





Authors:
Gassyrbek Kosherbay、Nurgissa Apbaz
Paper:
https://arxiv.org/abs/2408.10549
AI-Based IVR: Enhancing Call Center Efficiency with AI Technologies
Introduction
In the modern era, traditional Interactive Voice Response (IVR) systems in call centers, which rely on voice menus and operator scripts, often fall short of meeting the growing demands of customers. Clients expect more personalized and efficient service, while operators face high workloads due to the diverse range of inquiries. Artificial Intelligence (AI) has emerged as a crucial tool for addressing these challenges by automating and optimizing processes in call centers. AI can analyze large volumes of data, identify hidden patterns, and offer solutions that were previously unattainable.
This study focuses on the development and implementation of AI solutions in IVR systems for call centers, specifically for the task of classifying customer inquiries. We will explore the adaptation of these technologies to work with the Kazakh language and discuss the practical aspects of implementing the proposed approach.
Related Work
Limitations of Traditional IVR Systems
Traditional IVR systems, based on voice menus and operator scripts, often fail to meet the growing needs of customers. They lack the necessary level of personalization and efficiency in handling diverse inquiries.
High Workload on Operators
Call center operators are required to handle a large number of diverse requests, leading to high workloads and reduced service quality. There is a need for solutions that can automate the processing of simple inquiries.
Complexity of Inquiry Classification
Classifying customer inquiries is a key task for effective routing and further processing. However, manual classification by operators becomes increasingly labor-intensive due to the growing diversity of requests.
Language Adaptation Challenges
Many call centers serve customers who speak various languages, including those with unique characteristics. In our case, this includes the Kazakh language. Ensuring high accuracy in speech recognition and inquiry classification for Kazakh is essential.
Research Methodology
Speech Recognition
One of the most critical tasks is real-time voice processing. Call centers must provide fast and accurate speech recognition, which requires modern tools and technologies. This involves using Automatic Speech Recognition (ASR) systems that can effectively handle diverse accents, intonations, and background noise. However, even the most advanced open solutions often lack support for the Kazakh language. We will address this issue in detail.
Text Processing
The next task involves processing the text obtained after speech recognition. Effective classification of text inquiries using AI technologies is necessary to determine the customer’s problem and route the inquiry accordingly. Given the large number of classes (around 200), traditional methods like button pressing are impractical. We must validate our classifier with the customer to ensure accurate routing.
Text-to-Speech Conversion
Integrating text-to-speech synthesis technologies is essential for providing personalized responses to customers and improving interaction. We will discuss the methods for text-to-speech conversion in the following sections.
Experimental Design
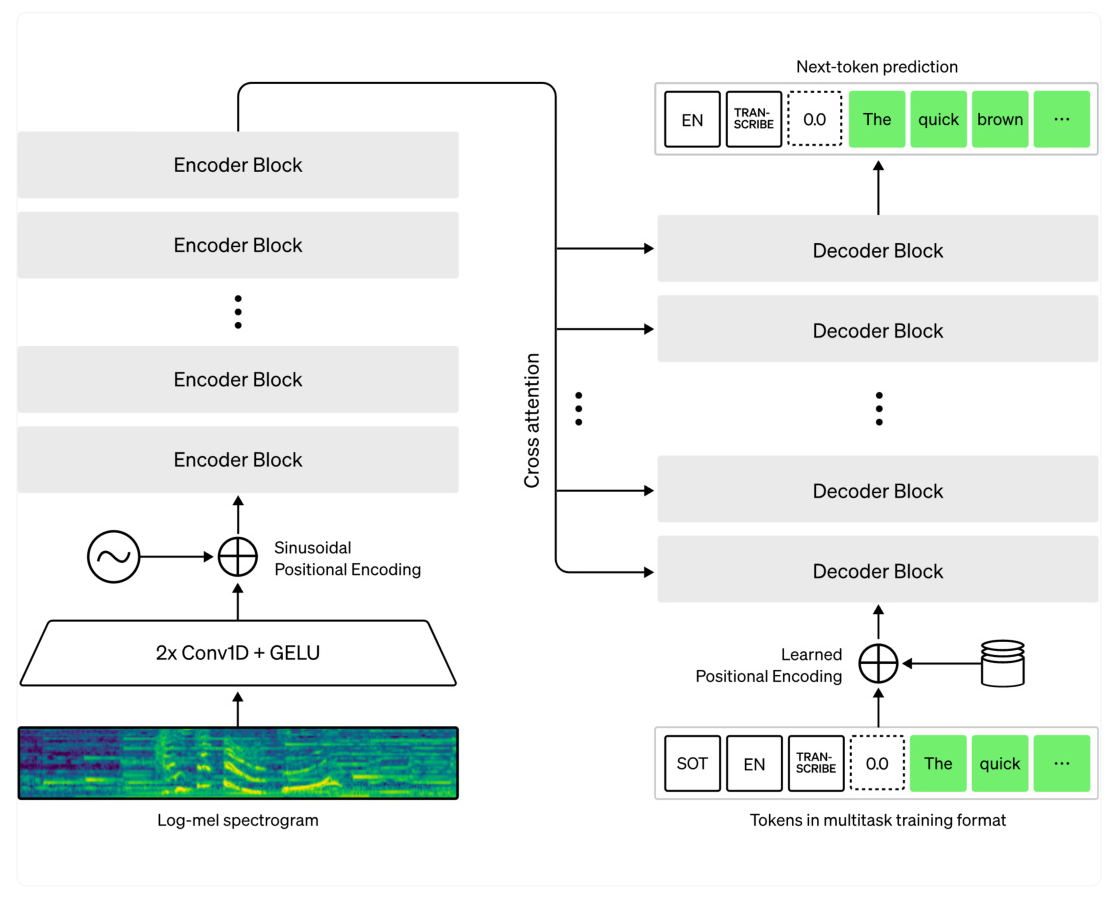
Whisper Model
Whisper is a large language model trained on a vast amount of transcribed audio data, enabling it to accurately convert speech to text across a wide range of languages. However, when working with languages that are underrepresented in the training data, such as Kazakh, the model’s performance may suffer, resulting in high Word Error Rates (WER) of around 50%. To address this, we propose fine-tuning the Whisper model on a specialized dataset of Kazakh speech provided by Al-Farabi Kazakh National University, which contains 558 hours of recordings in Kazakh. By applying fine-tuning techniques like Low-Rank Adaptation (LoRA), we can adapt the Whisper model to the unique characteristics of the Kazakh language and improve its accuracy for this specific use case.


