





Authors:
Xiao Han、Zijian Zhang、Xiangyu Zhao、Guojiang Shen、Xiangjie Kong、Xuetao Wei、Liqiang Nie、Jieping Ye
Paper:
https://arxiv.org/abs/2408.10286
Introduction
The rapid growth of online ride-hailing services has revolutionized urban transportation, making vehicle dispatching a critical component in enhancing travel quality. However, existing vehicle dispatch systems face significant challenges due to the complexities of urban traffic dynamics, such as unpredictable traffic conditions, diverse driver behaviors, and fluctuating supply and demand patterns. These challenges often result in travel difficulties for passengers in certain areas and idle drivers in others, leading to a decline in the overall quality of urban transportation services.
To address these issues, the paper introduces GARLIC (GPT-Augmented Reinforcement Learning with Intelligent Control), a novel framework designed to optimize vehicle dispatching. GARLIC leverages multiview graphs to capture hierarchical traffic states and employs a dynamic reward function that accounts for individual driving behaviors. Additionally, it integrates a GPT model trained with a custom loss function to enable high-precision predictions and optimize dispatching policies in real-world scenarios.
Related Work
Vehicle dispatching has been extensively studied, with many approaches treating it as a multi-agent sequential decision-making task. Traditional methods often rely on Markov decision processes and reinforcement learning (RL) techniques to optimize dispatching policies. However, these methods face challenges in capturing the complex interplay between local traffic states and global spatiotemporal correlations.
Recent advancements in multi-agent reinforcement learning (MARL) have shown promise in addressing these challenges. However, vehicle dispatching presents unique difficulties due to the limited access of each vehicle to only its immediate environmental states. This necessitates the use of multi-hop vehicle-to-vehicle (V2V) communication to acquire more extensive traffic flow information, which can significantly increase communication latency.
Moreover, accurate vehicle dispatching requires nuanced modeling of driving behaviors, which reflect individual driver preferences and significantly influence dispatching outcomes. Existing methods often overlook this aspect, leading to suboptimal dispatching policies.
Research Methodology
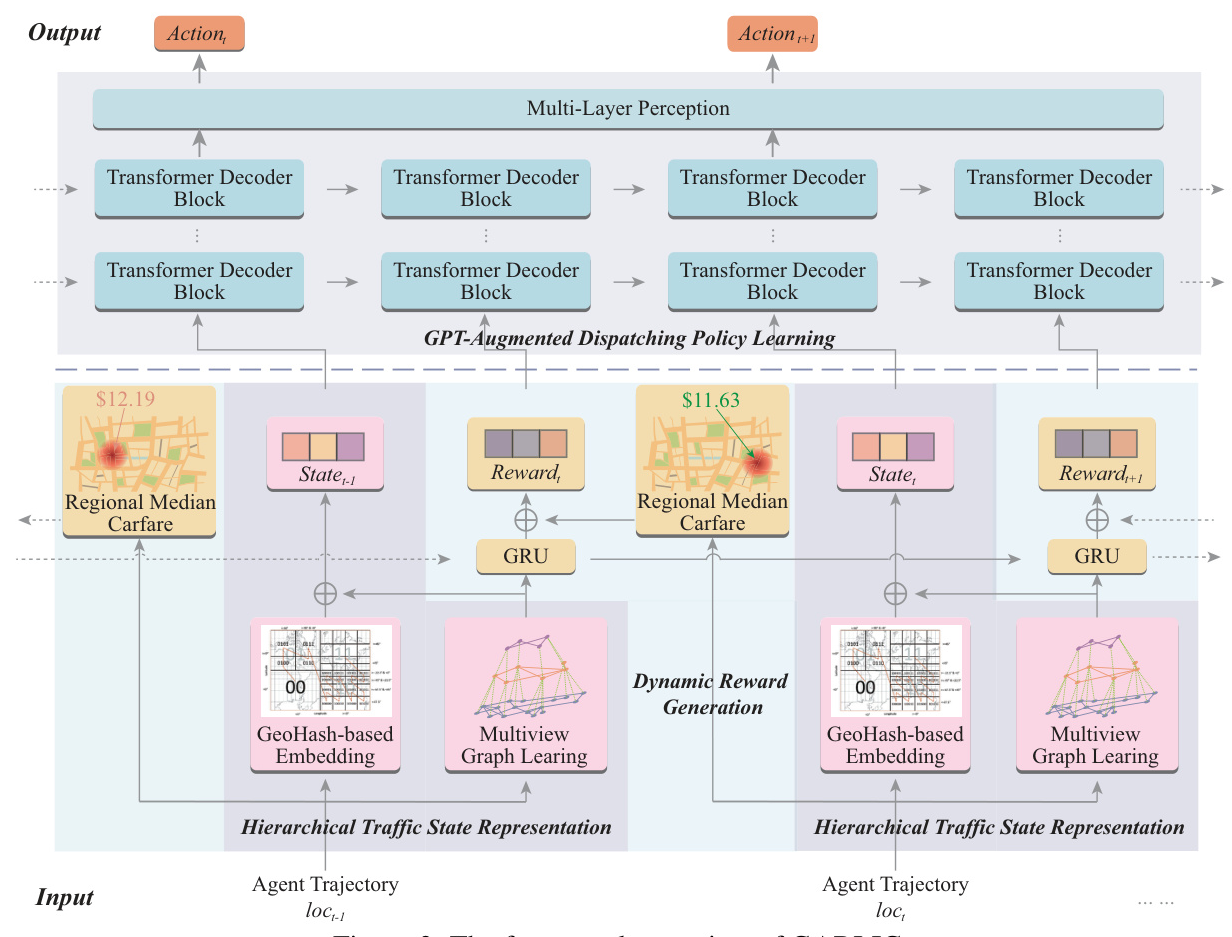
The proposed GARLIC framework combines hierarchical traffic state representation, dynamic reward generation, and GPT-augmented dispatching policy learning to address the core challenges in vehicle dispatching.
Hierarchical Traffic State Representation
GARLIC employs a multiview Graph Convolutional Network (GCN) to represent hierarchical traffic states by integrating traffic information gathered by various vehicles at different levels of granularity. This approach ensures a comprehensive representation of real-time traffic conditions.
Dynamic Reward Generation
