





Authors:
Junlin Chen、Chengcheng Xu、Yangfan Xu、Jian Yang、Jun Li、Zhiping Shi
Paper:
https://arxiv.org/abs/2408.09220
Introduction
Video action recognition has been a pivotal task in the realm of video understanding, attracting significant attention from researchers. Traditional methods often involve converting videos into three-dimensional data to capture both spatial and temporal information. These methods typically adapt image understanding models to handle the spatiotemporal nature of video data. However, this approach presents several challenges, including the need for model architecture adjustments and the high computational cost associated with processing high-dimensional data.
To address these issues, the authors propose a novel video representation architecture called Flatten. This architecture transforms 3D spatiotemporal data into 2D spatial information, allowing conventional image understanding models to process video data efficiently. By applying specific flattening operations, the Flatten method simplifies video action recognition tasks, making them more akin to image classification tasks.
Related Work
Video Understanding
Temporal action information is crucial in video understanding. Various methods have been developed to capture spatiotemporal information in videos:
- 3D Convolutional Networks: Methods like C3D, I3D, and R(2+1)D use 3D convolutional kernels to model dependencies between spatial and temporal regions.
- Temporal Fusion with 2D Convolutions: Approaches such as Two-Stream Networks and SlowFast decompose video tasks into short-term and long-term temporal modeling.
- Transformer Networks: Methods like TimeSformer and Video Swin Transformer leverage the superior long-sequence modeling capabilities of transformers for spatiotemporal modeling in videos.
Image Understanding
Image understanding has been a fundamental task in computer vision, with significant advancements driven by deep learning methods. Convolutional neural networks (CNNs) like ResNet have been widely used, and more recently, transformers have been applied to image understanding tasks. Hybrid models combining CNNs and transformers have also been explored to leverage the strengths of both architectures.
Research Methodology
Formulation
The Flatten method transforms the video action recognition task from a three-dimensional data modeling task into a two-dimensional data modeling task. This transformation blurs the boundary between image understanding and video understanding. The general Flatten operation in deep neural networks is defined as:
[ Y = g(f(x, y, z)) ]
Here, ( g(x, y) ) represents a general image-understanding neural network, and ( f(x, y, z) ) denotes a transformation rule. The transformation converts video data represented by a set of images ( I \in \mathbb{R}^{x \times y \times z} ) into video data represented by a single image ( I’ \in \mathbb{R}^{x’ \times y’} ).
Instantiations
The authors describe several types of Flatten operations:
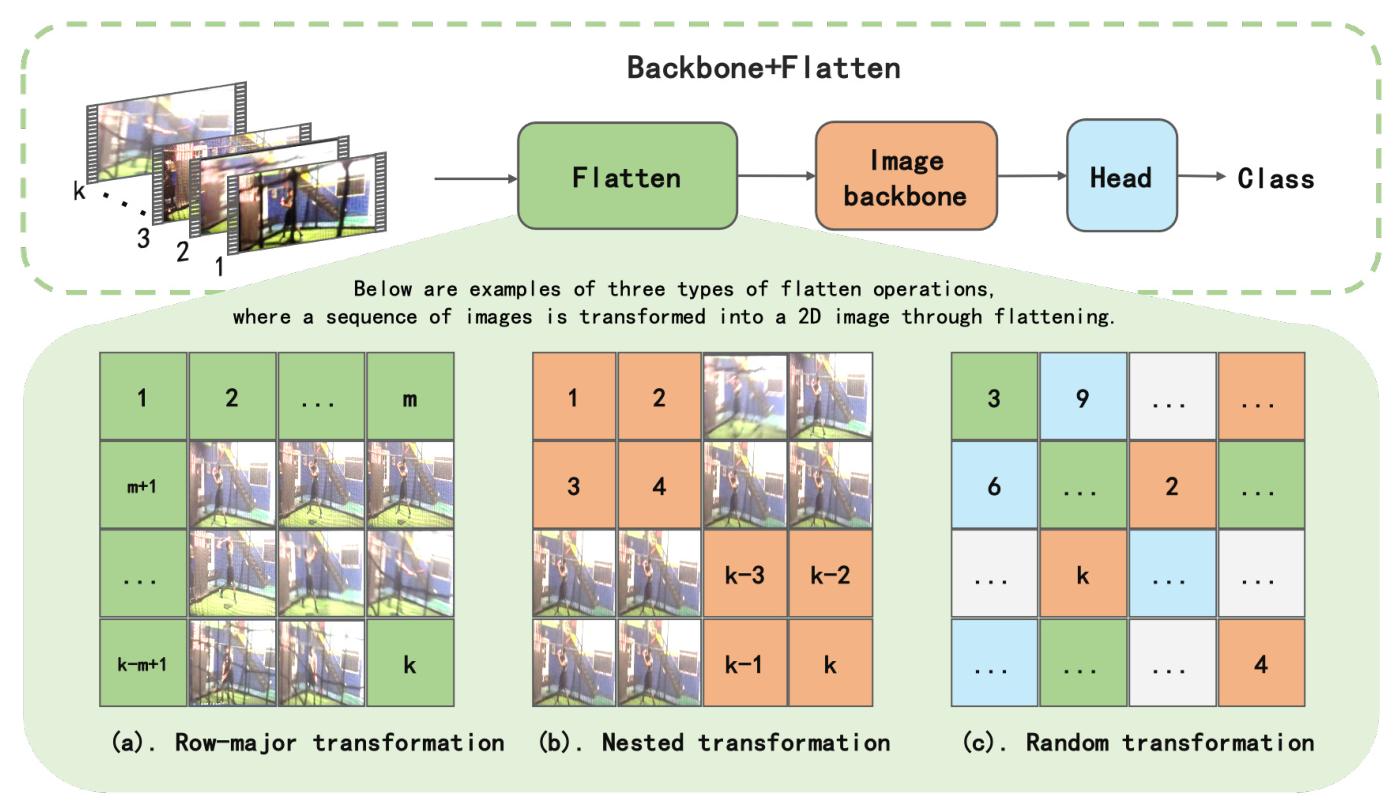
- Row-major Transformation: This method unfolds the data along the row direction, similar to converting a video into a comic strip.