Large Language Models (LLM)
In addition to speech-to-text conversion, we use large language models (LLM) for classifying customer text inquiries and building dialogues. LLMs are powerful deep learning models trained on vast amounts of text data, capable of performing a wide range of language tasks. For classifying customer problems, we chose the IrbisGPT model from MOST Holdings, which has knowledge of the Kazakh language. We also integrate Retrieval-Augmented Generation (RAG) technology to enrich the model with additional information.
To effectively use LLMs, we utilize Ollama, an open-source project that serves as a powerful and convenient platform for running LLMs on a local computer while ensuring privacy. Quantization is performed to significantly reduce the model size and computational requirements without significantly compromising prediction quality.
Text-to-Speech Integration
For further dialogue improvement, we integrate text-to-speech technologies like mms-tts-kaz from META. The complete process can be described as follows:
– Incoming speech inquiries are converted to text using the Whisper model.
– Text inquiries are classified using IrbisGPT.
– Classification results are routed for further processing.
– Text-to-speech conversion (mms-tts-kaz) vocalizes the classification back to the customer for validation and clarification.
– In case of negative customer feedback or system uncertainty, the inquiry is transferred to an operator for manual processing.
Results and Analysis
Whisper Model Fine-Tuning
We used the Whisper-small model for converting customer speech inquiries to text. After fine-tuning this model on the Kazakh speech dataset (KSD) provided by Al-Farabi University, we achieved a reduction in the Word Error Rate (WER) to 16% on test data (non-targeted from the call center). This significantly outperforms the results that could be obtained without additional model tuning. Fine-tuning was conducted on a T4 GPU.
Call Center Implementation
The call center is built on the Asterisk platform. We organized a pipeline from speech recognition to speech synthesis. The integration of AI technologies in IVR systems for call centers opens up vast opportunities for improving efficiency and customer service quality. Our approach, based on integrating speech-to-text conversion, text inquiry classification, and text-to-speech synthesis solutions, demonstrated significant practical results.
Overall Conclusion
The implementation of AI technologies in IVR systems for call centers offers extensive opportunities for enhancing efficiency and customer service quality. Our approach, based on integrating speech-to-text conversion, text inquiry classification, and text-to-speech synthesis solutions, has shown significant practical results. Future research in this direction may involve expanding the functionality of the AI system, improving inquiry classification accuracy, and integrating additional modules to enhance customer interaction.
References
- George Kour and Raid Saabne. Real-time segmentation of on-line handwritten Arabic script. In Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition (ICFHR), pages 417–422, IEEE, 2014.
- George Kour and Raid Saabne. Fast classification of handwritten on-line Arabic characters. In Proceedings of the 6th International Conference on Soft Computing and Pattern Recognition (SoCPaR), pages 312–318, IEEE, 2014.
- Alex Graves and Navdeep Jaitly. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, pages 1764–1772, PMLR, 2014.
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8748–8758, 2021.
- Eiji Kaneko, Yuya Fujii, and Chiori Hori. Acoustic model adaptation using teacher-student training for end-to-end speech recognition. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 163–170, IEEE, 2017.
- A. Aitzhanov, T. Tolegenov, A. Sharipbay, and K. Alimhan. Kazakh speech recognition using deep learning. In Proceedings of the 2019 IEEE 13th International Conference on Application of Information and Communication Technologies (AICT), pages 1–5, IEEE, 2019.
- Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Lu Wang. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the International Conference on Learning Representations, 2022.
- Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020.
- Xian Li, Yuxuan Jiang, Yutian Xu, Jingfeng Xue, Yujia Gao, Chao Huang, Yao Qian, Ke Hu, and others. Scaling Speech Technology to 1,000+ Languages. arXiv preprint arXiv:2305.13516, 2023.


