





Authors:
Qiming Xia、Hongwei Lin、Wei Ye、Hai Wu、Yadan Luo、Shijia Zhao、Xin Li、Chenglu Wen
Paper:
https://arxiv.org/abs/2408.08092
Introduction
In recent years, LiDAR-based 3D object detection has seen significant advancements. However, the process of annotating 3D bounding boxes in LiDAR point clouds is labor-intensive and time-consuming. This paper introduces OC3D, a weakly supervised method that requires only coarse clicks on the bird’s eye view (BEV) of the 3D point cloud, significantly reducing annotation costs. OC3D employs a two-stage strategy to generate box-level and mask-level pseudo-labels from these coarse clicks, achieving state-of-the-art performance on the KITTI and nuScenes datasets.
Related Work
LIDAR-based 3D Object Detection
Fully-supervised 3D object detection methods have been extensively studied, utilizing both one-stage and two-stage strategies to predict detection boxes directly from point clouds. Despite their success, these methods require fully annotated box-level annotations, which are costly to generate.
Label-efficient 3D Object Detection
Recent research has focused on reducing annotation costs through semi-supervised and sparsely-supervised methods. These approaches leverage a subset of annotated frames or rely on sparse bounding box annotations to train high-performing 3D object detectors. However, they still require some level of box-level annotations.
Learning From Click-level Annotation
Click-level annotation is a more labor-efficient strategy. Previous works have explored using click-level annotations for weakly supervised segmentation and 3D object detection. However, these methods often combine click-level annotations with box-level annotations, failing to achieve 3D object detection tasks using only click-level annotations.
Proposed Approach
Problem Definition
The task is to train a 3D object detector using only instance-level click annotations on the 2D BEV plane. The detector must predict full 3D bounding boxes, including coordinates, dimensions, and orientation. The approach involves generating mixed-granularity supervision for static and moving objects using Click2Box and Click2Mask strategies, followed by Mask2Box-enhanced self-training to refine the generated supervision.
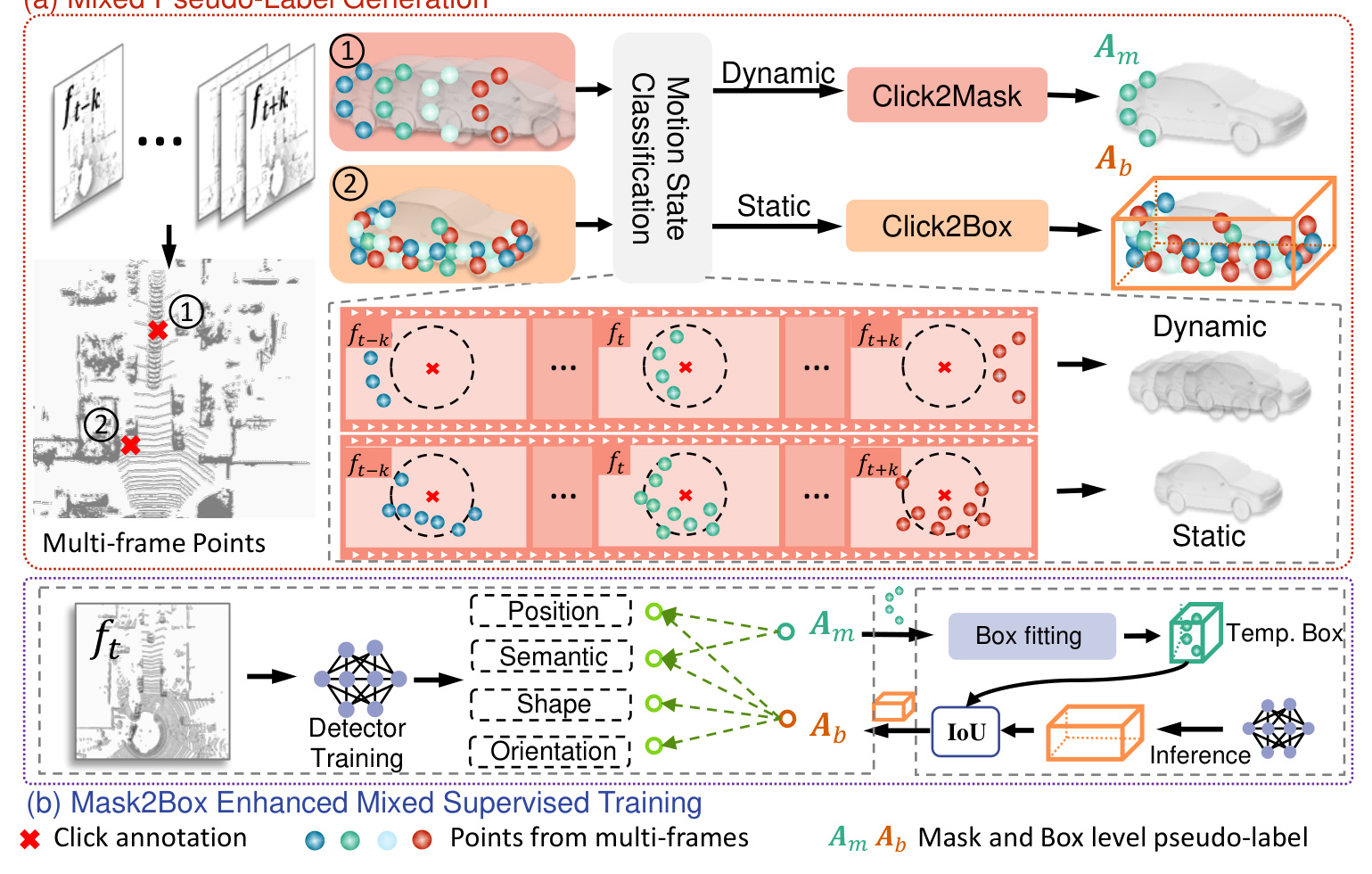
Mixed Pseudo-Label Generation
To estimate 3D bounding boxes from click annotations, temporal cues are used to enrich sparse point annotations by aggregating registered points across consecutive frames.
Motion State Classification for Clicked-instance
The motion state of instances is classified based on the persistence of points at clicked positions over a sequence of frames. Static instances exhibit continuous point distribution, while dynamic instances show transient point distribution.
Click2Box
For static objects, dense points from multiple frames are aggregated to fit high-quality bounding box pseudo-labels using the DBSCAN clustering algorithm.
Click2Mask
For dynamic objects, mask-level pseudo-labels are generated by extracting foreground points from single-frame point clouds using the DBSCAN clustering algorithm.
Mask2Box Enhanced Mixed Supervised Training
Mixed supervised training involves training the detection network with both box-level and mask-level pseudo-labels. The Mask2Box module iteratively upgrades mask-level pseudo-labels to box-level pseudo-labels using high-confidence predictions, improving detection accuracy.
Experiments
Datasets and Metrics
Experiments were conducted on the KITTI and nuScenes datasets. The KITTI dataset was divided into train and validation splits, with only coarse click annotations retained for training. The nuScenes dataset included coarse click annotations for all objects in the train split. Performance was evaluated using mean Average Precision (mAP) and nuScenes detection score (NDS).
Implementation
Coarse click annotations were simulated by applying perturbations to the BEV center of ground truth. Different neighborhood radii were set for different categories based on common human prior knowledge.
Baselines
OC3D was compared with state-of-the-art label-efficient methods using the VoxelRCNN and CenterPoint architectures. Multiple baselines were constructed using the Click2Box module to infer bounding box supervision from click annotations.
Results
KITTI Dataset
OC3D achieved comparable performance with other label-efficient methods, despite using a more lightweight annotation form. The proposed OC3D++ demonstrated consistent performance under sparse clicking conditions.


