





Authors:
Vishal S. Ngairangbam、Michael Spannowsky
Paper:
https://arxiv.org/abs/2408.08823
Introduction
Equivariant neural networks, which leverage symmetries inherent in data, have shown significant promise in enhancing classification accuracy, data efficiency, and convergence speed. However, selecting an appropriate group and defining its actions across the various layers of the network remains a complex task, particularly for applications requiring adherence to specific symmetries. This research aims to establish a foundational framework for designing equivariant neural network architectures by utilizing stabilizer groups.
In the context of equivariant function approximation, a critical insight is that the preimage of a target element in the output space can be characterized by the subset of the orbit of an input element, restricted to those connected by elements of the stabilizer group of the target. This understanding simplifies the choice of group ( G ) and its actions, aligning them with the equivalence class of the target function’s fibers in the input space.
This paper provides a theoretical basis for designing equivariant architectures in scientific applications where known symmetries play a crucial role. By grounding the architecture design in first principles, we aim to explain empirical successes observed in data-driven applications and enhance the effectiveness of these architectures in practical scenarios.
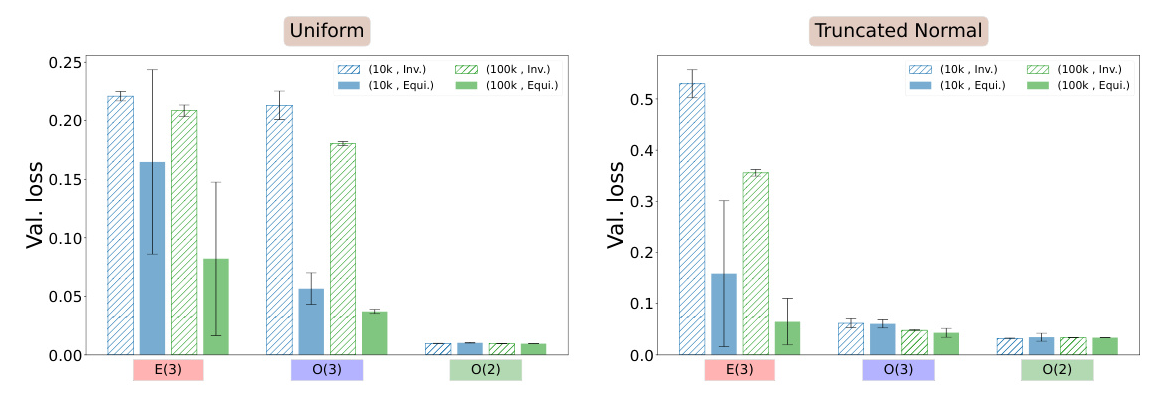
By quantifying the impact of equivariant architectures on sample efficiency and generalization error, we offer a comprehensive framework that not only aids in theoretical understanding but also provides practical guidelines for implementing these architectures in real-world scientific problems. Through simplified examples and experimental results, we demonstrate the applicability and effectiveness of our proposed methods.
Related Works
Group Equivariant Networks
Group equivariant architecture design is ubiquitous in modern deep learning algorithms with Convolutional Neural Networks being equivariant to translations. Modern generalizations include equivariance to discrete groups and gauge symmetries. It was shown that equivariance with respect to any compact group requires the operation of a layer to be equivalent to a generalized convolution on the group elements.
For set-based approaches, the DeepSets framework formulated the universal structure of permutation equivariant and invariant functions on elements belonging to a countable universe. Equivariant feature extraction on point clouds for the classical groups has also been explored. Geometric Algebra Transformer has been designed for 3D equivariant extraction of various non-trivial transformation groups, including the conformal and projective groups utilizing Clifford group equivariant networks.
Theoretical Analysis of Equivariant Models
Several theoretical results exist on the advantages of equivariant models. Under the assumption that the classification task is invariant to symmetry transformation, bounds on the generalization error were derived. The sample complexity for invariant kernel methods is studied. In the framework of PAC learning, it was shown that learning with invariant or equivariant methods reduces to learning over orbit representatives. At the same time, the incorporation of appropriate group equivariances results in a strict increase in generalization. Our work contributes in this direction by defining the notion of a correct symmetry for a binary classification task with a priori known symmetries of the probabilities.
