





Authors:
Paper:
https://arxiv.org/abs/2408.10455
Enhancing Rule Learning in Language Agents: The IDEA Approach
Introduction
Background and Problem Statement
The ability to discern and apply rules is a cornerstone of human intelligence. Humans identify patterns, formulate hypotheses, and refine them through interaction with their environment. This process, often involving abduction, deduction, and induction, is crucial for problem-solving and understanding the world. However, while large language models (LLMs) have shown proficiency in isolated reasoning tasks, their holistic rule-learning abilities in interactive environments remain underexplored.
To address this gap, researchers from the University of Texas at Dallas have introduced RULEARN, a novel benchmark designed to evaluate the rule-learning capabilities of LLMs in interactive settings. This benchmark simulates real-world scenarios where agents must gather observations, discern patterns, and solve problems without prior knowledge of the underlying rules.
The IDEA Agent
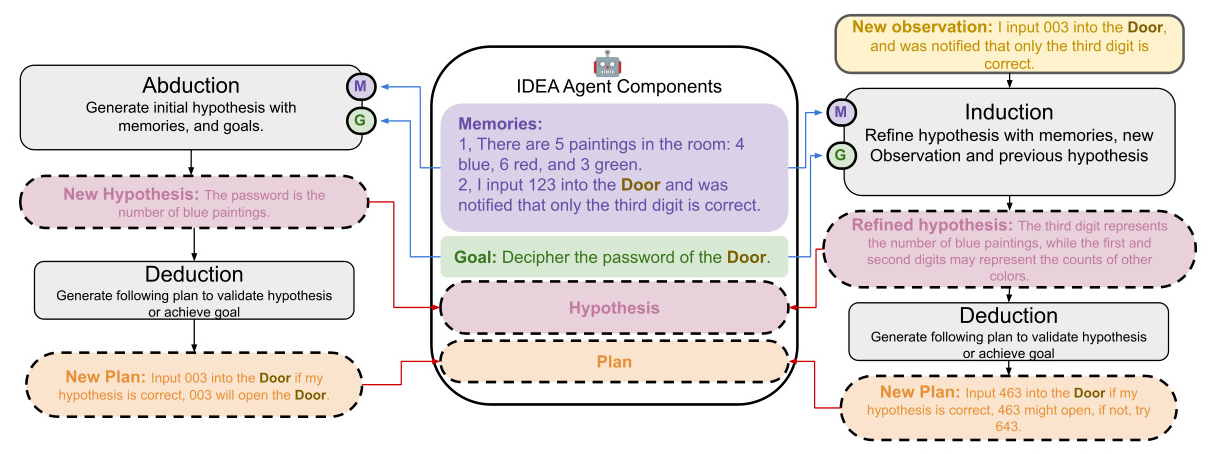
To enhance the rule-learning capabilities of LLMs within the RULEARN benchmark, the researchers propose the IDEA agent. This agent integrates Induction, Deduction, and Abduction processes, mimicking human-like reasoning. The IDEA agent generates hypotheses through abduction, tests them via deduction, and refines them based on induction feedback. This structured reasoning sequence enables the agent to dynamically establish and apply rules, significantly improving performance in interactive environments.
Related Work
Isolated Studies
Previous studies have often evaluated abduction, deduction, and induction separately. For instance, Bowen et al. (2024) focused on rule learning and leveraging in an ablation manner, while Wang et al. (2023) tested abduction capabilities using executable code. Saparov et al. (2024) employed first-order logic for deduction evaluations. These isolated evaluations do not fully capture the complexities of real-world rule learning.
Comprehensive Studies
Some studies have attempted to evaluate the entire rule-learning loop but still exhibit significant limitations. Xu et al. (2024) used a novel open-world environment but relied on distinct agents for different reasoning phases, missing the iterative dynamic essential in reasoning processes. Liu et al. (2024) evaluated abduction, induction, and deduction within a holistic framework but used a fixed sample dataset, lacking the crucial component of actively gathering relevant evidence.