nuScenes Dataset
OC3D achieved performance comparable to fully supervised baseline methods on the nuScenes dataset, demonstrating outstanding performance on multi-class tasks. OC3D++ maintained robust performance under sparse coarse click annotations.

Ablation Study and Analysis
Effect of Mixed Supervised Training (MST) and Mask2Box Enhanced Training (MET)
The proposed MST and MET significantly improved detection accuracy by eliminating the adverse effects of dynamic low-quality bounding box pseudo-labels and upgrading mask-level pseudo-labels to box-level pseudo-labels.

Effects of Perturbation Factor δ and Weight Selection for λ
OC3D++ demonstrated robustness to coarse click perturbations, achieving satisfactory performance even with large disturbance ranges. Lower weights for ambiguous location predictions yielded better results, indicating that a single hint is sufficient for optimal detection performance.

Prediction Results and Quality of Pseudo-labels at Each Iteration
OC3D++ showed significant performance enhancement over different training iterations, with an overall stable upward trend in the quality of pseudo-labels.

Discussion and Conclusion
OC3D introduces an efficient annotation strategy called coarse click annotation for 3D object detection, significantly reducing annotation costs. The proposed method achieves commendable performance with purely click annotations and maintains outstanding performance under sparse clicking conditions. However, the rule-based pseudo-labels may not match the high-quality annotations produced by human annotators, leading to reduced performance under higher IoU thresholds.



