





Authors:
Haozhe Ma、Zhengding Luo、Thanh Vinh Vo、Kuankuan Sima、Tze-Yun Leong
Paper:
https://arxiv.org/abs/2408.10858
Introduction
Reinforcement learning (RL) has achieved remarkable success in various domains, including robotics, gaming, autonomous vehicles, signal processing, and large language models. However, environments with sparse and delayed rewards pose significant challenges, as the lack of immediate feedback hinders the agent’s ability to distinguish valuable states, leading to aimless exploration. Reward shaping (RS) has proven effective in addressing this challenge by providing additional dense and informative rewards.
In this context, multi-task reinforcement learning (MTRL) is gaining importance due to its ability to share and transfer knowledge across tasks. Integrating RS techniques into MTRL offers a promising direction to enhance the efficacy of multi-task system learning. This paper proposes a novel MTRL framework, the Centralized Reward Agent (CenRA), which integrates a centralized reward agent (CRA) and multiple distributed policy agents. The CRA functions as a knowledge pool, distilling knowledge from various tasks and distributing it to individual policy agents to improve learning efficiency.
Related Work
Knowledge Transfer Methods
Knowledge transfer methods in MTRL focus on identifying and transferring task-relevant features across diverse tasks. Policy distillation is a well-studied approach to extract and share task-specific behaviors or representations. Various works have built on this approach, such as:
- Distral: Distills a centroid policy from multiple task-policies.
- Actor-Mimic: Trains a single policy to mimic several expert policies from different tasks.
- Hierarchical Prioritized Experience Replay: Selects and learns multi-task experiences.
- Adaptation Mechanisms: Equalize the impact of each task in policy distillation.
Representation Sharing Methods
Representation sharing methods explore architectural solutions for reusing network modules or representing commonalities in MTRL. Examples include:
- Parameter Compositional Approach: Learns and shares a subspace of parameters.
- Soft Modularization: Learns foundational policies and utilizes a routing network to combine them.
- Dynamic Depth Routing: Adjusts the use of network modules in response to task difficulty.
- Attention Mechanisms: Capture task relationships and create composable representations.
Single-Policy Generalization Methods
Single-policy generalization methods aim to learn a single policy to solve multiple tasks simultaneously or continuously, enhancing the policy’s generalization capabilities. Model-free meta-learning techniques have been proposed to enhance multi-task generalization. Examples include:
- Sharing Network Structure: Allows an agent to learn multiple tasks concurrently.
- Confidence-Sharing Agent: Detects and defines shared regions between tasks.
- Transfer Learning Framework: Handles mismatches in state and action spaces.
Research Methodology
Knowledge Extraction and Sharing
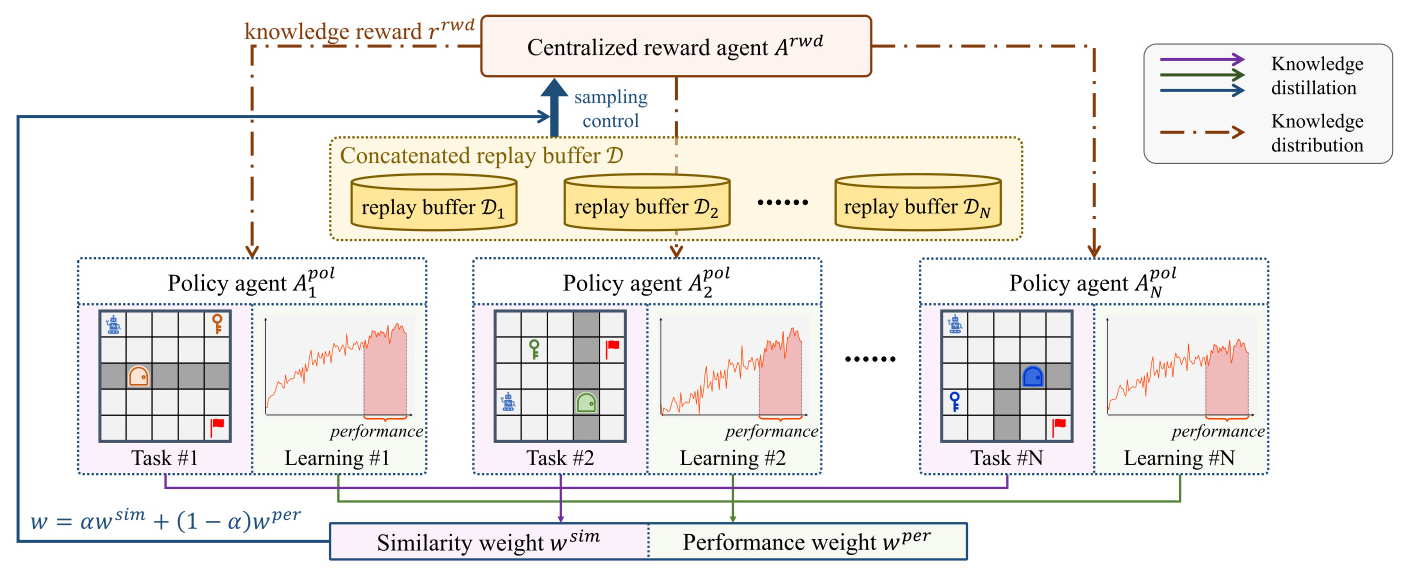
The CenRA framework consists of a centralized reward agent (CRA) and multiple policy agents. Each policy agent operates independently to complete its corresponding task, utilizing appropriate RL algorithms. The CRA extracts environment-relevant knowledge and distributes it to policy agents by generating additional dense rewards to support their original reward functions.
Centralized Reward Agent
The CRA is modeled as a self-contained RL agent, interacting with multiple policy agents and their respective tasks. The CRA’s policy generates continuous rewards given both an environmental state and a policy agent’s behavior. The CRA uses an off-policy actor-critic algorithm to optimize its reward-generating actor and value estimation critic.
Policy Agents with Knowledge Rewards
Each policy agent interacts with its specific environment and stores experiences in its replay buffer. Policy agents receive two types of rewards: environmental rewards and knowledge rewards from the CRA. The optimal policy for each agent is derived by maximizing the cumulative augmented reward.
Information Synchronization of Policy Agents
To maintain balanced knowledge extraction and distribution, an information synchronization mechanism is introduced. This mechanism considers task similarity and the real-time learning performance of policy agents. The final sampling weight combines similarity and performance weights to ensure balanced and effective knowledge extraction and learning.
Experimental Design
Experimental Environments
Experiments were conducted in three environments with multiple tasks: 2DMaze, 3DPickup, and MujocoCar. These environments include both discrete and continuous control problems, providing challenging sparse environmental rewards.


