





1. Abstract
This paper presents TRAIT, a task-oriented in-domain data augmentation framework for continual pre-training of large language models (LLMs). TRAIT addresses the challenges of data scarcity and lack of task awareness in domain-specific LLM adaptation. The framework consists of two main components: in-domain data selection and task-oriented synthetic passage generation. The in-domain data selection strategy identifies and selects relevant data from general corpora, significantly expanding the training dataset and enriching domain knowledge. The task-oriented synthetic passage generation strategy generates passages containing problem-specific and enlightenment paragraphs that guide the model on using domain knowledge to solve downstream tasks. The proposed framework and training strategy were evaluated on advertisement and math domains, demonstrating significant performance improvements compared to existing methods and the base LLM.
2. Quick Read
a. Research Methodology
TRAIT framework employs a two-stage training strategy:
- In-domain data selection:
- Trains a FastText classifier to identify in-domain data from general corpora.
- Applies a quality filter to ensure high educational value of the selected data.
- This approach addresses data scarcity and maintains model generality through replay.
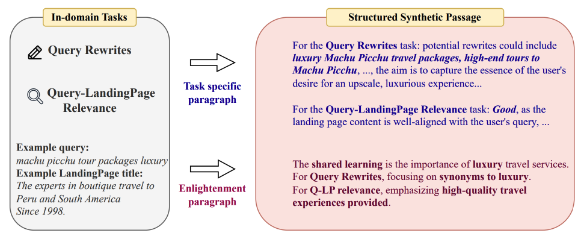
- Task-oriented synthetic passage generation:
- Constructs passages with multiple problems from different downstream tasks.
- Generates problem-specific paragraphs suggesting possible answers and reasoning processes.
- Includes an enlightenment paragraph highlighting shared and unique characteristics of the problems.
- This approach aligns the model with downstream tasks and improves its problem-solving ability.
Innovation and Improvements:
- Data Augmentation: Effectively addresses the issue of data scarcity in specific domains by selecting relevant data from general corpora.
- Task Orientation: Guides the model to learn how to apply domain knowledge to solve downstream tasks, improving its adaptability and performance.
- Two-stage Training: Enables the model to first learn domain knowledge and then learn how to apply it to solve tasks, leading to better performance on downstream tasks.
b. Experimental Process
The experimental process includes: - Data Preparation:
- Selects data from open-source datasets and general corpora for advertisement and math domains.
- Uses GPT-4 to generate task-oriented synthetic passages.
- Model Training:
- Uses Mistral-7B as the base model and trains it using DeepSpeed with ZeRO stage-1 optimizer.
- Compares TRAIT with random sampling and DSIR baselines.
- Evaluation:
- Evaluates the models on downstream tasks using AUC, win rate, diversity, and density metrics for advertisement tasks.
- Evaluates the models on math benchmarks using few-shot CoT reasoning and accuracy as metrics.
Results and Significance:
- TRAIT achieves significant performance improvements in both advertisement and math domains, demonstrating its effectiveness.
- The enlightenment paragraph in the synthetic passages contributes significantly to the model’s performance, especially in the math domain.
- The two-stage training strategy outperforms single-stage training, improving the model’s adaptability to downstream tasks.
c. Main Advantages - Data Augmentation: Effectively addresses the issue of data scarcity in specific domains.
- Task Orientation: Guides the model to learn how to apply domain knowledge to solve downstream tasks.
- Two-stage Training: Improves the model’s adaptability and performance on downstream tasks.
- Scalability: Can be applied to any new target domain, demonstrating its wide applicability.
3. Summary
a. Contributions
TRAIT paper’s main contributions include:
- Introducing a task-oriented in-domain data augmentation framework for LLMs.
- Designing a synthetic passage generation guideline to guide the model’s learning.
- Proposing a two-stage training strategy for better adaptation to downstream tasks.
- Experimentally demonstrating the effectiveness of TRAIT on advertisement and math domains.
b. Key Innovations - Data Augmentation: Addressing data scarcity by selecting relevant data from general corpora.
- Task Orientation: Guiding the model to learn how to apply domain knowledge to solve tasks.
- Two-stage Training: Improving model adaptability and performance through a structured learning process.
c. Future Research Directions - Exploring more effective data selection strategies for improved data quality and relevance.
- Researching advanced synthetic passage generation methods for more targeted learning.
- Applying TRAIT to more domains to validate its generalizability and applicability.
- Investigating ways to combine TRAIT with other domain adaptation techniques for further performance improvements.
View PDF:https://arxiv.org/pdf/2406.16694