Equivariance in Fundamental Physics
The importance of equivariance in fundamental physics cannot be overstated, starting from the Galilean transformations in the non-relativistic regime to the exotic structure of gauge theories, which form the mathematical backbone of our current understanding of the universe. Lorentz group equivariance has been explored. Other group equivariance studies include architectures for simulating QCD on the lattice and the classification of radio galaxies.
Preliminaries
Fibers of a Function
Our work relies on studying the minimal fiber structure induced by symmetries on the likelihood ratio and its relation to different group equivariant functions. A fiber is formally defined as:
Definition 1: Given a function ( f : X \to Y ), the fiber of an element ( y ) in the image of ( f ) denoted as ( f^{-1}(y) ), is the set of all elements of ( X ) which gets mapped to ( y ) via ( f ):
[ f^{-1}(y) = { x \in X : f(x) = y } ]
The fibers of all elements in ( \text{Im}(f) ) divide ( X ) into equivalence classes. This means that the set of fibers of any function partitions the domain ( D ) into mutually exclusive subsets. This holds true for any equivalence class in any given set, i.e., any element ( x \in X ) can only belong to a single equivalence class. We utilize this basic fact implicitly in different parts of the work.
Group Actions
The main idea underlying symmetries is the action of groups on an underlying set. Group actions and some related terminologies are defined as follows.
Definition 2: Given a group ( G ) and a set ( X ), the left-action of ( G ) on ( X ) is a map ( A : G \times X \to X ) with the following properties:
- ( A(e, X) = X ) for the identity element ( e \in G ) and any ( X \in X ), and
- ( A(g_1, A(g_2, X)) = A(g_1 g_2, X) ) for all ( g_1, g_2 \in G ) and ( X \in X ).
A ( G )-action will be denoted as ( (G, A(g, X)) ). Any set always admits the trivial action where ( A(g, X) = X ) for any group element ( g ) and all elements ( X ) of the set ( X ). Consequently, even for the same group ( G ), one can have two actions ( A_1(g, X) ) and ( A_2(g, X) ) acting on the same set ( X ), which are not necessarily the same functions. This motivates defining the equality of two ( G )-actions as follows.
Definition 3: Two ( G )-actions ( (G_1, A_1(g, X)) ) and ( (G_2, A_2(g, X)) ) acting on the same set ( X \ni X ) are equal if and only if ( G_1 ) is isomorphic to ( G_2 ), via an invertible map ( i : G_1 \to G_2 ) and ( A_1(g, X) = A_2(i(g), X) ) for all ( g \in G_1 ) and ( X \in X ).
Definition 4: The orbit of an element ( X \in X ) under the group action ( A(g, X) ) of the group ( G ), is the set of all elements ( X’ \in X ) for which there is a group element ( g \in G ) such that ( X’ = A(g, X) ).
We will write the orbit of a ( G )-action characterized by a vector of group invariants ( I ) as:
[ \Omega_X (I) = { X’ = A(g, X) : { X, X’ } \subset X \text{ and } g \in G } ]
The set of all distinct orbits divides ( X ) into equivalence classes.
Definition 5: The stabilizer group of an element ( X \in X ) with respect to the ( G )-action ( A ), is the set of all group elements ( g ) which leave ( X ) invariant. Mathematically, we will denote it as:
[ L_A(X) = { g \in G : X = A(g, X) } \subseteq G ]
A group representation ( \rho : G \to GL(m, R) ), naturally induces a linear action ( A_\rho : G \times R^m \to R^m ) on ( R^m ) of the form ( A_\rho(g, x) = \rho(g) x ). In the rest of the paper, we will be primarily concerned with such actions of a given transformation group on ( R^m ). We will work under the relaxation that these actions need not be closed in the domain of the target function ( D \subset R^m ), i.e., there may be group elements ( g \in G ) which takes a point ( x \in D ) to ( \rho(g) x = x’ \notin D ).
Group Equivariant Functions
Symmetries are built into neural networks using group equivariant maps, defined as follows.
