





Authors:
Yilun Kong、Hangyu Mao、Qi Zhao、Bin Zhang、Jingqing Ruan、Li Shen、Yongzhe Chang、Xueqian Wang、Rui Zhao、Dacheng Tao
Paper:
https://arxiv.org/abs/2408.10504
Introduction
Large Language Models (LLMs) have shown remarkable capabilities in various natural language processing (NLP) tasks. Prompt engineering, which involves adding instructions to input queries, has emerged as a promising technique to adapt LLMs to specific tasks without altering their parameters. However, existing prompt optimization methods often focus on task-level performance, neglecting the potential benefits of query-specific prompts. Additionally, these methods typically require frequent interactions with LLMs to obtain feedback, leading to high interaction costs.
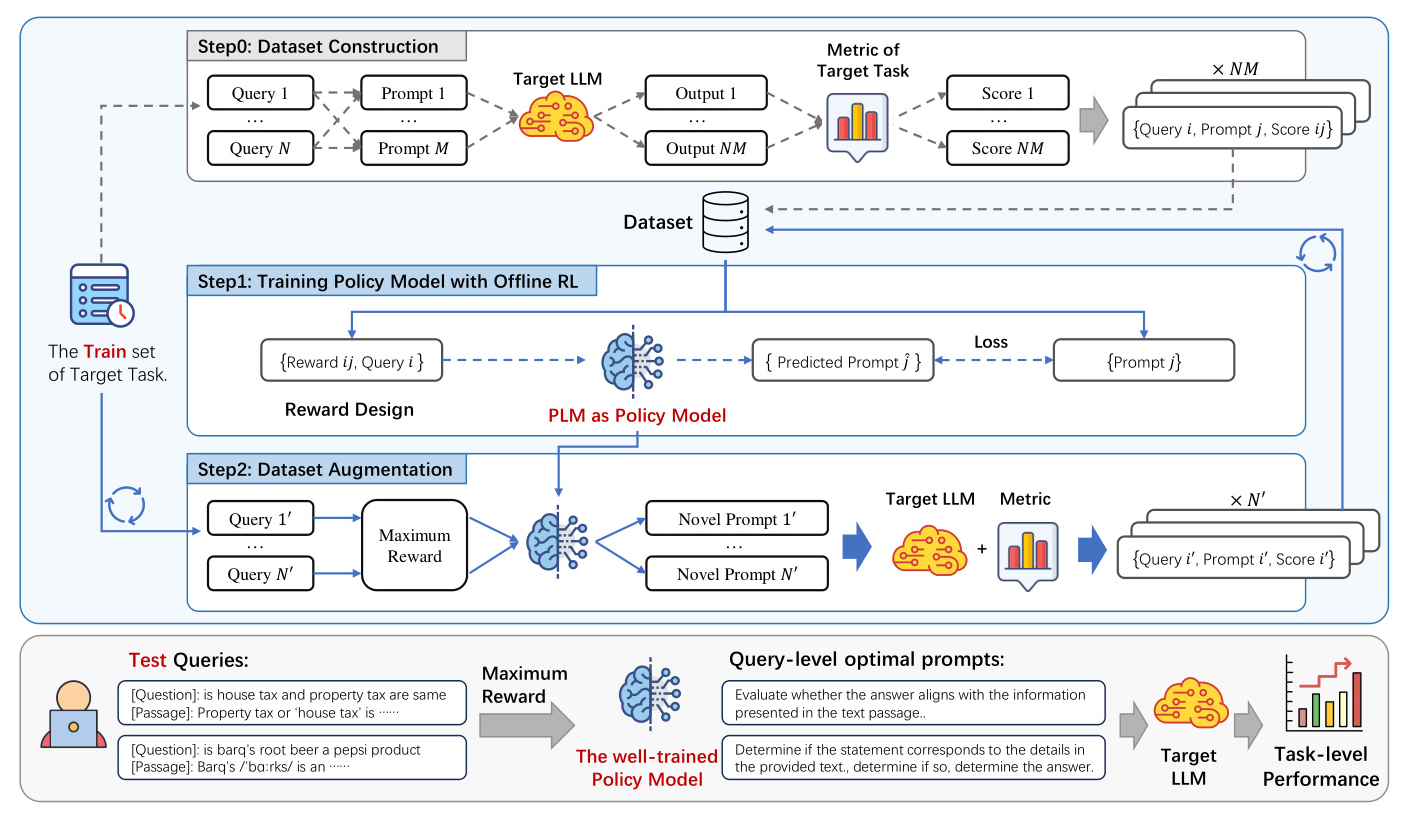
To address these challenges, the paper introduces Query-dependent Prompt Optimization (QPO), a novel method that leverages multi-loop offline reinforcement learning to fine-tune a small pretrained language model (PLM) to generate optimal prompts tailored to individual queries. This approach significantly enhances the performance of the target LLM while minimizing interaction costs.
Related Work
Prompt engineering has seen various approaches, including:
– Black-box optimization: Methods that use LLMs to derive optimal prompts through black-box optimization techniques.
– Reinforcement learning (RL): Approaches that train a policy model to generate optimal prompts using RL.
– Query-dependent optimization: Recent studies have shown that query-specific prompts can yield better performance compared to task-level prompts.
Despite these advancements, existing methods often overlook the importance of query-specific prompts and incur high interaction costs due to frequent feedback from LLMs.
Research Methodology
Problem Formulation
The goal is to train a policy model to generate prompts that instruct a target LLM to produce expected answers based on given queries. The key components include:
– Query and Answer: Queries ( q ) expressed in natural language with expected answers ( y^ ).
– Prompt and Policy Model: Prompts ( p ) that guide the LLM to complete the query. The policy model ( \pi ) generates query-specific prompts.
– Target LLM: The LLM ( \ell ) that processes queries and generates answers based on the prompts.
– Query-dependent Objective*: The objective is to optimize the policy model to generate prompts that enhance the LLM’s performance on specific queries.
Offline Reinforcement Learning Formulation
Prompt generation is formulated as a Markov Decision Process (MDP) with a single-step decision-making process. The reward design focuses on query-level and task-level rewards, measuring the prompt’s ability to instruct the LLM to answer queries correctly. The training objective combines log-likelihood maximization with a reward prediction loss to enhance the model’s ability to generate high-quality prompts.