- Nested Transformation: Inspired by methods like SlowFast, this approach balances short-term and long-term temporal relationships during data transformation.
- Random Transformation: This method randomly shuffles the temporal sequence of the ordered image sequence, allowing the model to learn the transformation rules and model temporal relationships in the spatial dimension.
Experimental Design
Experimental Setup
The experiments involve three mainstream network models (ResNet, Swinv2, and Uniformer), three types of Flatten operations, and three mainstream video action recognition datasets (Kinetics400, Something-Something V2, and HMDB51). The goal is to demonstrate the generality and effectiveness of the Flatten method across different models and datasets.
Network Models
- ResNet: A classic convolutional neural network with residual connections and blocks.
- Swin-TransformerV2: A transformer-based model that uses a sliding window mechanism to address computational cost issues.
- Uniformer: A hybrid model combining CNNs and transformers, applying convolutions in shallow layers and transformers in deep layers.
Datasets
- Kinetics400: A large-scale video action recognition dataset with 400 action categories.
- Something-Something V2 (SSV2): A dataset focusing on interactions between objects, emphasizing fine-grained motion recognition.
- HMDB51: A benchmark dataset for human action recognition with 51 action categories.
Results and Analysis
Ablation Study
The ablation experiments compare the effects of different Flatten operations on the model’s ability to model temporal relationships in the spatial dimension. The results show that both row-major and nested transformations outperform the original Uniformer(3D)-XXS in terms of Top-1 accuracy. The random transformation also demonstrates the model’s ability to learn transformation rules and model temporal relationships.
Comparison with State-of-the-Art Methods
The Flatten method is tested on three mainstream video action datasets and three network models. The results show that the Flatten method achieves competitive accuracy performance, demonstrating its effectiveness and versatility. For example, the Uniformer(2D)-S+Flatten model achieves superior Top-1 accuracy compared to the original Uniformer(3D)-S method on the SSV2 and HMDB51 datasets.
Visualization
Heatmap visualizations generated using Grad-CAM show that the Flatten method helps the model learn temporal relationships through spatial modeling. The optimization curves indicate that the model using the Flatten method achieves lower loss and faster convergence compared to the original model.
Overall Conclusion
The Flatten method transforms video-understanding tasks into image-understanding tasks, simplifying the complexity of video action recognition. Extensive experiments on multiple datasets and models demonstrate the effectiveness and versatility of the Flatten method. Future work will explore joint training methods for images and videos, as well as the model’s “error correction ability” for shuffled image sequences.
Illustrations
-
Flatten Operation: The Flatten operation converts image sequences into single-frame two-dimensional images, enabling the processing of video-understanding tasks like reading a comic strip.
!
-
Flatten Variants: An overview of action recognition network embedding Flatten operation, which converts a sequence of images into a single-frame image, enabling image-understanding models to be easily applied to video-understanding tasks. Examples of Flatten operations: (a) row-major transformation, (b) nested transformation, and (c) random transformation.
!
-
Comparison with State-of-the-Art: Performance comparison of different models using the Flatten method on the Kinetics400 dataset.
!
-
Ablation Study Results: The impact of different Flatten variants on the video-understanding capability of the Uniformer-XXS model.
!
-
Visualization: Heatmap visualization comparison showing how the Uniformer(2D)-S+Flatten model performs temporal modeling in space.
!
-
Optimization Curve: Optimization curves of Uniformer(3D)-S and Uniformer(2D)-S+Flatten trained on the Kinetics400 dataset.
!
-
Feature Map Visualization: Changes in feature maps during the model’s inference process, showing how the Flatten method aids in modeling temporal relationships through spatial positional information.
!