Definition 6: A function ( f : X \to H ) between two spaces ( X ) and ( H ) which both admit group actions, say ( A_X ) and ( A_H ) respectively, for a group ( G ) is said to be ( G )-equivariant if ( f ) commutes with the group actions, i.e.,
[ f(A_X (g, X)) = A_H(g, f(X)) ]
for every ( g \in G ) and ( X \in X ). The map ( f ) is ( G )-invariant if the action ( A_H ) is trivial, i.e., ( A_H(g, H) = H ) for all ( g \in G ) and any ( H \in H ).
It is straightforward to see that a ( G )-equivariant map ( H = f(X) ), is ( L_{A_H}(H) )-invariant which may however be different groups for different values of ( H ). As we will be using the notion of universal approximation in the space of ( G )-equivariant functions, we outline the following general definition of the universal approximation property for a function space in the domain ( D ) to ( R ).
Definition 7: A class of parametrized models ( \Sigma_\theta(D) ) is said to be a universal approximator in the function space ( C(D) ) if the closure of the set ( \Sigma_\theta(D) ) in ( C(D) ) is ( C(D) ).
While the above definition subsumes definitions based on metrics via the corresponding metric topology, we will concentrate on those cases where the defined metrics involve taking a supremum in the domain ( D ). This means that we are primarily interested in subsets of the space of continuous functions rather than any strictly larger space like the space of ( L^1 ) integrable functions. Some instances of the universal approximation property (UAP) in the set of ( G )-equivariant functions can be found in the literature.
Notation of G-equivariant Function Spaces
We lay out some notation of function spaces, which will be used in the following sections. The set of all continuous ( G )-equivariant functions for particular actions ( A_X ) and ( A_H ) on the domain ( X ) and the codomain ( H ), respectively, will be denoted as ( E_G(A_X, A_H, X, H) ). When the action ( A_H ) is trivial, the set of all ( G )-invariant functions will be denoted by ( I_G(A_X, X, H) ). Where there is no ambiguity of the actions, domain, and codomain of the component functions, we will implicitly write these sets as ( E_G ) and ( I_G ).
Likelihood Ratio and Hypothesis Testing
We first outline a non-technical and intuitive picture of the ubiquitous Neyman-Pearson lemma which we will then connect to optimal binary classification. Consider an observed data ( X ) and we hypothesize that it originates from either ( P_0(X, \Theta_0) ) or ( P_1(X, \Theta_1) ), where ( \Theta_\alpha ) are parameters of the probability distribution. Those hypotheses where the probabilities are completely specified are said to be simple, i.e., each of the parameters ( \Theta_\alpha ) are fixed to specific values for ( \alpha \in {0, 1} ). The Neyman-Pearson lemma applies to scenarios where the two hypotheses are simple and exhaustive, i.e., the data can originate from only these two completely specified probabilities. The null hypothesis ( H_0 ), where ( X ) follows ( P_0 ), is usually chosen to represent the currently understood phenomena, while the alternate hypothesis ( H_1 ), where ( X ) follows ( P_1 ), are taken to describe possible phenomena in the new regime probed by the experiment.
The power of a statistical test is the probability of correctly rejecting the null hypothesis when the alternate hypothesis is true. At the same time, the significance is the probability of rejecting the null hypothesis when it is true. The Neyman-Pearson lemma states that the likelihood ratio ( \lambda(X) = P_1(X)/P_0(X) ) is uniformly the most powerful test statistic via which we can accept that ( X ) originated from ( P_1 ) for a given significance. Notably, a binary classification problem with an appropriate loss function (including binary cross-entropy) reduces to approximating a monotonic function of the likelihood ratio.
