





Authors:
Aviv Bick、Kevin Y. Li、Eric P. Xing、J. Zico Kolter、Albert Gu
Paper:
https://arxiv.org/abs/2408.10189
Distilling Quadratic Knowledge to Subquadratic Models: A Deep Dive into MOHAWK
Introduction
Transformer architectures have revolutionized natural language processing (NLP) by providing state-of-the-art performance across various tasks. However, their quadratic-time self-attention mechanism poses significant computational challenges, especially for long sequences. This has led to the exploration of subquadratic alternatives, such as state space models (SSMs). Despite their potential, these models have not benefited from the extensive training resources that Transformers have. This paper introduces MOHAWK, a novel method to distill knowledge from pretrained Transformer models into subquadratic models like SSMs, thereby leveraging the computational investments made in training Transformers.
Related Work
Sequence Models
Autoregressive language models, particularly those based on Transformers, have demonstrated remarkable capabilities in tasks like zero-shot translation and long-range reasoning. However, their quadratic complexity has spurred the development of subquadratic alternatives, including RNNs, SSMs, and linear attention mechanisms. Hybrid models that combine attention mechanisms with subquadratic methods have also been proposed to balance efficiency and performance.
SSM Architectures
SSMs have evolved significantly, with models like GSS, H3, and Mamba pushing the boundaries of efficiency and performance. Mamba-2, a recent variant, leverages structured state space duality (SSD) to outperform Transformers in language modeling while being computationally efficient.
Distillation
Knowledge distillation transfers knowledge from a large teacher model to a smaller student model, retaining performance while improving efficiency. Most distillation efforts focus on compressing Transformers into smaller Transformers. However, cross-architecture distillation, such as converting Transformers into recurrent models, is gaining traction.
Research Methodology
Background and Overview
The core idea of MOHAWK is to view both Transformers and SSMs as sequence transformations that mix token embeddings using different matrix classes. This allows for a three-phase distillation process:
- Matrix Orientation: Aligning the sequence transformation matrices of the student and teacher models.
- Hidden-State Alignment: Matching the hidden-state representations of each layer.
- Weight-Transfer and Knowledge Distillation: Fine-tuning the student model to match the teacher model’s performance.
Mamba-2 Architecture
Mamba-2, a type of SSM, uses a time-varying state-space model with input-dependent projections. It draws a connection between SSMs and Transformers through SSD, showing that a special case of SSMs can be viewed as causal linear attention.
Experimental Design
Stage 1: Matrix Orientation
This stage aligns the student matrix mixer with the teacher’s self-attention matrix by minimizing the distance between them. This ensures that the student and teacher models have similar mixing layers, setting the foundation for subsequent stages.
Stage 2: Hidden-State Alignment
This stage further aligns the components of the student and teacher blocks by minimizing the L2 norm of their outputs. This ensures that the overall functionality is preserved from Stage 1.
Stage 3: Weight-Transfer and Knowledge Distillation
The final stage fine-tunes the student model to match the teacher model’s performance using a distillation loss. This stage can freeze all network components except the Mamba-2 sequence mixer, showcasing its powerful expressiveness.
Phi-Mamba Architecture
Combining the three stages of MOHAWK, the Phi-Mamba architecture merges the Mamba-2 model with the Phi-1.5 Transformer model. A hybrid variant, Hybrid-Phi-Mamba, retains some attention layers to leverage the strengths of both sequence mixers.
Results and Analysis
Final Results
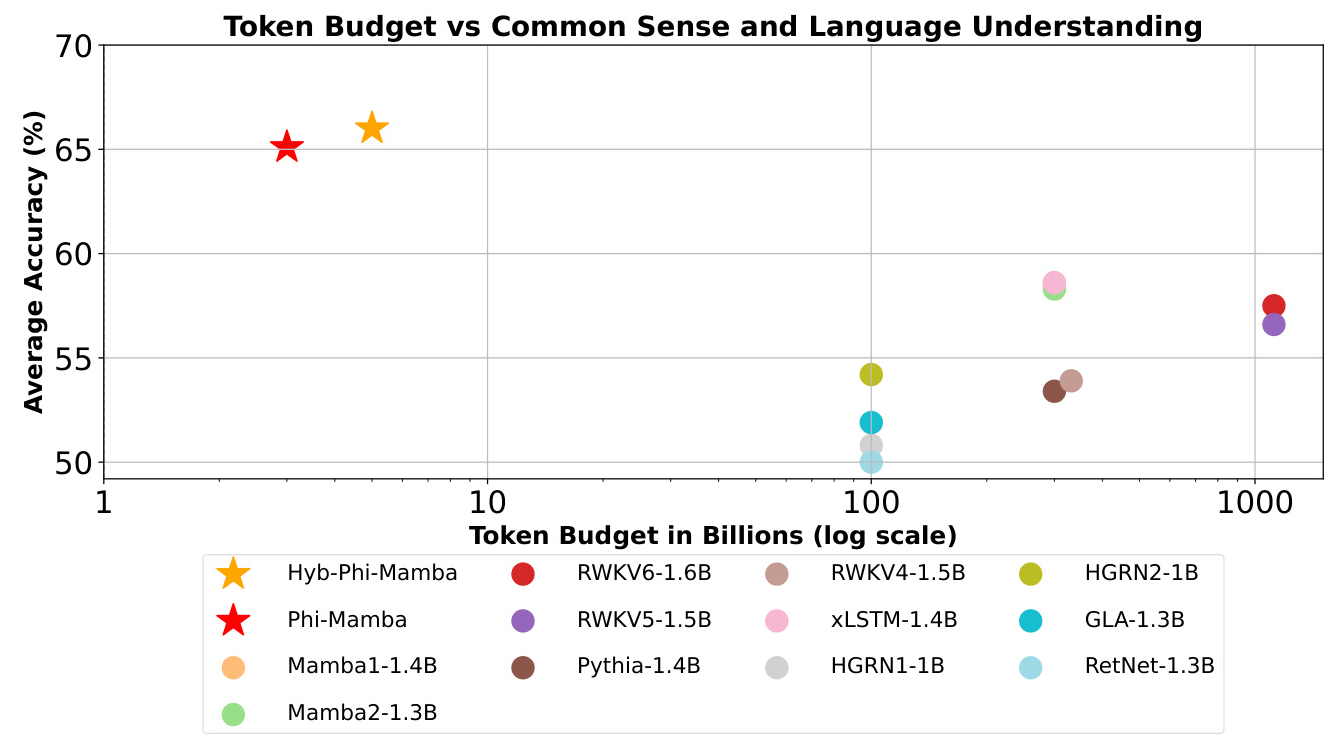
The Phi-Mamba model, distilled using MOHAWK, outperforms previous subquadratic models on various benchmarks while using significantly fewer training tokens. The hybrid variant, Hybrid-Phi-Mamba, also shows strong performance, closely matching the pure attention Transformer architecture.