QPO Framework for Multi-Loop Augmentation
The QPO framework involves the following steps:
1. Initial Demonstration Construction: Leveraging existing prompt optimization datasets to create an initial dataset.
2. Multi-Loop Augmentation: Iteratively fine-tuning the policy model and augmenting the dataset with new queries and prompts. This process reduces the need for frequent LLM interactions and enhances the policy model’s performance through continuous improvement.
Experimental Design
Tasks and Baselines
The experiments are conducted on various NLP and math reasoning tasks, including topic classification, natural language inference, sentiment classification, multi-choice QA, and math reasoning. The baselines include manual prompt engineering, online prompt optimization methods, and offline prompting approaches.
LLMs and Implementation Details
The policy model used is GPT-2, while the target LLMs include Llama2-7b-chat and GPT-3.5-turbo. The experiments are conducted in both zero-shot and few-shot settings, with extensive ablation studies to analyze different aspects of the proposed algorithm.
Results and Analysis
Main Results
The results demonstrate that QPO significantly outperforms existing methods in both zero-shot and few-shot settings across various tasks. The multi-loop augmentation technique efficiently improves performance with minimal interaction costs.


Multi-Loop Augmentation
The multi-loop augmentation process enhances the exploration of the query and prompt space, leading to substantial improvements in performance. The average number of queries and prompts in the dataset increases significantly, resulting in better coverage and diversity.

Interaction Costs
QPO requires significantly fewer interactions with the target LLM compared to online methods, making it a cost-efficient approach for prompt optimization.
Reward Design and Ablation Studies
The reward prediction loss and reinforcement learning formulation contribute to the superior performance of QPO. Ablation studies confirm the effectiveness of these components and the importance of data quality and prompt diversity.

Cross-Model Generalization
QPO demonstrates excellent cross-model generalization, indicating its potential to be applied to different LLMs without additional training.

Overall Conclusion
QPO introduces a novel query-dependent prompt optimization method through multi-loop offline reinforcement learning. By leveraging existing datasets and minimizing LLM interactions, QPO achieves state-of-the-art performance across various tasks. The method’s cost-efficiency and cross-model generalization capabilities significantly enhance its value for broader applications. Future work includes exploring inverse reinforcement learning to further reduce online interactions and extending the approach to other domains such as text-to-image and text-to-video generation.

Datasets:
IMDb Movie Reviews、GSM8K、AG News、HellaSwag、BoolQ、SVAMP、CosmosQA


