





Authors:
Kazi Hasan Ibn Arif、JinYi Yoon、Dimitrios S. Nikolopoulos、Hans Vandierendonck、Deepu John、Bo Ji
Paper:
https://arxiv.org/abs/2408.10945
Introduction
Vision-Language Models (VLMs) have become essential tools in multimodal tasks, leveraging both visual and textual data to enhance accuracy. However, high-resolution VLMs, which encode detailed image information, often generate an excessive number of visual tokens. This token surplus poses significant computational challenges, especially in resource-constrained environments with limited GPU capabilities. To address this issue, the paper introduces High-Resolution Early Dropping (HiRED), a token-dropping scheme designed to operate within a fixed token budget before the Large Language Model (LLM) stage. HiRED aims to maintain superior accuracy while significantly improving computational efficiency.
Related Work
Lightweight Architecture
Traditional methods like LLaVA-Phi-2.7B, TinyLLaVA-3.1B, and MobileVLM-3B aim to downsize VLMs but often sacrifice reasoning abilities due to reduced parameters. Techniques such as model quantization and weight pruning reduce resource demands but do not address the issue of excessive visual tokens. These methods typically require training from scratch or fine-tuning, making them less adaptable in a plug-and-play manner.
Sparse Attention Computation in LLM
Methods like FastV and FlexAttention aim to skip attention computation for less important visual tokens during the LLM decoding phase. However, these methods still process many visual tokens in the initial layers, resulting in inefficiencies in terms of latency and memory compared to early-dropping methods.
Early Dropping of Visual Tokens
Early-dropping methods like TokenCorrCompressor, PruMerge, and PruMerge+ drop visual tokens from the image encoding stage before feeding them to the LLM backbone. However, these methods either focus on specific tasks or lack control over the number of visual tokens within the memory budget, which is essential in resource-constrained environments.
Research Methodology
Key Insights
- Sparse Visual Tokens with High Attention Scores: Despite the large number of visual tokens, only a small subset is important in the LLMs generation phase, suggesting an opportunity to drop less important tokens without sacrificing accuracy.
- Various Importance of Sub-images: The variation in the visual content weights of image partitions suggests that some partitions may allow more token dropping than others.
CLS Attention-Guided Token Dropping
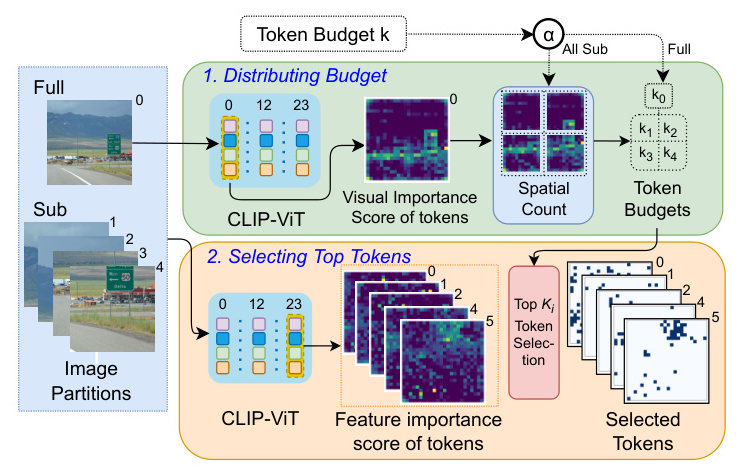
The paper leverages the properties of Vision Transformers (ViTs) to design an early-dropping strategy based on the importance of image partitions. ViTs split the image into fixed non-overlapping patches and prepend a CLS token to learn features from these patches using Multihead Self-Attention. The attention between the CLS token and patch tokens indicates the relevance of each patch to the overall image features.
Experimental Design
Token Budget Distribution
The distribution of a given token budget between the image partitions is crucial to ensure the best utilization. The paper introduces a hyperparameter α to determine the token budget for the full image. The remaining token budget is allocated to the sub-images based on their visual content scores, calculated from the CLS attention of an initial layer.
Token Dropping
The token-dropping strategy aims to retain tokens that carry most of the image features. The feature importance score is calculated by aggregating the CLS attention across heads in one of the final layers. Tokens with the highest feature importance scores are selected, and the rest are dropped within their partition budgets.
Results and Analysis
End-to-End Accuracy
HiRED achieves nearly the same accuracy as full execution for visual question-answering tasks with a 20% token budget. It maintains comparable accuracy for fine-grained transcription tasks with a 40% token budget. HiRED outperforms baselines like PruMerge and PruMerge+ in terms of accuracy, especially in transcription tasks.


Inference Efficiency
HiRED significantly improves inference efficiency. With a 20% token budget, it increases throughput by 4.7×, reduces time to first token by 15 seconds, and saves 2.3 GB of GPU memory. HiRED maintains a consistent number of visual tokens under a fixed token budget, proving highly effective under strict resource constraints.

Ablation Study
The ablation study evaluates the effectiveness of HiRED’s design choices. The study confirms that the final ViT layer’s CLS attention map and head aggregation strategy significantly impact accuracy. The budget distribution component is crucial for VLMs with dynamic image partitioning, with balanced distribution yielding better results.

Overall Conclusion
HiRED addresses the critical challenge of efficient high-resolution VLM inference in resource-constrained environments by strategically dropping visual tokens within a given token budget. The framework effectively distributes the token budget among image partitions, selects the most important visual tokens, and drops the rest before the LLM decoding phase. HiRED substantially improves inference throughput, reduces latency, and saves GPU memory while maintaining superior accuracy across diverse multimodal tasks. This work paves the way for future research into optimizing VLMs for more efficient and scalable performance in resource-constrained environments.
Code:
https://github.com/hasanar1f/hired


