





Authors:
Yubing Cao、Yongming Li、Liejun Wang、Yinfeng Yu
Paper:
https://arxiv.org/abs/2408.06906
Introduction
Speech synthesis has seen significant advancements with the introduction of deep learning techniques, particularly Generative Adversarial Networks (GANs). This paper introduces VNet, a novel GAN-based vocoder designed to generate high-fidelity speech in real-time. The VNet model addresses the challenges of using full-band Mel spectrograms as input, which often result in over-smoothing and unnatural speech output. By incorporating a Multi-Tier Discriminator (MTD) and an asymptotically constrained adversarial loss, VNet aims to enhance the stability and quality of speech synthesis.
Related Work
GANs have revolutionized various domains, including speech synthesis. Traditional vocoder models, such as WaveNet, WaveRNN, and WaveGlow, have been outperformed by GAN-based models like MelGAN, HiFiGAN, and BigVGAN. These models leverage adversarial training to generate high-fidelity audio waveforms. However, they often rely on band-limited Mel spectrograms, which lack high-frequency information, leading to fidelity issues. VNet aims to overcome these limitations by using full-band Mel spectrograms and introducing a novel discriminator architecture.
Method
Generator
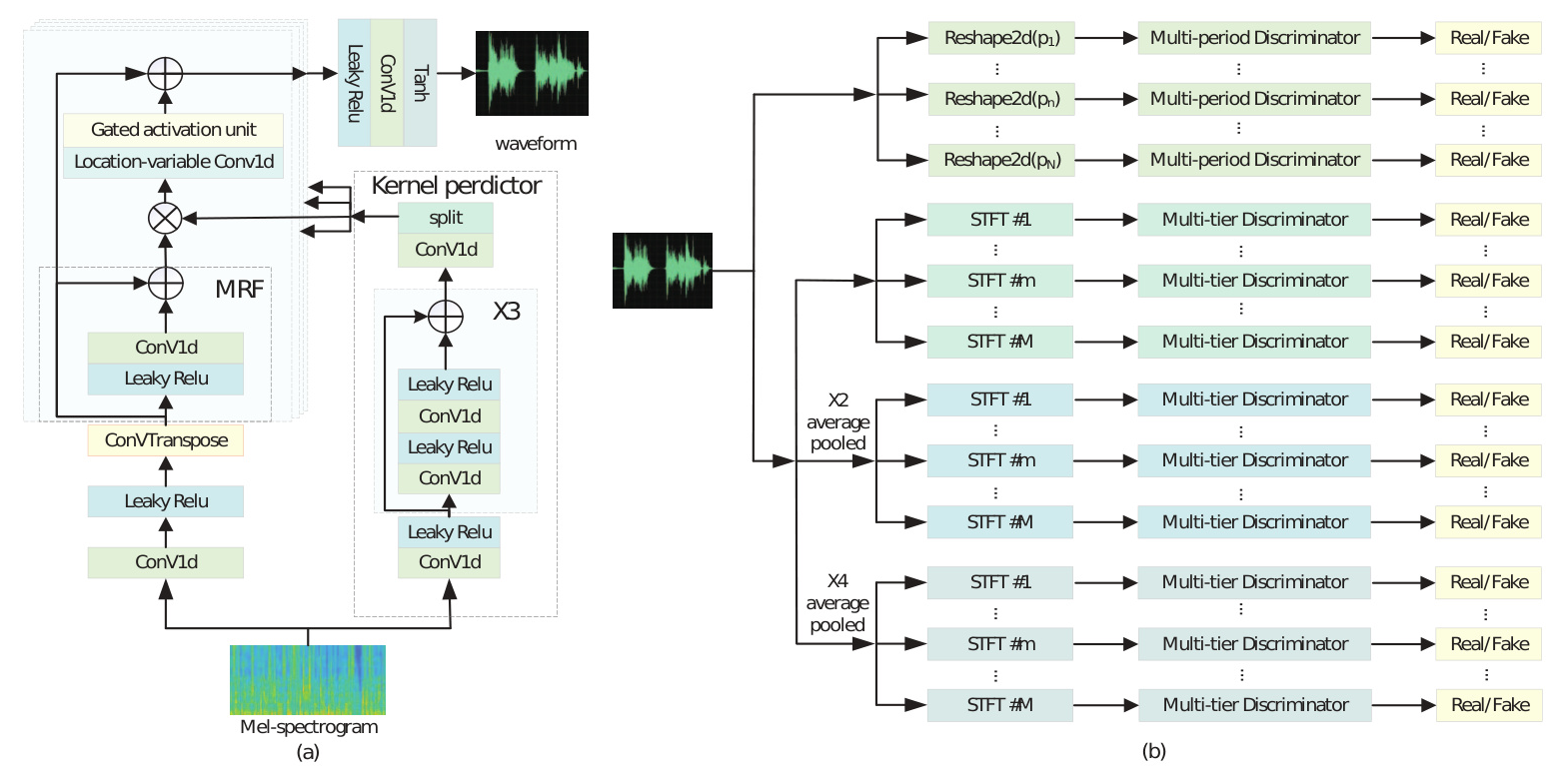
The generator in VNet is a fully convolutional neural network inspired by BigVGAN. It takes a full-band Mel spectrogram as input and uses inverse convolution for upsampling. The generator incorporates a Multi-Receptive Field (MRF) module to capture pattern features of varying lengths and a Location Variable Convolution (LVC) layer to enhance sound quality and generation speed. Gated Activation Units (GAUs) are also used to improve the model’s adaptability to speaker variations and mitigate overfitting risks.