The Integrated Approach
In contrast, the RULEARN benchmark integrates the evaluation of abduction, deduction, and induction in a cohesive framework. Agents interact dynamically with the environment under the guidance of current hypotheses, allowing for effective evidence gathering and comprehensive reasoning. This approach addresses the shortcomings of previous studies and enhances the real-world applicability of the findings.
Research Methodology
The RULEARN Benchmark
RULEARN comprises three types of environments designed to evaluate the rule-learning capabilities of language agents:
- Function Operator: Agents determine the coefficients of a set of functions based on limited information.
- Room Escape: Agents decipher a passcode by discovering how objects in a room collectively infer the code.
- Reactor: Agents synthesize a target string using reactors governed by distinct rules.
In each environment, agents interact with objects, gather observations, and refine their hypotheses through iterative exploration.
The IDEA Agent
The IDEA agent employs a reasoning framework involving abduction, deduction, and induction:
- Abduction: Generates initial hypotheses based on current observations.
- Deduction: Devises and executes plans to achieve objectives or validate hypotheses.
- Induction: Refines hypotheses using the latest observations, making them more accurate and robust.
This iterative process allows the IDEA agent to dynamically adapt and improve its problem-solving strategies based on continuous feedback from the environment.
Experimental Design
Evaluation Settings
The researchers evaluated five popular LLMs (GPT-3.5-turbo, GPT-4o, Gemma-7B, Llama3-7B, and Llama3-70B) using the RULEARN benchmark. They compared the performance of the IDEA agent against two variants:
- Baseline Agent: Lacks abductive/inductive actions, relying solely on historical observations.
- Deduction-Only Setting: Provides ground truth rules to test deductive reasoning abilities.
Each variant was tested on 60 puzzles (20 per environment type) across five trials, resulting in 300 puzzles per variant. The temperature of the LLMs was set to 1, and the maximum steps per puzzle were limited to 15.
Performance Metrics
The researchers calculated the Wilson Confidence Interval for each model’s success rate across different variants. They also analyzed the average number of repeated actions per puzzle and the efficiency of hypothesis generation and refinement.
Results and Analysis
Main Results
The results indicate that the IDEA agent significantly improves rule-learning performance compared to the baseline:
- Deduction-Only Setting: GPT-4o achieved the highest success rate, demonstrating superior deductive abilities. However, even advanced models struggled with complex scenarios, highlighting the challenges of rule-learning tasks in unfamiliar environments.
- Baseline Agent: GPT-4o continued to outperform other models, but the success rate declined significantly in Room Escape puzzles due to the tendency of LLMs to hallucinate when faced with fictitious rules.
- IDEA Agent: The implementation of the IDEA agent led to an approximate 10% increase in success rates for Llama3-70B, GPT-3.5, and GPT-4o. This improvement demonstrates the effectiveness of incorporating an abduction reasoning loop.
Analysis
The researchers observed several persistent challenges:
- Efficient Exploration: LLM agents often repeated previous actions, failing to explore new ones. The IDEA agent effectively reduced this tendency, improving exploratory behavior.
- Hypothesis Generation: LLMs struggled to generate reliable hypotheses, especially in environments with complex rules.
- Hypothesis Refinement: LLMs were less capable of refining hypotheses based on new observations, particularly in Reactor puzzles.
Solving Speed
The IDEA agent significantly increased the cumulative number of puzzles solved at each interaction step, especially in the early stages of exploration. This efficiency is crucial for solving rule-learning tasks that require large amounts of context at each step.
Overall Conclusion
The RULEARN benchmark and the IDEA agent represent significant advancements in evaluating and enhancing the rule-learning capabilities of language agents in interactive environments. The IDEA agent’s integration of abduction, deduction, and induction processes mimics human-like reasoning, leading to substantial improvements in performance.
Despite these advancements, several challenges persist, including the generation of valid hypotheses, the avoidance of repetitive actions, and the adaptation of strategies when faced with new information. The RULEARN benchmark offers a valuable platform for future research into developing language agents capable of human-like rule-learning in novel environments.
By addressing these challenges, researchers can further enhance the capabilities of language agents, bringing them closer to human-like intelligence and problem-solving abilities.
Illustrations:











