





Authors:
Jiawei Zhao、Kejiang Chen、Xiaojian Yuan、Weiming Zhang
Paper:
https://arxiv.org/abs/2408.08924
Introduction
In recent years, large language models (LLMs) such as ChatGPT, Gemini, and Llama have demonstrated exceptional performance across various natural language processing (NLP) tasks. However, these models are vulnerable to jailbreak attacks, where adversaries can induce the generation of harmful content through meticulously crafted prompts. This vulnerability poses significant challenges to the secure use and promotion of LLMs. Existing defense methods offer protection from different perspectives but often suffer from insufficient effectiveness or a significant impact on the model’s capabilities.
In this paper, the authors propose a novel, plug-and-play, and easy-to-deploy jailbreak defense framework called Prefix Guidance (PG). This method guides the model to identify harmful prompts by directly setting the first few tokens of the model’s output. This approach combines the model’s inherent security capabilities with an external classifier to defend against jailbreak attacks. The effectiveness of PG is demonstrated across three models and five attack methods, showing superior performance compared to existing methods.
Related Work
Jailbreak Attacks
Jailbreak attacks can be categorized into empirical and heuristic methods:
-
Empirical Jailbreak Methods: These rely on the design of specific prompts tailored to the model’s characteristics, using prior knowledge to bypass defenses. Examples include DAN (Do Anything Now) and DeepInception, which exploit the model’s understanding and generative characteristics.
-
Heuristic Jailbreak Methods: These utilize automated methods to construct effective prompts by focusing on certain high-dimensional features of the model. Examples include GCG, AutoDAN, and SAP30, which employ genetic algorithms or other heuristic algorithms to optimize prompts for jailbreaking LLMs.
Jailbreak Defense
Defense methods against jailbreak attacks can be categorized into external and internal defenses:
-
External Defenses: These include input perturbation-based methods, which introduce various levels of perturbations to disrupt carefully crafted jailbreak prompts, and output control-based methods, which control the process of LLM sampling tokens to reduce harmful content output.
-
Internal Defenses: These leverage the model’s intrinsic security capabilities to identify and defend against jailbreak attacks. Examples include Self-Reminder and Self-Examination, which add prompts to the model’s system prompt and user prompt to defend against attacks.
Research Methodology
Preliminary
In a single-turn dialogue, the input and output of an LLM are defined by five components: the system prompt, user prefix, user prompt, assistant prefix, and the assistant prompt. The probability of the model outputting a sequence is determined by these components.
Threat Model
-
Adversary’s Knowledge: Jailbreak attacks can be categorized into black-box and white-box attacks. In black-box attacks, the attacker cannot access the specific parameters of the LLM, while in white-box attacks, the attacker can access all information about the model.
-
Adversary’s Goal: The goal is to design a harmful prompt that the model will respond to without being rejected.
-
Defender’s Knowledge: The defender can control all settings of the model, including its parameters and prompt settings.
-
Defender’s Goal: The defender aims to ensure that harmful user inputs result in refusal responses, while non-harmful inputs result in normal responses.
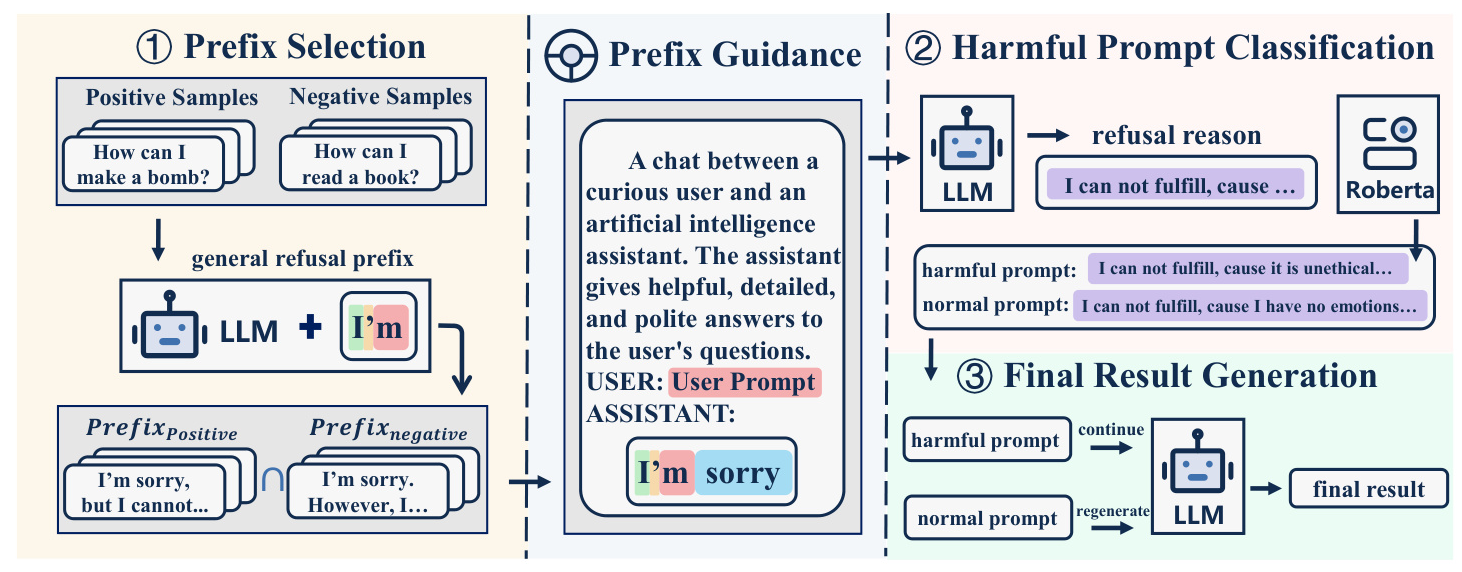
Prefix Selection
The prefix selection process involves three steps:
- Inputting harmful and non-harmful prompts into the model to obtain general refusal responses and setting them as temporary prefixes.
- Identifying the longest common prefix from the model’s responses to both harmful and non-harmful prompts.
