





Authors:
Samee Arif、Sualeha Farid、Abdul Hameed Azeemi、Awais Athar、Agha Ali Raza
Paper:
https://arxiv.org/abs/2408.08688
Introduction
Large Language Models (LLMs) have demonstrated significant capabilities in various Natural Language Processing (NLP) tasks, such as text generation, question answering, and language understanding. However, these models sometimes deviate from user instructions and exhibit unintended behaviors. To address this, techniques like Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) have been developed to align LLM outputs more closely with human preferences.
This paper explores the use of multi-agent workflows to generate synthetic Preference Optimization (PO) datasets. The process is divided into two modules: response evaluation and response generation. The response evaluation module assesses and ranks responses generated by LLMs, while the response generation module focuses on creating responses that align with identified preferences. The study aims to automate and improve these processes using LLM agents.
Related Work
Preference Optimization
Preference Optimization has become a crucial technique for aligning model outputs with human preferences. Methods like DPO simplify the RLHF problem by converting it into a classification task, enabling straightforward extraction of the optimal policy. Other techniques, such as Kahneman-Tversky Optimization (KTO), improve performance without the need for preference pairs.
Agent Frameworks
Recent studies have explored the use of LLM multi-agent frameworks for various tasks. For instance, LLM-as-a-Judge has been evaluated on datasets like MT-Bench and Chatbot Arena, showing high agreement with human preferences. LLMs-as-a-Jury and Multi-Agent Debate (MAD) frameworks have also been explored, demonstrating the potential to reduce biases and increase response diversity.
Methodology
Experimental Setup
The study evaluates three categories of models: small-scale, mid-scale, and large-scale LLMs. The evaluation module assesses single agents and multi-agent frameworks on datasets like Alpaca Eval, FairEval, PandaLM-Eval, and MT-Bench. The generation module compares multi-agent frameworks using win rate to determine the best configuration for generating synthetic PO datasets.


LLM-as-Evaluator
LLM-as-Judge
The LLM-as-Judge approach evaluates six different LLMs on the Alpaca Eval dataset using three distinct prompting strategies: Direct Comparison, Independent Scoring, and Combined Scoring. The performance is measured using Cohen’s Kappa against human annotations.
LLMs-as-Jury
The LLMs-as-Jury approach extends the evaluation by forming juries composed of multiple LLMs. The performance of each jury configuration is analyzed on datasets like FairEval, PandaLM-Eval, and MT-Bench.
LLM Debate
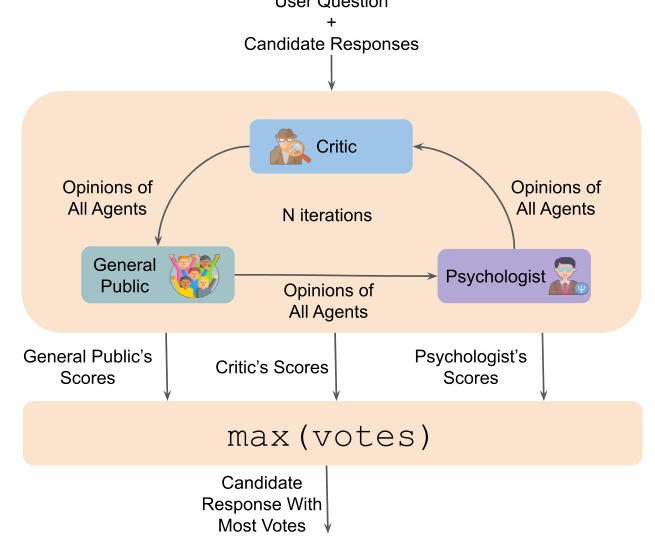
The LLM Debate framework assigns three distinct roles—Psychologist, General Public, and Critic—to agents that debate the scores assigned to candidate responses. This strategy is evaluated using the FairEval, PandaLM-Eval, and MT-Bench benchmarks.

LLM-as-Generator
The LLM Feedback Loop workflow for the generation module tests different configurations using Llama-3.1-8b and Gemma-2-9b models. The generator LLM produces a response, which is then evaluated by a feedback LLM that provides improvement suggestions. The process repeats for multiple iterations, and the win rate is calculated against single-agent baselines.

Preference Optimization Dataset
The study generates multiple DPO and KTO datasets for single-agent and multi-agent improvement. The evaluation module uses GPT-4o-as-a-Judge, while the generation module uses the LLM Feedback Loop with Llama-3.1-8b as the generator and Gemma-2-9b as the reviewer.
Results and Discussion
LLM-as-Evaluator
Prompting Strategies
The Combined Scoring strategy outperforms both Direct Comparison and Independent Scoring approaches across all evaluated LLMs. The scoring-out-of-10 scale is selected as the most effective option for the Combined Scoring approach.

LLM-as-Judge
GPT-4o outperforms all models on PandaLM-Eval and MT-Bench, achieving the highest Cohen’s Kappa scores. However, Gemma-2-27b performs best on the Fair-Eval dataset, indicating potential biases in favor of GPT models when GPT is the evaluator.

LLMs-as-Jury
The jury approach outperforms the judge approach on Fair-Eval and MT-Bench datasets, indicating a potential advantage in using multiple models for evaluation. However, the judge approach outperforms the jury on the PandaLM-Eval dataset.

LLM Debate
The LLM Debate approach shows varying degrees of effectiveness across different datasets. GPT-4o performs the best across all datasets, but the debate approach does not universally outperform the LLMs-as-a-Jury approach.

LLM-as-Generator
The Multi-Agent Feedback Loop with Llama as the generator and Gemma as the reviewer achieves the highest win rate against single-agent baselines. This configuration leverages the complementary strengths of different models to refine output quality.

Preference Optimization Dataset
The study generates PO datasets using the best configurations identified for both single-agent and multi-agent improvement. The datasets aim to improve single-agent capabilities for better response generation and multi-agent capabilities, including better communication and improved feedback.

Conclusion
This paper presents synthetic PO datasets generated using multi-agent frameworks and evaluates these frameworks by highlighting their advantages, drawbacks, and challenges. The LLM-as-a-Judge approach with GPT-4o is chosen as the primary evaluator for generating the PO dataset due to its consistent performance and lower computational requirements. The LLM Feedback Loop with Llama-3.1-8b as the generator and Gemma-2-9b as the reviewer demonstrates the potential of multi-agent frameworks in refined content generation.
Future Work
Future work includes performance comparison of models fine-tuned on the generated PO dataset versus widely-used LLMs, using larger models for dataset generation, and experimenting with the number of iterations in the Feedback Loop framework.


Code:
https://github.com/ulrs0/MA-PO


