





Authors:
Zunjie Xiao、Xiaoqing Zhang、Risa Higashita、Jiang Liu
Paper:
https://arxiv.org/abs/2408.08600
Introduction
Ophthalmic image segmentation is a crucial step in the diagnosis of ocular diseases. Traditional image processing algorithms, such as Canny edge detection, have been used for segmentation but often require complex preprocessing. With the advent of deep learning, Convolutional Neural Networks (CNNs) have shown significant progress in ophthalmic segmentation tasks. However, CNNs are limited in capturing long-range dependencies due to their local receptive fields.
Transformer architectures, such as ViTs, TransUNet, and UTNet, have been introduced to address these limitations by leveraging self-attention mechanisms. Despite their success, transformers come with substantial computational overhead. Recently, pure Multilayer Perceptron (MLP) models like the MLP-Mixer have demonstrated competitive performance in image classification without the need for complex self-attention mechanisms. Inspired by these advancements, we propose MM-UNet, a mixed MLP architecture tailored for ophthalmic image segmentation.
Method
Revisiting MLP-Mixer Mechanism
The MLP-Mixer architecture consists of three main components: the per-patch embedding layer, mixer layers, and the classification layer.
- Per-patch embedding layer: The input image is divided into non-overlapping patches, which are then projected into a hidden dimension using a shared fully connected layer.
- Mixer layers: These layers consist of channel-mixing MLPs and token-mixing MLPs. Channel-mixing MLPs facilitate interaction between channels, while token-mixing MLPs establish interactions between spatial patches.
- Classification layer: After several mixer layers, the final output undergoes global average pooling and a fully connected layer for classification.


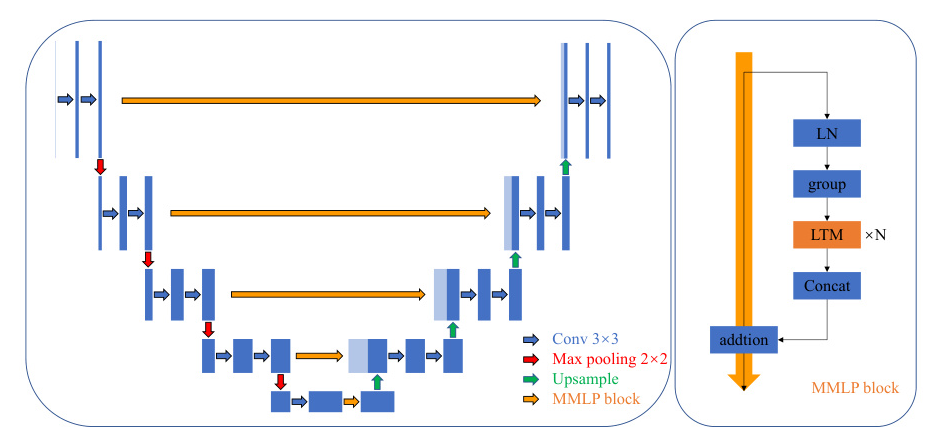
Multi-scale MLP Block
To address the loss of location information during token-mixing, we propose the Multi-Scale MLP (MMLP) block. This block divides the input into groups by channel and applies local token-mixing within each group. The process is as follows:
- Grouping: The input is divided into multiple groups by channel.
- Local Token-Mixing (LTM): Each group undergoes local token-mixing within defined blocks, preserving more positional information.
- Concatenation: The outputs from all groups are concatenated to form the final output.

Network Architecture
MM-UNet combines the strengths of CNNs and MLPs. The architecture retains the original encoder and decoder of UNet to preserve positional information while integrating the MMLP block to capture long-range dependencies. The specific settings for different levels of the network are detailed in Table 1.

Experiment
Dataset
We evaluated MM-UNet on two ophthalmic image datasets:
- AS-OCT Dataset: A private dataset collected using the CASIA2 Ophthalmic Imaging device, containing 1844 images from 284 subjects. The task is to segment the lens area into nucleus, cortex, and capsule.
- REFUGE2 Dataset: A public dataset from MICCAI 2019, containing 1200 fundus images for optic cup and optic disc segmentation.

Experiment Setup
The datasets were divided into training, validation, and testing subsets. All models were trained from scratch for 150 epochs using the SGD optimizer with a batch size of 16. The images were resized to 256×256, and cross-entropy loss was used for training. The performance was evaluated using the mean Intersection over Union (mIoU) metric.
Segmentation Results
MM-UNet outperformed state-of-the-art models on both datasets. In the AS-OCT dataset, MM-UNet achieved 98.2% accuracy and 92.64% mIoU, surpassing UNet by 1.2% mIoU with minimal parameter increase. In the REFUGE2 dataset, MM-UNet also demonstrated superior performance with fewer parameters.

Ablation Study
To verify the effectiveness of the MMLP block, we compared it with the global token-mixing MLP. The results showed that the LTM operator in the MMLP block improved both mIoU and accuracy compared to global token-mixing.

Conclusion
The MM-UNet architecture, integrating convolutional and MLP components, demonstrates significant potential in ophthalmic image segmentation. The proposed MMLP block effectively captures long-range dependencies while preserving positional information. Future work will explore extending this MLP-based approach to a broader range of applications.
This blog post provides a detailed overview of the MM-UNet architecture and its application in ophthalmic image segmentation. The illustrations and experimental results highlight the effectiveness of this mixed MLP model in improving segmentation performance.