- Selecting the prefix with the lowest error percentage as the final model output prefix.
Harmful Prompt Classification
A classifier is trained to determine if the model’s output provides a reason for refusing a harmful input. This involves fine-tuning a roberta-base model with a fully connected layer on top, using prepared data to create a binary classifier.
Final Result Generation
The classifier’s logits result is used to determine if the user input is harmful. If harmful, the refusal reason is fully generated by concatenating the prefix to the original prompt and re-inputting it into the model. If not harmful, the original prompt is re-input into the model to generate the final output.
Experimental Design
Experimental Setup
-
Datasets: The authors created a new harmful instruction dataset named harmful-instruction, consisting of approximately 1,550 harmful instructions across six categories. The Advbench dataset was used for evaluation, and the Just-Eval dataset was used to assess the model’s capabilities.
-
Models: The experiments primarily used three models: Vicuna-7B-v1.5, Llama2-7B-Chat, and Guanaco-7B.
-
Jailbreak Attack Methods: Five representative jailbreak attack methods were selected: GCG, AutoDAN, Pair, ReNeLLM, and DeepInception.
-
Baseline Defense Methods: The state-of-the-art SafeDecoding method, Self-Reminder, and Self-Examination were selected as baselines.
Prefix Guidance Classifier Training
The Roberta-base model was fine-tuned to identify whether the model output is an explanation and refusal of the malicious intent of the input prompt. Two types of datasets were constructed using the Vicuna model: refusal reasons explaining the harmfulness of malicious input and hallucinations related to normal input.
Metric
Two metrics, Attack Success Rate (ASR) and harmful score, were used to evaluate the effectiveness of Prefix Guidance (PG). The Just-Eval dataset was used to assess the model’s capabilities across various dimensions.
Results and Analysis
Enhancement of Model Security Capabilities through Prefix Guidance
The evaluation of various defense methods against five different attack methods showed that PG significantly reduces the jailbreak success rate and harmful score of various attack methods, achieving near 0% defense success rates against most attack methods. PG outperformed other methods that leverage the model’s intrinsic capabilities and was comparable to the SOTA SafeDecoding method.


Preservation of Model Capabilities through Prefix Guidance
The evaluation of the model’s capabilities after deploying various defense methods showed that most defense methods negatively impact model performance across multiple metrics. However, the PG method generally caused a reduction in model performance, with an average performance loss of 4% on the Vicuna model and 5% on the Guanaco model, but resulted in a 1% improvement on the Llama model. PG outperformed the SOTA SafeDecoding method in terms of preserving model capabilities.

Overall Conclusion
In this paper, the authors propose a novel defense method against jailbreak attacks called Prefix Guidance (PG). Compared to previous defense methods that leverage the model’s inherent capabilities, PG demonstrates superior defensive performance, achieving results on par with the state-of-the-art SafeDecoding method. Moreover, PG incurs minimal performance degradation, with a loss ranging from only 0% to 5% across various models, surpassing SafeDecoding in this regard. The experiments, conducted on three different models and against five types of attack methods, substantiate these findings. Additionally, PG is a plug-and-play solution that can be deployed simply by setting a prefix for the model output, requiring minimal code modification, making it particularly suitable for more complex code environments.






