





Authors:
Yili Li、Jing Yu、Keke Gai、Gang Xiong
Paper:
https://arxiv.org/abs/2408.07989
Introduction
Knowledge-based visual question answering (VQA) is a challenging task that requires integrating visual content with external knowledge to answer questions accurately. Traditional methods often focus on modeling inter-modal and intra-modal correlations, which can lead to complex multimodal clues being entangled in implicit embeddings, thus lacking interpretability and generalization ability. This paper introduces Independent Inference Units (IIU) for fine-grained multimodal reasoning, aiming to decompose intra-modal information through functionally independent units. By reusing each processing unit, the model’s generalization ability to handle diverse data is enhanced.
Related Work
Visual Question Answering
The VQA task requires an agent to answer questions based on visual content, necessitating the understanding and processing of multimodal information. Previous approaches have applied attention mechanisms to VQA tasks to reduce redundant information. Some methods represent information through graph structures and perform reasoning on these graphs. For instance, scene graphs describe objects and relationships in images, while fact graphs represent image-question-entity embeddings. However, these methods often introduce redundant information and lack fine-grained reasoning methods to extract complex clues within the modal, reducing interpretability.
Separate Recurrent Models
Recurrent models like GRU are commonly used in multi-step reasoning for VQA tasks. IndRNN and RIM are examples of separate recurrent models where each unit operates independently, with sparse inter-unit communication via an attention mechanism. Building on these concepts, the proposed model’s inference units reason independently while gathering complementary information.
Methodology
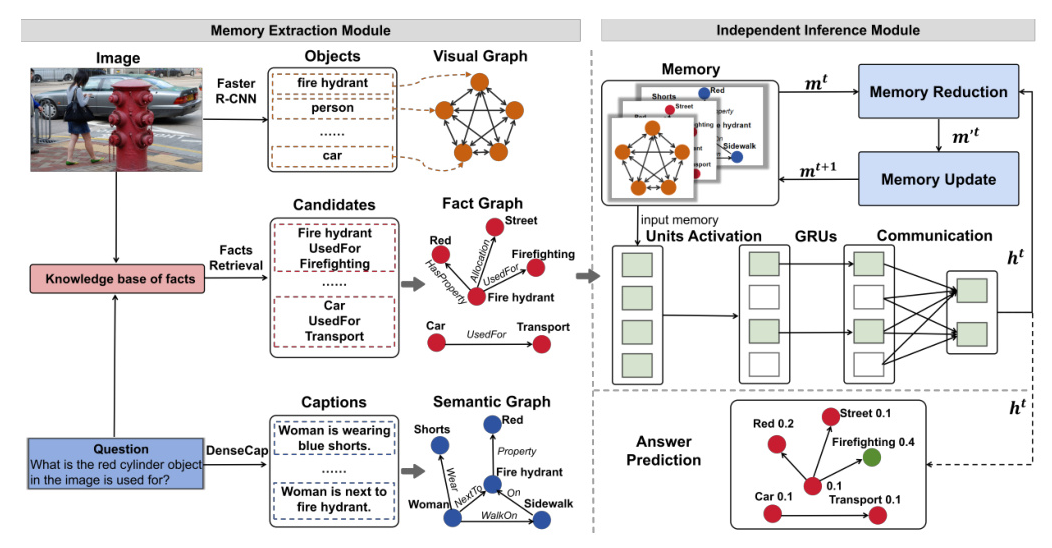
The proposed model aims to predict answers by reasoning with external knowledge to construct memory graphs. The model consists of two main modules: Memory Extraction Module and Independent Inference Module.
Multi-Modal Graph Construction
The model utilizes a Multi-modal Heterogeneous Graph to represent question-image pairs. This graph includes three layers: visual graph, semantic graph, and fact graph. The visual graph nodes are objects extracted by Faster R-CNN, with edges representing spatial relationships. The semantic graph is constructed using dense captions and a semantic graph parsing model, where nodes represent names or attributes and edges represent relationships. The fact graph nodes denote entities in the supporting-fact set, represented by GloVe embeddings, with edges denoting relationships between entities.
Independent Units Inference
The Independent Units Inference module is the core of the model, consisting of three parts: Units Activation, Internal Dynamics, and Communication.
Units Activation
This module dynamically selects the most relevant unit to the input. The hidden state of each unit is initialized with the question embedding. At each reasoning step, the top-ka units are activated based on the attention score of the hidden state and input.
Internal Dynamics of Units
Each activated unit processes the input memory independently using a Gate Recurrent Unit (GRU) to generate the intermediate state of units.
Communication
While each unit works independently, complementary information between units is obtained using attention-like methods to update the inference state.
Question-guided Memory Update
Before the next reasoning step, the model maintains memory information based on the current inference state. This module reduces redundant information and updates memory representations based on the question status.
Answer Prediction and Training
The final answer prediction is achieved by updating the representation with the last inference state via a gate mechanism. The concepts are fed into a binary classification to predict answers, with a weighted binary cross-entropy loss used to handle imbalanced training data.
Experiment
Implementation Details
The model is trained using the Adam optimizer for 30 epochs with a batch size of 32. The warm-up strategy is applied for the first 2 epochs. The model’s parameter size is 74M, with an average training time of 0.4 hours per epoch on a single V100-32GB GPU.
Dataset
The model is evaluated on the Outside Knowledge VQA (OK-VQA) dataset and the FVQA dataset. The OK-VQA dataset contains 14,031 images and 14,055 questions across 10 categories. The FVQA dataset consists of 2,190 images, 5,286 questions, and a knowledge base of 193,449 facts.
Comparison with State-of-the-Art Methods
The IIU model outperforms other low-resource multimodal inference models on the OK-VQA dataset, achieving the highest overall accuracy. It also surpasses some basic pre-trained models in multimodal learning. On the FVQA dataset, the IIU model also demonstrates superior performance compared to state-of-the-art models without pre-training.


Ablation Study
The ablation study evaluates the impact of each module on the model’s accuracy. Removing the Independent Units or Units Communication significantly reduces performance, highlighting the importance of these components. The Memory Update module also contributes to maintaining memory information and updating representations based on the inference state.

Interpretability and Visualization
The model’s interpretability is demonstrated by visualizing the units activated when processing different modalities. Different modalities activate different units, showing that the IIU can decompose input information and handle each type of information differently.

Model Stability
The model’s stability is tested by adding redundant information during reasoning. The IIU can identify and process redundant information separately, demonstrating its robustness and generalization ability.

Conclusion
The Independent Inference Units (IIU) model for knowledge-based visual question answering effectively disentangles reasoning information from the functional level, improving performance and interpretability. The Memory Update module helps maintain semantic information and resist noise. The IIU model achieves state-of-the-art results and surpasses basic pre-trained multimodal models. Future work will explore dynamic selection of reasoning steps.
Acknowledgments
This work was supported by the Central Guidance for Local Special Project (Grant No. Z231100005923044) and the Climbing Plan Project (Grant No. E3Z0261).
Code:
https://github.com/lilidamowang/iiu