To model driving behaviors, GARLIC uses a Gated Recurrent Unit (GRU)-based Recurrent Neural Network (RNN) to generate dynamic rewards. These rewards are weighted by the regional median carfare, ensuring that the reward system reflects both temporal and spatial nuances of driver behavior.
GPT-Augmented Dispatching Policy Learning
The training of the MARL-based vehicle dispatching task is framed as a supervised learning process. A GPT-augmented model is employed to produce high-precision actions for vehicle dispatching by analyzing time-ordered states and rewards.
Experimental Design
Dataset and Metrics
The experiments were conducted using two real-world datasets: one from Manhattan, New York City, USA, and the other from Hangzhou, Zhejiang Province, China. The performance of GARLIC was evaluated using the Euclidean distance metric (Error) to assess the discrepancy between predicted actions and actual driving intentions, and the empty-loaded rate metric to measure the efficiency of the car-hailing service.
Baselines
GARLIC was compared with several baseline methods, including both online and offline RL methods. The comparison aimed to demonstrate the effectiveness and efficiency of GARLIC in optimizing vehicle dispatching policies.
Implementation Details
The experiments were simulated on the open-source software SUMO and deployed on a Linux server with high computational resources. The correlation and influence between vehicles were limited to adjacent regions to avoid network congestion, and the waiting time for V2V multi-hop messages was capped at 1 second.
Results and Analysis
Overall Performance
GARLIC significantly reduced the error compared to other baselines, primarily due to its effective loss function for guiding the model during training. It also achieved one of the best performances in terms of the empty-loaded rate, demonstrating its ability to find optimal dispatching strategies while considering driver behavior.
Ablation Study
The ablation study highlighted the effectiveness of multiview graph learning and the influence of driving behavior on dispatching outcomes. The results indicated that multiview graph-based learning methods were more efficient and accurate than single-view graph-based methods.
Case Study
A case study involving an online car-hailing car in Hangzhou demonstrated the practical effectiveness of GARLIC. The framework successfully identified the most suitable passenger pick-up location based on the driver’s familiarity with different regions, aligning with the actual vehicle trajectory.
Overall Conclusion
The GARLIC framework offers a comprehensive solution to the core challenges in vehicle dispatching by combining hierarchical traffic state representation, dynamic reward generation, and GPT-augmented dispatching policy learning. The experimental results demonstrate its effectiveness and efficiency in optimizing vehicle dispatching policies while considering individual driving behaviors. Future work aims to further optimize information transmission and improve the overall user experience in vehicle dispatching.