Comparative Evaluation in MTRL
The learning performance of CenRA was evaluated in the MTRL context, configuring each environment with four different tasks. CenRA was benchmarked against several state-of-the-art baselines, including DQN, ReLara, PiCor, and MCAL. Multiple instances with different random seeds were trained for each task to report the average data.

Knowledge Transfer to New Tasks
The ability of the CRA to transfer learned knowledge to new tasks was assessed. The CRA model trained on the four tasks was used to initiate a new policy agent for a newly designed task. Two scenarios were explored: one where the CRA continues to optimize while cooperating with the new policy agent, and another where only the policy agent is trained without further updates to the CRA.

Effect of Sampling Weight
Experiments were conducted to understand the effects of the information synchronization mechanism. The full CenRA model was compared against three variants: without the similarity weight, without the performance weight, and without the entire sampling weight.

Results and Analysis
Comparative Evaluation in MTRL
CenRA consistently outperformed the baselines in terms of learning efficiency, faster convergence, stability, and robustness. CenRA maintained a well-balanced performance across different tasks, ensuring no single task’s performance was disproportionately high at the expense of others. The centralized reward agent effectively enhanced knowledge sharing among tasks, improving the learning efficiency of individual tasks.
Knowledge Transfer to New Tasks
CenRA with further learning achieved rapid convergence due to the CRA’s retention of previously acquired knowledge and its ability to quickly adapt to new tasks. Even without additional training, CenRA outperformed ReLara and the backbone algorithms. The CRA stored environment-relevant knowledge and transferred it to other policy agents, significantly accelerating the learning process.
Effect of Sampling Weight
The absence of sampling weight led to unbalanced learning outcomes, observed by increased variance in episodic returns across tasks. Both similarity and performance weights were essential for the information synchronization mechanism, with the performance weight having a more significant effect.
Overall Conclusion
The CenRA framework innovatively integrates reward shaping into MTRL, effectively addressing the sparse-reward challenge and enhancing learning efficiency. The CRA functions as a knowledge pool, distilling and distributing valuable information across multiple tasks. The information synchronization mechanism ensures balanced knowledge distribution, leading to optimal system-wide performance. Experiments demonstrated the robustness and superior performance of CenRA in both multi-task learning and new task adaptation.
Future improvements could explore preprocessing techniques to adapt the framework for varying state and action spaces, and a more flexible approach to balance similarity and performance weights. Additionally, a better mechanism for trade-off may be needed to avoid limiting the upper bound of top-performing tasks.