Optimal Binary Classification
As we aim to connect binary classification with the Neyman-Pearson optimality of hypothesis tests, we will utilize an analogous and straightforward definition of optimality in binary classification following the standard formulation of the receiver operator characteristics curve. Let us take the binary classification of a sample ( X ) sampled from either ( P_0(X) ) or ( P_1(X) ) with the same support ( D \subset R^m ), where we are interested in maximally selecting those samples originating from ( P_1 ). Often, the support of the alternate hypothesis’ probability distribution function (pdf) ( P_1 ) is contained within that of the null hypothesis ( P_0 ). On the other hand, if there is some part of ( P_1 )’s support outside ( P_0 ), any event obtained in this region trivially can only follow the alternate hypothesis. We are, therefore, primarily interested in those non-trivial cases where the data falls in the intersection of the support of ( P_0 ) and ( P_1 ). For a given classifier ( \hat{f} : D \to R ) which learns the underlying class assignment map by segregating samples from ( P_1 ) to negative values, dependent on a threshold ( t \in R ) the cumulative distribution of ( \hat{y} = \hat{f}(X) ) under ( P_\alpha ) are:
[ \epsilon_\alpha = C_\alpha(t) = \int_D dV P_\alpha(X) \Theta(\hat{y} < t) ]
where ( dV ) is the volume element in ( D ). Therefore, ( \epsilon_1 ) is the true positive rate and ( \epsilon_0 ) is the false positive rate and the former can be cast as a function of the latter using the threshold ( t ), ( \epsilon_1 = C_1 \circ C_0^{-1}(\epsilon_0) = \text{ROC}(\epsilon_0) ). We now have the following definition of an optimal binary classifier.
Definition 8: A binary classifier for data sampled from two distributions ( P_0(x) ) and ( P_1(x) ) is optimal in accepting samples from ( P_1 ) at a given tolerance ( \epsilon_0 ) of accepting false samples from ( P_0 ), if it has the highest possible acceptance of samples ( \epsilon_1 ) from ( P_1 ).
The connection to Neyman-Pearson’s optimality of the likelihood ratio can be seen as follows. For each ( X ), if the null hypothesis ( H_0 ) is that the underlying distribution is ( P_0 ) and the alternate hypothesis ( H_1 ) is that it is ( P_1 ), it is straightforward to see that ( \epsilon_0 ) is the significance of the test and ( \epsilon_1 ) is its power. Therefore, we have the following observation.
Observation 1: A binary classifier ( \hat{f} : D \to R ) of data ( X \in D ) sampled from either ( P_0(X) ) or ( P_1(X) ) is an optimal classifier for all values of ( \epsilon_0 ), if and only if it is a monotonic function of the likelihood ratio ( P_1(X)/P_0(X) ).
The relaxation to a monotonic function of the likelihood ratio follows from the integral definition of ( \epsilon_\alpha ) depending implicitly on the threshold, i.e., we are interested in choosing regions in ( D ) divided by hypersurfaces which have constant likelihood ratios. For a ( d )-dimensional domain, these are at least ( d-1 ) dimensional, and therefore, they are computationally non-trivial to evaluate in high dimensions even when one can write down closed-form expressions for the probabilities. Additionally, a necessary condition for any function to be the optimal classifier is to have an identical fiber decomposition in the domain ( D ) with the likelihood ratio.
Minimal Fibers of Group Equivariant Functions
Since a necessary optimality condition in binary classification is to have the same fiber decomposition in the domain ( D ), we now describe the minimal fibers of group equivariant functions.
Invariant Functions
Let ( h : X \to H ) be a ( G )-invariant function, i.e. for any ( X \in X ) and all ( g \in G ),
[ h(A_X (g, X)) = h(X) ]
This means that if ( X \in \Omega_X (I) ) then for all ( X’ = A_X (g, X) \in \Omega_X (I) ), ( h(X’) = h(X) ). Therefore, we have the following observation:
Observation 2: The fiber of an element ( H = h(X) \in H ) in the image of a ( G )-invariant function ( h : X \to H ) is at least as large as the orbit ( \Omega_X (I) ) of ( X \in X ) of the action ( A_X ). If the map is equal for elements belonging to distinct orbits, the fiber becomes enlarged to the union of these orbits.
Let ( h(X) ) become equal for ( X ) in all orbits parameterized by ( I ) in the set ( F ) of orbit invariants ( I ). The fiber ( h(X) ) for any ( X ) in these orbits is:
[ h^{-1}(X) = \bigcup_{I \in F} \Omega_X (I) ]
Equivariant Functions
Let ( f : X \to H ) be a ( G )-equivariant function with respect to the actions ( A_X ) and ( A_H ) on ( X ) and ( H ), respectively. If ( X’ = A_X (g, X) ) is in the orbit of ( X ), from Eq 2, we have (


