





Authors:
Michele Fiori、Gabriele Civitarese、Claudio Bettini
Paper:
https://arxiv.org/abs/2408.06352
Introduction
Sensor-based Human Activity Recognition (HAR) is a significant area of research that involves using unobtrusive sensors to identify daily activities performed by humans. This technology is particularly crucial in smart-home environments to recognize Activities of Daily Living (ADLs) such as cooking, eating, and sleeping. Recognizing these activities can be vital for healthcare applications, including early detection of cognitive decline.
Deep learning methods are commonly used for HAR, but they are often considered black boxes, making it difficult for non-expert users like clinicians to trust and understand the model outputs. To address this, eXplainable Artificial Intelligence (XAI) methods have been developed to provide natural language explanations for model predictions. However, evaluating the effectiveness of these explanations is challenging and typically relies on costly and time-consuming user surveys.
This paper proposes an automatic evaluation method using Large Language Models (LLMs) to identify the best XAI approach for non-expert users. Preliminary results suggest that LLM evaluation aligns well with user surveys.
Evaluating Explanations Using LLMs
Problem Formulation and Research Question
Problem Formulation
Consider a smart-home equipped with various environmental sensors. The interaction of the user with the home environment generates high-level events, which are partitioned into fixed-time temporal windows. An eXplainable Activity Recognition (XAR) model maps each window to the most likely activity performed by the subject and provides a corresponding natural language explanation.
Research Question
Given a set of different XAR models and a pool of time windows, can we leverage LLMs to choose the best XAR model based on the explanations provided?
Prompting Strategies
Two distinct prompting strategies were employed to evaluate the explanations provided by different XAR models:
Best-Among-K Strategy
For each window and a set of alternative models, the LLM is prompted to determine the best explanation among the ones provided. The model that provided the best explanation is scored 1, while others are scored 0.
Scoring Strategy
The LLM assigns a score to each explanation for a window using the Likert scale (1 to 5). The model with the highest score is considered the best.
The Prompt
The system prompts for both strategies are shown in Figure 1. The prompts include instructions to align the LLM-based evaluation with that of a non-expert user and incorporate evaluation criteria inspired by a knowledge-based metric.


Experimental Evaluation
Datasets
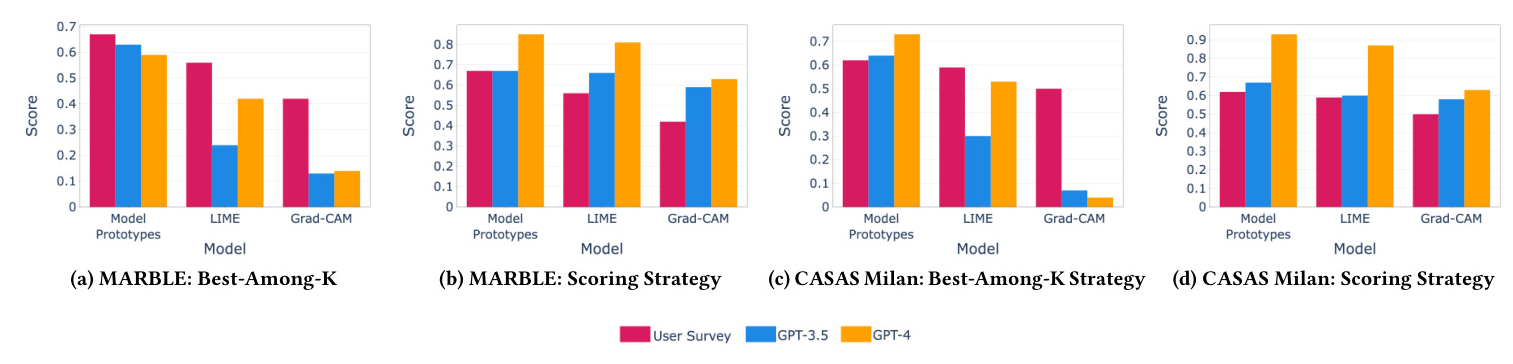
The datasets used for comparison include MARBLE and CASAS Milan. Surveys from these datasets were used to compare the quality of explanations produced by three different XAI methods: GradCAM, LIME, and Model Prototypes.
Experimental Setup
The LLM-based system was implemented in Python, using gpt-3.5-turbo-0125 and gpt-4-turbo models accessed through OpenAI APIs. The models’ temperature was set to 0 to minimize variability in answers. The experiments were repeated five times to ensure statistically robust results.
Metrics
The survey asked participants to rate each alternative explanation using a Likert scale. The overall result was summarized by computing the average of the scores given by the users and normalizing the results in the interval [0, 1].
Results
Figures 3a and 3b show the results of the evaluation on the MARBLE dataset. The LLM-based evaluation aligns well with user surveys, with Model Prototypes being the most appreciated, followed by LIME and GradCAM. Similar results were observed for the CASAS Milan dataset (Figures 3c and 3e).





Conclusion and Future Work
This work introduced the novel idea of using LLMs to automatically evaluate natural language explanations of XAI methods for sensor-based HAR. Preliminary experiments show that LLM-based evaluation is consistent with user surveys. Future work will focus on designing prompt strategies for different target users and evaluating other crucial aspects of explanations, such as understandability, trustworthiness, and reliability.
Acknowledgments
This work was supported by MUSA and FAIR under the NRRP MUR program funded by the EU-NGEU. The views and opinions expressed are those of the authors and do not necessarily reflect those of the European Union or the Italian MUR. Neither the European Union nor the Italian MUR can be held responsible for them.


