





Authors:
Paper:
https://arxiv.org/abs/2408.10517
Introduction
Background
Offline reinforcement learning (RL) has been a significant area of research due to its potential to learn optimal policies from pre-collected datasets without additional environment interactions. This is particularly crucial in scenarios where interactions are costly or risky. Return-Conditioned Transformer Decision Models (RCTDM) have shown promise in enhancing transformer performance in offline RL by using returns-to-go instead of rewards in the input sequence. However, RCTDM faces challenges in learning optimal policies from limited suboptimal trajectories.
Problem Statement
The primary challenges with using transformers as decision models in offline RL are:
1. Handling Trajectory Data: Transformers, originally designed for language models, struggle with trajectory data comprising status information of locomotive objects or visual data.
2. Learning Suboptimal Policies: Due to the limited distribution of training data, transformers tend to learn suboptimal policies.
To address these challenges, the study introduces Decision MetaMamba (DMM), a model that employs an input token mixer to extract patterns from short sequences and uses a State Space Model (SSM) to selectively combine information from relatively distant sequences.
Related Work
Offline Reinforcement Learning
Offline RL involves learning from a pre-collected dataset without additional environment interactions. Key challenges include distribution shift and extrapolation error. Various approaches have been proposed to mitigate these issues:
– Value-based Behavioral Regularization: Techniques like BCQ, CQL, and IQL constrain the learned policy to stay close to the behavior policy that generated the dataset.
– Imitation Learning: Aims to imitate the behavior policy by training on collected or desired trajectories.
– Trajectory Optimization: Models joint state-action distribution over complete trajectories to reduce out-of-distribution action selection.
– Model-based Approaches: Use learned models of the environment to generate synthetic data, augmenting the offline dataset.
Return-Conditioned Decision Transformers
Decision transformers and their variants use returns-to-go inputs to learn optimal policies from suboptimal trajectories. These models leverage hindsight information to provide intuition on what should have been done differently. However, they often revert to suboptimal outputs due to the influence of sequential inputs like state and action information.
Metaformer
Metaformer is a framework designed to enhance transformer performance in vision tasks by abstracting the token mixer. PoolFormer, a model within Metaformer, replaces the self-attention token mixer with pooling layers, achieving superior results with fewer parameters.
State Space Model
SSMs, originally used in control engineering, have been adapted for deep learning to map dynamic systems using state variables. Mamba, a model based on SSM, introduced modifications to achieve content awareness and parallelization, improving performance in language tasks.
Research Methodology
Decision MetaMamba (DMM)
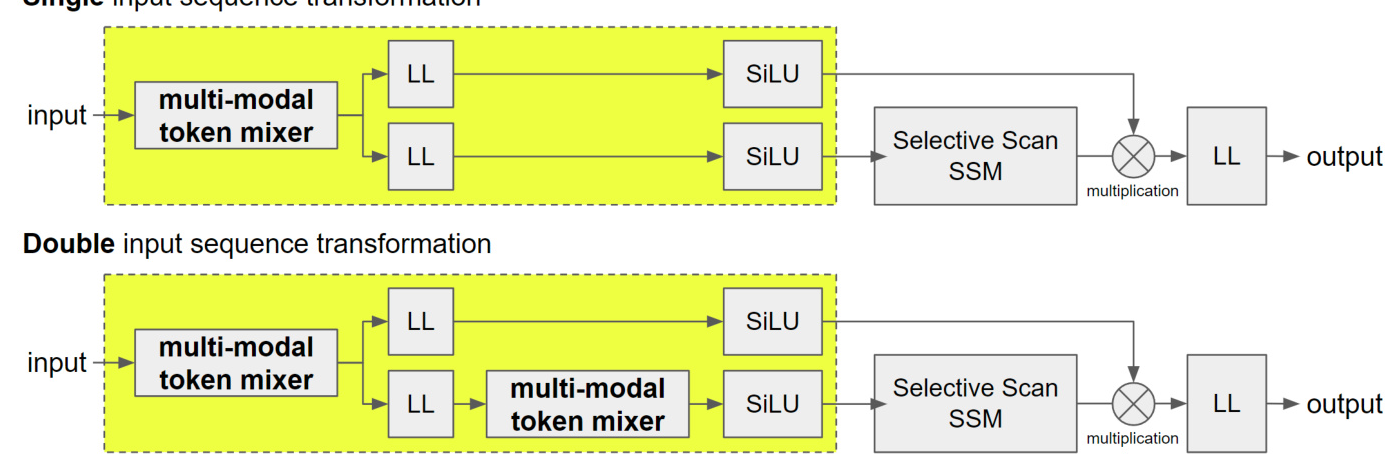
DMM modifies the input layer of Mamba, a sequence model based on SSM, to infer better actions. The original Mamba structure uses a causal 1D-Convolution layer for input embeddings. DMM replaces this with a Multi-modal layer using three different convolution filters or linear layers, each corresponding to states, actions, and returns-to-go (RTGs) modes.
Multi-Modal Token Mixer
DMM employs two types of Multi-Modal Token Mixers (MMTMs):
1. Multi-Modal 1D-Convolution Layer: Integrates neighboring embeddings within a window size using filters across channels of the hidden dimension.
2. Multi-Modal Linear Layer: Concatenates consecutive sequence vectors of window size in the time domain and transforms them back to the hidden state dimension.
These token mixers are positioned at the very beginning of the input layer of the SSM, ensuring that all inputs receive an integrated input that considers short sequences.


Experimental Design
Datasets
The performance of DMM was evaluated using pre-collected datasets from the D4RL MuJoCo, AntMaze, and Atari domains. These datasets provide diverse environments for testing the model’s ability to handle different types of trajectory data.
Model Architecture
DMM is built upon the Mamba architecture, divided into three main components:
1. Input Layer: Transforms the input state using a combination of linear layers, 1D-convolution layers, and activation functions.
2. SSM Layer: Performs content-aware reasoning while enabling fast, parallel operations through a hardware-aware algorithm.
3. Output Projection: Linearly transforms the output of the SSM.

Training and Evaluation
During training, each sequence of length, including RTG, state, and action, is embedded into vectors of the same size through an input embedding layer. The output from passing through MetaMamba blocks is transformed into an action-dimension vector, resulting in the predicted action. The loss is computed between the predicted actions and the true actions across all sequence lengths.
During evaluation, DMM interacts with the environment in real-time to infer the action token, with the initial RTG set higher than the actual return of the trajectory.
Results and Analysis
Performance Evaluation
The performance of DMM was compared with seven baseline models across various environments. The results indicated enhanced or comparable performance across environments, demonstrating the potential of models designed to integrate both proximate and distant sequences.

Analysis
The results highlighted the importance of considering multi-modality in the process of interpreting sequences and selecting actions. The performance varied depending on whether the multi-modal layer was implemented as a 1D convolution layer or a linear layer, indicating that adjusting the input layer according to the domain can lead to performance improvements.

Overall Conclusion
The study introduces Decision MetaMamba (DMM), a sequential decision-making model that employs the selective scan State-Space Model (SSM) with a modified input layer. By utilizing multi-modal input layers, DMM achieves performance improvements while using fewer parameters compared to existing models. The model’s abstracted structure allows for the adoption of input layers with different characteristics depending on the dataset, achieving optimal results.
The ongoing advancements in SSMs suggest that this study can pave the way for improved performance in offline RL decision models through the use of advanced SSMs.

Code:
https://github.com/too-z/decision-metamamba


