors.
Images
The image decoder uses transposed convolution layers to upsample the image channels, followed by convolution layers to reconstruct the original resolution.
Text
The text decoder predicts text embeddings as tensors and optimizes the Mean Squared Error (MSE) loss between the original and reconstructed text embeddings.
Teacher Forcing
The Teacher Forcing algorithm is applied to the text decoder, significantly improving performance by using ground-truth previous word embeddings as input.
Nearest Neighbors
The nearest neighbor method is used to “verbalize” the reconstructed text embeddings into words.
CRVAE Model Configuration
The final loss function combines image and text losses, with a ratio hyperparameter to balance the reduction of losses. The model is trained using the AdamW optimizer for 500 epochs on an NVIDIA GeForce RTX 3080 GPU.
Clustering and Cluster Interpretation
After encoding each pair into a latent space, K-means clustering is performed. The optimal number of clusters is chosen heuristically using various metrics.
Metrics
Metrics include average inter-cluster distance, average cross-cluster distance, and cluster robustness tests.
Tags
The BLIP model generates image descriptions, and the LLaMA model generates tags for each cluster. These tags help in understanding the cluster meanings.
Dataset
The system is evaluated on seven news events, including COVID-19 and the Winter Olympics, with videos from both English and Chinese sources.
English COVID-19 “New Variant” Video
This video discusses the resurgence of the Omicron variant in the US. It generates 109 image frames and 96 text segments.

Chinese COVID-19 “Vaccine” Video
This video encourages elderly Chinese citizens to take COVID-19 vaccines. It generates 378 image frames and 90 text segments.
English Olympic “Construction” Video
This video covers the construction of Winter Olympics venues in Beijing. It generates 60 image frames.
Chinese Olympic “Ceremony” Video
This video discusses the opening ceremony of the Winter Olympics. It generates 91 image frames.
Results
Autoencoder Model Experiments
Losses
The CRVAE model outperforms pure and dense CVAE models in terms of image loss, with a training time of around 30 minutes per video.

Image Reconstructions
The reconstructed images from the CRVAE model are clearer than those from CVAE models.

Text Reconstructions
The reconstructed texts are mostly accurate, with unknown tokens often verbalized as “well.”

Clustering
K-means clustering is performed on the latent space vectors, with typical K values set to 3, 4, or 5. The clusters are visualized using t-SNE.

Cluster Interpretation
BLIP-Generated Image Descriptions
BLIP successfully detects persons, objects, and backgrounds in frames but struggles with Optical Character Recognition tasks.
LLaMA-Generated Tags
The LLaMA model generates meaningful tags for each cluster, although some tags contain generic or mistaken information.

PhraseBERT-Embedded Vectors
PhraseBERT is used to measure tag similarities in the BERT 768-dimensional space.
Cross-cultural Comparisons
The system visualizes the relation between clusters across cultures, highlighting similarities and differences in the thematic content of videos.

Discussion and Future Work
The system demonstrates the effectiveness of the CRVAE model in summarizing and contrasting videos from different cultures. Future research could explore replacing the LSTM model with a Transformer model or augmenting other models with a similar two-network architecture.

Conclusion
The proposed CRVAE model efficiently integrates and processes multimodal video data, providing a robust system for thematic clustering and interpretation. The system’s ability to generate human-interpretable tags and visualize cross-cultural differences makes it a valuable tool for analyzing international news events.



