





Authors:
Xiaochen Wang、Jiaqi Wang、Houping Xiao、Jinghui Chen、Fenglong Ma
Paper:
https://arxiv.org/abs/2408.10276
Introduction
The advent of foundation models has revolutionized the field of artificial intelligence (AI), showcasing remarkable capabilities in handling diverse modalities and tasks. However, in the medical domain, the development of comprehensive foundation models faces significant challenges due to limited access to diverse modalities and stringent privacy regulations. This study introduces a novel approach, FEDKIM, designed to scale medical foundation models within a federated learning framework. FEDKIM leverages lightweight local models to extract healthcare knowledge from private data and integrates this knowledge into a centralized foundation model using an adaptive Multitask Multimodal Mixture Of Experts (M3OE) module. This method not only preserves privacy but also enhances the model’s ability to handle complex medical tasks involving multiple modalities.
Related Work
Medical Foundation Models
Foundation models have demonstrated impressive capabilities across various domains, including healthcare. Medical foundation models, such as MMedLM2 and LLava-Med, have achieved superior performance in handling diverse modalities and tasks within the medical domain. These models have the potential to revolutionize medical diagnostics and treatment by leveraging data-driven insights from large volumes of multimodal healthcare data. However, the development of these models is constrained by the difficulties in aggregating sensitive healthcare data and the high degree of specialization of existing models, which limits their effectiveness to a narrow range of downstream tasks within specific modalities.


Federated Fine-tuning with Foundation Models
Fine-tuning foundation models with task-specific data is essential for improved performance in specialized tasks. Federated Learning (FL) supports this by utilizing locally stored data and distributed computational resources. Recent studies have made progress in federated foundation models, primarily focusing on enhancing services to local clients using existing foundation models. However, none have specifically tackled the challenge of injecting novel medical knowledge into existing medical foundation models in a federated manner.
Parameter-efficient Fine-tuning on Foundation Models
Full-parameter fine-tuning of foundation models requires extensive computational resources. Consequently, researchers have investigated Parameter-efficient Fine-tuning (PEFT) techniques, such as Low-Rank Adaptation (LoRA), which aim to adapt pre-trained models to specific tasks using a minimal number of additional parameters. These methods have shown promise in reducing the number of trainable parameters while maintaining performance.
Research Methodology
Framework Setups
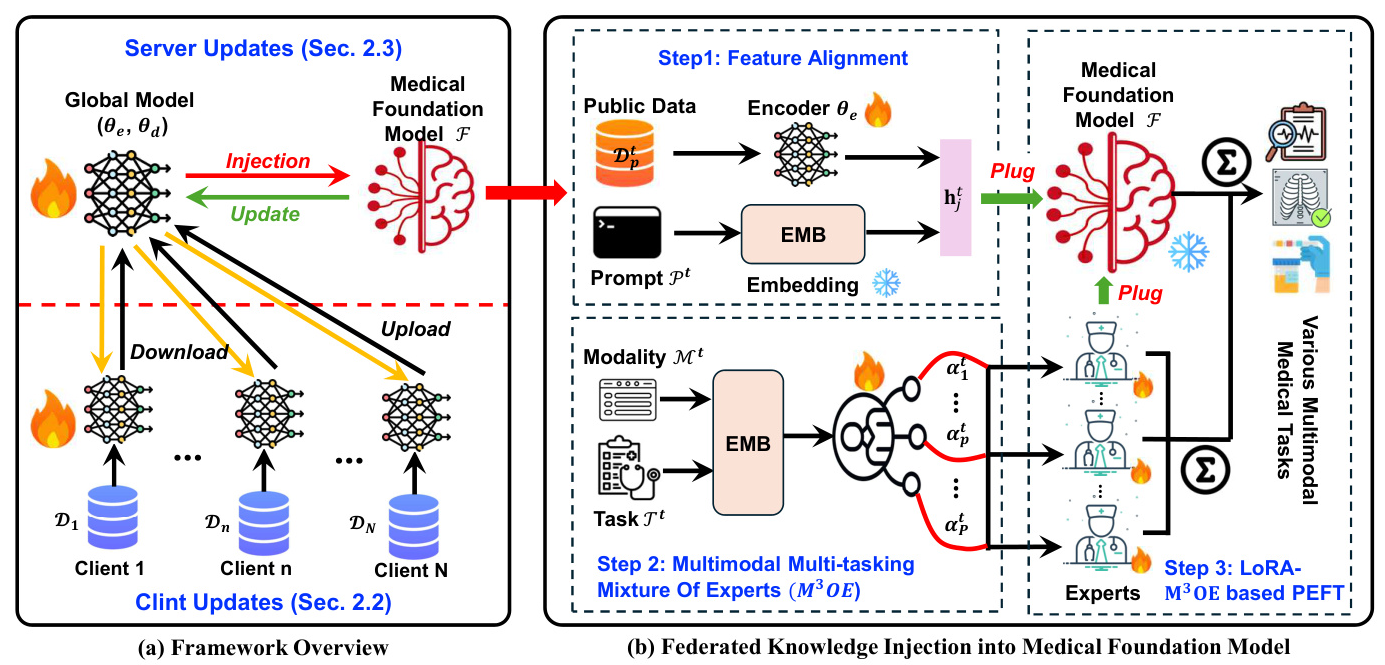
FEDKIM consists of two main components: knowledge extractors deployed on local clients and a knowledge injector deployed on the server.
Client Setups
The goal is to scale and enhance the predictive ability of medical large language models (LLMs) by incorporating medical knowledge from private client data in a federated manner. Each client, representing a hospital or a medical institute, holds private medical data and trains a model using this data. The model parameters are then uploaded to the server.
Server Setups
A generative medical foundation model is deployed on the server. The aim is to inject medical knowledge from the client models into the foundation model and simultaneously update the client models by absorbing new knowledge from the foundation model. A small amount of public data is placed on the server to facilitate the updates of client parameters.
Client Updates – Knowledge Extraction from Private Clients
Each client handles multiple tasks simultaneously using modality-specific encoders and task-specific decoders. The client model is trained using a loss function specific to each task, and the encoder and decoder parameters are uploaded to the server after local training.
Server Updates – Knowledge Injection into Medical LLM
Knowledge Aggregation
Knowledge uploaded from each client is aggregated using traditional federated learning methods, such as FedAvg or FedProx.
Knowledge Injection
The knowledge injection process involves three steps:
- Feature Alignment: Feature representations of input data are obtained using the aggregated encoders and concatenated with task prompt features.
- Multimodal Multi-tasking Mixture of Experts (M3OE): The M3OE module adaptively selects appropriate expert systems for handling specific tasks in given modalities.
- LoRA-M3OE based Parameter-Efficient Fine-tuning: The representation of each layer in the foundation model is generated based on LoRA and the learned M3OE weight.

