





Authors:
Md Fahim Sikder、Resmi Ramachandranpillai、Daniel de Leng、Fredrik Heintz
Paper:
https://arxiv.org/abs/2408.10755
Introduction
Background
The rapid proliferation of AI-powered applications has brought significant advancements in various fields, such as language translation and healthcare diagnosis. However, the datasets used to train these AI systems often contain biases, either from human or machine sources. These biases can lead to unfair outcomes when the AI models are deployed, affecting certain demographics disproportionately. For instance, the COMPAS case highlighted how risk assessment software could unfairly target African-Americans due to biased training data.
Problem Statement
Existing bias-mitigation techniques, such as Generative Adversarial Networks (GANs) and Diffusion models, often require extensive computational resources and can be unstable. These methods also fail to address the computational overhead effectively. To tackle these issues, this study proposes a novel approach that leverages knowledge distillation to generate fair synthetic data with reduced computational demands.
Related Work
Fair Representation Learning
Various techniques have been developed to learn fair representations from biased data. For example, LFR (Zemel et al., 2013) treats representation learning as an optimization task, while FairDisco (Liu et al., 2022) minimizes the correlation between sensitive and non-sensitive attributes. Adversarial approaches have also been employed to critique potential unfair outcomes (Gao et al., 2022; Madras et al., 2018).
Knowledge Distillation
Knowledge distillation involves transferring knowledge from a larger, trained model (teacher) to a smaller model (student). This technique is commonly used in classification tasks but is less explored in representation learning due to its reliance on data labels. Recent works like RELIANT (Dong et al., 2023) and FairGKD (Zhu et al., 2024) have applied distillation to data fairness, but they still depend on data labels.
Fair Generative Models
Generative models like GANs and Diffusion models have been used to generate fair synthetic data. However, these models are computationally expensive. For instance, TabFairGAN (Rajabi and Garibay, 2022) adds fairness constraints during training, while FLDGMs (Ramachandranpillai et al., 2023) generate latent spaces using GANs and Diffusion models.
Research Methodology
Problem Formalization and Data Fairness
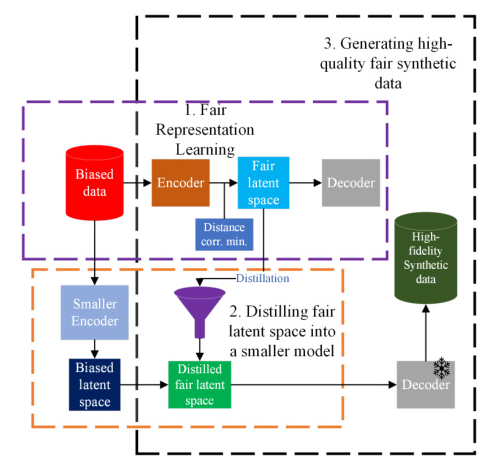
The goal is to create a fair generative model ( G ) that generates a synthetic dataset ( D’ ) by creating and distilling fair representations. The fair representation is obtained using an encoder ( f_\phi ) that minimizes the correlation between sensitive and non-sensitive attributes. The model aims to satisfy algorithmic fairness criteria like Demographic Parity (DP) and Equalized Odds (EO).
Knowledge Distillation
Knowledge distillation transfers knowledge from a trained model to a smaller model. In this study, the distillation process involves matching the distributions of the latent spaces of the teacher and student models. The overall objective combines quality loss and utility loss to ensure fairness and data utility.
Synthetic Data Generation
Generative models like Variational AutoEncoders (VAEs), GANs, and Diffusion models are used to create synthetic samples. The proposed Fair Generative Model (FGM) generates high-fidelity fair synthetic data by distilling fair latent spaces into smaller models.
Experimental Design
Datasets
The study uses four benchmarking datasets: Adult Income, COMPAS, CelebA, and Color MNIST. These datasets are widely used in the field of data fairness.
Evaluation Metrics
The performance of the model is evaluated using several criteria:
– Fairness: Measured using Demographic Parity Ratio (DPR) and Equalized Odds Ratio (EOR).
– Data Utility: Assessed using Accuracy, Recall, and F1-score.
– Visual Evaluation: Conducted using t-SNE and PCA plots.
– Synthetic Data Quality: Evaluated using Density and Coverage metrics.
– Explainability Analysis: Feature importance is analyzed using an explainable algorithm.
Experimental Setup
The model design follows the setup presented in FairDisco (Liu et al., 2022). The datasets are split into training and testing sets in an 80-20 ratio. Each evaluation metric is run ten times, and the mean and standard deviation are reported.
Results and Analysis
Tabular Data Results
The model’s performance on the Adult Income dataset shows significant improvements in fairness and data utility compared to state-of-the-art methods. The L1-KL variation achieves the best results, with near-perfect fairness scores (DPR & EOR) and high data utility metrics.


Image Data Results
The model generates high-quality synthetic images for the CelebA and Color MNIST datasets, accurately reflecting the sensitive sub-groups.

Visual Evaluation
PCA and t-SNE plots demonstrate that the distilled model captures the data distribution of the fair base model effectively.

Synthetic Data Analysis
The synthetic data generated by the model follows the original data distribution closely and exhibits high diversity, as indicated by the Density and Coverage metrics.
Explainability Analysis
Feature importance analysis shows that the sensitive attribute’s importance is significantly reduced in the synthetic data, indicating fairer outcomes.

Run-time Analysis
The proposed model requires significantly less training time compared to other generative models, making it more computationally efficient.
Overall Conclusion
This study presents a novel approach to generating fair synthetic data by distilling fair representations into smaller models. The proposed method outperforms state-of-the-art models in terms of fairness, data utility, and computational efficiency. The results demonstrate the potential of this approach to mitigate unfair decision-making in AI systems.