Stage 3 Analysis
End-to-end distillation significantly improves performance, especially when combined with the previous stages. Freezing all components except the Mamba-2 sequence mixer during this stage does not significantly impact performance, highlighting the efficiency of the MOHAWK process.

Stage 2 Analysis
Hidden-state alignment improves downstream performance, with better-aligned initializations leading to lower perplexities and higher accuracies. This stage is crucial for the overall success of the distillation process.

Stage 1 Analysis
Matrix orientation provides foundational benefits that enhance performance in later stages. Even a small amount of training in this stage can significantly improve hidden-state distances and downstream metrics.

Hybrid Phi-Mamba Model
Hybrid models that integrate attention mechanisms with SSM layers show improved performance. The Hybrid-Phi-Mamba model, with only four attention layers, achieves strong results on downstream tasks.

Self-Attention Approximation
Mamba-2’s ability to approximate self-attention matrices is validated through experiments. The SSD matrix family provides the closest approximation, correlating with better model performance.

Overall Conclusion
The MOHAWK framework successfully distills knowledge from pretrained Transformer models into subquadratic models like Mamba-2, leveraging the extensive training resources invested in Transformers. This multi-stage distillation process significantly improves the performance of subquadratic models, making them viable alternatives for various NLP tasks. Future research should explore the role of sequence mixing layers in subquadratic models and further optimize the distillation process for hybrid architectures.