Experimental Design
Task Introduction
The study involves training tasks and validation tasks across different datasets and data modalities.
Training Tasks
Four classification tasks across six modalities are used to federatedly inject medical knowledge into the foundation model through multi-task training.
Validation Tasks
Five classification tasks and three generation tasks are compiled to evaluate the extent to which knowledge injection enables the medical foundation model to tackle unseen tasks.

Data Partition
For each training task, the data is divided into four parts in a ratio of 7:1:1:1. Private data is distributed to clients for training local models, public data is placed on the server for tuning the foundation model, development data is kept on the server as a validation set, and testing data is used for evaluation.
Baselines
Since the task of medical knowledge injection is novel and unexplored, the study establishes its own baselines:
- FedPlug: Acquires modality-specific encoders through the federated learning process and integrates them into the foundation model for fine-tuning.
- FedPlugL: Incorporates the Low-Rank Adaptation (LoRA) technique to better integrate multimodal features into the semantic space of the large language model (LLM).
FL Backbone Approaches
FEDKIM is implemented based on the following backbone approaches:
- FedAVG: A conventional federated learning method that produces a global model by aggregating distributed models.
- FedProx: Extends FedAvg by regularizing each local loss function with an L2 term.
Implementation Details
All experiments were conducted in an Ubuntu 20.04 environment using two NVIDIA A100 GPUs. MMedLM-2, a state-of-the-art pre-trained medical language model, was used as the target of medical knowledge injection. The learning rate was set to 5 × 10−4 for the foundation model and 1 × 10−4 for the local models. The number of clients was set to 5, and the number of experts was set to 12 for FEDKIM. The number of communication rounds was set to 10 for all methods involved in the comparison.
Results and Analysis
Zero-shot Evaluation
The zero-shot evaluation examines the zero-shot capability of the medical foundation models enabled by FEDKIM. The experiment results on unseen tasks are shown in Figure 2, with FedAvg and FedProx as the backbone federated approaches.


Observations and discussion:
- The original foundation model MMedLM2 fails to perform zero-shot evaluation on unseen tasks due to its limited multimodal capabilities.
- FedPlug performs the worst across all tasks, highlighting the necessity of effectively utilizing public data to align the medical foundation model with external knowledge.
- FedPlugL approaches FEDKIM’s performance on several tasks but falls short, particularly in generation tasks. FEDKIM achieves better performance on these tasks and maintains superior capability in handling unseen classification tasks.
Fine-tuning Evaluation
The fine-tuning evaluation assesses whether the enhanced foundation model can perform well on previously encountered tasks. The fine-tuning results are presented in Table 3.

The knowledge-injected medical foundation model performs significantly better on familiar tasks, showcasing the explicit utilization of knowledge acquired through federated training. Approaches combined with FedProx consistently outperform those with FedAvg, underscoring the importance of effective knowledge extraction during the injection process. FEDKIM consistently outperforms the baselines, validating the design and effectiveness of the M3OE module.
Ablation Study
An ablation study on the COVID-19 detection task assesses the impact of each module within FEDKIM. The results indicate that each component significantly enhances FEDKIM’s performance. The substantial decline in performance with FEDKIMpub highlights the crucial role of knowledge injected from local clients through federated learning. The absence of task or modality descriptions diminishes FEDKIM’s ability to manage specific tasks through multi-task training, validating the design of the M3OE module.
Overall Conclusion
This study introduces FEDKIM, a novel approach for adaptive federated knowledge injection into medical foundation models. FEDKIM leverages flexible federated learning techniques to extract knowledge from distributed medical data and injects this knowledge into the foundation model using an adaptive M3OE module. The extensive experimental results demonstrate the effectiveness of FEDKIM in diverse settings, showcasing its excellent capability in handling either encountered or unseen healthcare tasks. This study validates the potential of injecting knowledge into foundation models using federated learning, providing a crucial solution for developing a healthcare foundation model without accessing sensitive data.


