





Authors:
Valentinos Pariza、Mohammadreza Salehi、Gertjan Burghouts、Francesco Locatello、Yuki M. Asano
Paper:
https://arxiv.org/abs/2408.11054
NeCo: Enhancing DINOv2’s Spatial Representations with Patch Neighbor Consistency
Introduction
Dense self-supervised learning has made significant strides in training feature extractors to produce representations for every pixel or patch of an image without supervision. This advancement has notably improved unsupervised semantic segmentation, object-centric representation learning, and other dense downstream tasks. A recent approach by Balazevic et al. proposed solving semantic segmentation as a nearest-neighbor retrieval problem using spatial patch features. Inspired by this, the authors of the paper introduce NeCo (Patch Neighbor Consistency), a novel training loss that enforces patch-level nearest neighbor consistency across a student and teacher model. This method leverages differentiable sorting on top of pretrained representations like DINOv2, leading to superior performance across various models and datasets with only 19 hours of training on a single GPU.
Related Work
Dense Self-Supervised Learning
Dense self-supervised learning methods aim to generate categorizable representations at the pixel or patch level. Previous works have shown that image-level self-supervised methods do not necessarily produce expressive dense representations. Methods like CroC, Leopart, Timetuning, and Hummingbird have proposed various dense self-supervised losses to address this issue. CrIBo, for instance, enforces cross-image nearest neighbor consistency between image objects, achieving state-of-the-art results.
Unsupervised Object Segmentation
Several works target unsupervised object segmentation, often utilizing existing information in frozen pretrained backbones and training another model to solve semantic segmentation explicitly. For example, Seitzer et al. train a slot-attention encoder and decoder module to reconstruct DINO pretrained features, creating per-image object cluster maps.
Research Methodology
Patch Neighbor Consistency
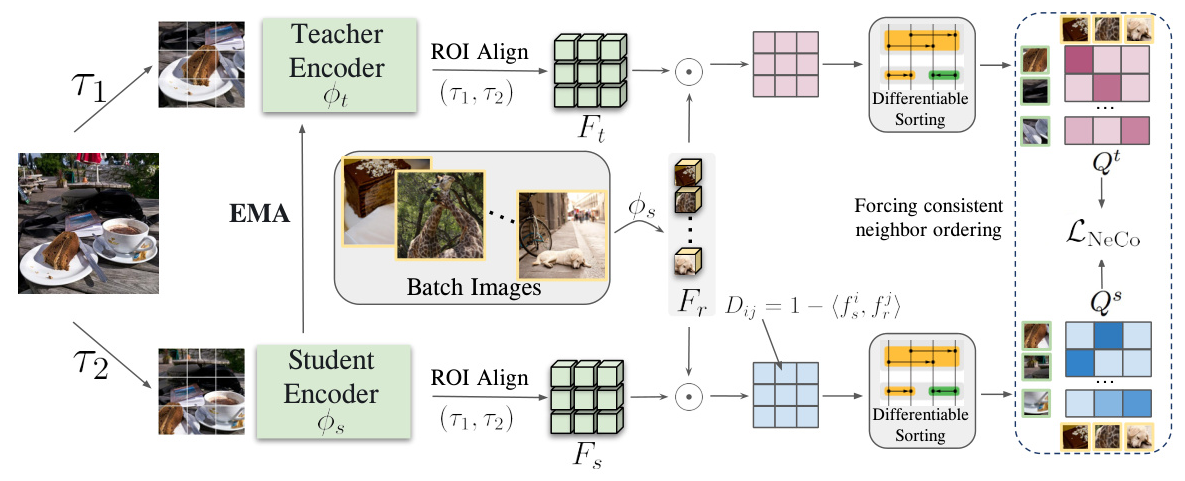
The goal of NeCo is to develop a feature space where patches representing the same object exhibit similar features, while patches representing different objects show distinct features. The method works by extracting dense features of the inputs, finding their pair-wise distances, and forcing consistency between the order of nearest neighbors within a batch across two views.
Feature Extraction and Alignment
Given an input image, two augmentations are applied to create two different views, which are then divided into separate patches. These patches are fed to a Vision Transformer (ViT) backbone in a teacher-student framework. The teacher’s weights are updated using the exponential moving average of the student’s weights. The features are aligned using ROI-Align, creating spatially aligned dense features for the teacher and student networks.
Pairwise Distance Computation
To identify the nearest neighbors of the patches, features from other images in the batch are extracted, and their distances with respect to the student and teacher features are computed using cosine similarities. These distance matrices are sorted in a differentiable manner to produce a loss that enforces a similar sorting across the two views.
Differentiable Sorting of Distances
Traditional sorting algorithms cannot propagate gradients due to non-differentiable operations. NeCo uses relaxed, differentiable versions of these operations, defining soft versions of element swapping. The final permutation matrix for the entire sequence is determined by the sorting algorithm employed, ensuring that the order of nearest neighbors is consistent between the student and teacher features.
Training Loss
The training loss enforces similarity on the order of nearest neighbors for each of the aligned patch features using the cross-entropy loss. The final training loss incorporates both directions for all the patches, ensuring robust nearest neighbor consistency.
Experimental Design
Setup
Benchmarked Methods
NeCo is compared against state-of-the-art dense self-supervised learning methods, including CrIBo, Hummingbird, TimeT, and Leopart. The performance of DINOv2 enhanced with registers (DINOv2R) is also included.
Training
Experiments are run on ViT-Small and ViT-Base with a patch size of 14. Various pretrained backbones are used, and models are post-pretrained for 25 COCO epochs on a single NVIDIA RTX A6000-46GB GPU, taking around 19 hours.
Evaluation
Evaluations discard the projection head and directly use the spatial tokens from the Vision Transformer backbone. Scores are reported as mean intersection over union (mIoU). Four types of evaluations are conducted: linear segmentation fine-tuning, end-to-end segmentation, clustering and overclustering semantic segmentation, and dense nearest neighbor retrieval.
Datasets
The model is trained on ImageNet-100, Pascal VOC12, and COCO for ablations, with COCO as the primary training dataset for state-of-the-art comparisons. Evaluations use the validation sets of Pascal VOC12, COCO, ADE20k, and Pascal Context.
Results and Analysis
Comparison to State-of-the-Art
Visual In-Context Learning Evaluation
NeCo outperforms prior state-of-the-art methods like CrIBo and DINOv2R on Pascal and ADE20k across different fractions, particularly in the data-efficiency regime. This improvement is due to NeCo’s explicit enforcement of patch-level nearest neighbor consistency, resulting in higher-quality patch-level representations.