Discriminator
The discriminator in VNet consists of two sub-modules: the Multi-Tier Discriminator (MTD) and the Multi-Period Discriminator (MPD). The MTD operates on multiple spectrograms computed from real or generated signals using different parameter sets. It captures continuous patterns and long-term dependencies in the audio data. The MPD, on the other hand, identifies various periodic patterns in the audio data by extracting periodic components from waveforms at prime intervals.

Training Losses
VNet employs feature matching loss and log-Mel spectrogram loss to enhance the training efficiency and fidelity of the generated audio. The adversarial losses of the generator and discriminator are modified using an asymptotic constraint method to ensure stable training. This approach constrains the adversarial training loss within a defined range, preventing the loss values from converging to suboptimal local minima.

Experiments
Data Configurations
The effectiveness of VNet is validated on the LibriTTS dataset, an English multi-speaker audiobook dataset. The models are trained using a frequency range of [0, 12] kHz and 100-band logarithmic Mel spectrograms. Objective evaluation is conducted on a subset of LibriTTS dev-clean and dev-other sets, while subjective evaluations are based on a 5-scale Mean Opinion Score (MOS) with 95% confidence intervals.
Evaluation Metrics
Objective assessment is conducted using five metrics: multi-resolution STFT (M-STFT), perceptual evaluation of speech quality (PESQ), mel-cepstral distortion (MCD), periodicity error, and F1 scores for voiced/unvoiced classification (V/UV F1). Additionally, MOS tests are conducted to evaluate the synthesized speech samples.
Comparison with Existing Models
VNet outperforms existing models like WaveGlow, Parallel WaveGAN, and BigVGAN in both objective and subjective evaluations. While the improvement in subjective scores compared to HiFi-GAN is marginal, VNet generates results approximately 1.5 times faster with a similar number of parameters.

Ablation Study
An ablation study is conducted to validate the significance of each component in VNet. The study shows that the absence of the MTD or the use of alternative discriminators like MPD and MSD leads to a decrease in audio quality. The modified adversarial loss function also plays a crucial role in ensuring stable training and high-quality speech synthesis.

Conclusions and Future Work
The VNet model demonstrates significant improvements in speech synthesis by addressing over-smoothing issues and enhancing the stability of the training process. Future research should focus on further reducing over-smoothing and exploring the model’s potential in multilingual and diverse speech styles. These advancements could greatly enhance the practical usability of GAN-based vocoders, resulting in more natural and expressive synthesized speech.