Frozen Clustering-based Evaluations
NeCo surpasses state-of-the-art methods like CrIBo by 14.5% on average across various datasets and metrics. The method also outperforms other methods in clustering performance when K matches the number of ground truth objects.

Linear Semantic Segmentation Evaluation
NeCo surpasses CrIBo on all datasets by at least 10% and outperforms DINOv2R by 5% to 7%. These improvements demonstrate that patches representing the same object or object part have higher similarities in feature space compared to other methods.

Compatibility with Differently Pretrained Backbones
NeCo improves various self-supervised learning initializations by roughly 4% to 30% across different metrics and datasets. It even enhances the performance of methods specifically designed for dense tasks, like CrIBo, TimeT, and Leopart.

End-to-End Full-Finetuning Evaluation
NeCo demonstrates superior features, leading to better performance in downstream tasks, outperforming CrIBo by approximately 4%. Despite DINOv2R’s strong transfer results, NeCo surpasses it with only 19 GPU-hours of training on COCO.

Ablation Studies
Patch Selection Approach
Selecting patches from both foreground and background locations yields the best results, as scene-centric images often contain meaningful objects in the background.

Utilizing a Teacher
Employing a teacher network updated by exponential moving average significantly improves performance across all metrics by 8% to 20%.

Nearest Neighbor Selection Approach
Selecting patches across images consistently boosts performance by roughly 0.4% to 1% across different metrics, likely due to the higher diversity of patches involved.
Training Dataset
Training on multi-object datasets like COCO provides stronger learning signals, resulting in consistent improvements compared to simpler datasets like ImageNet-100.
Sorting Algorithm
NeCo demonstrates robust performance across different sorting approaches, achieving the best results with Bitonic sorting.
Overall Conclusion
NeCo introduces Patch Neighbor Consistency as a new method for dense post-pretraining of self-supervised backbones. By applying NeCo to various backbones, including the DINOv2-registers model, significant improvements are achieved in frozen clustering, semantic segmentation, and full finetuning, setting several new state-of-the-art performances. This method not only enhances the quality of dense feature encoders but also demonstrates the potential for reducing the carbon footprint of model training by leveraging pretrained models and requiring minimal compute for finetuning.


