





Authors:
Siqi Ouyang、Xi Xu、Chinmay Dandekar、Lei Li
Paper:
https://arxiv.org/abs/2408.09430
Introduction
Simultaneous speech translation (SST) is a challenging task that involves translating streaming speech input into text in another language in real-time. This technology is crucial for applications such as multilingual conferences and live streaming. Traditional SST methods often struggle with high latency due to the need for recomputation of input representations or fall short in translation quality compared to offline speech translation (ST) models.
In this context, the paper introduces FASST, a novel method leveraging large language models (LLMs) to achieve efficient and high-quality simultaneous speech translation. FASST employs blockwise-causal speech encoding and consistency masks to incrementally encode streaming speech input without recomputation. Additionally, a two-stage training strategy is developed to optimize the model for simultaneous inference.
Related Work
End-to-End Simultaneous Speech Translation
End-to-end SST models translate partial speech input directly into text without generating intermediate transcriptions. Various techniques have been proposed to optimize the quality-latency trade-off, including speech segmentation by word boundaries and adaptive policies like wait-k and monotonic multihead attention (MMA). However, these methods often depend heavily on the offline performance of the models.
Efficient Speech Translation
To reduce computation costs, several methods focus on optimizing the encoder side, such as using segments and memory banks to calculate self-attention only within segments. These techniques can be integrated with FASST to further enhance efficiency.
Translation with Large Language Models
LLMs have shown strong performance in zero-shot machine translation and can be further improved through in-context learning and finetuning. For simultaneous machine translation, strategies like collaborative translation models and special “wait” tokens have been proposed. However, these methods primarily focus on text translation rather than speech translation.
Research Methodology
Problem Formulation
Simultaneous speech translation requires generating translations while receiving streaming speech input. The input speech waveform is segmented, and the SST model emits partial translations after receiving each segment. The objective is to produce high-quality translations with low latency.
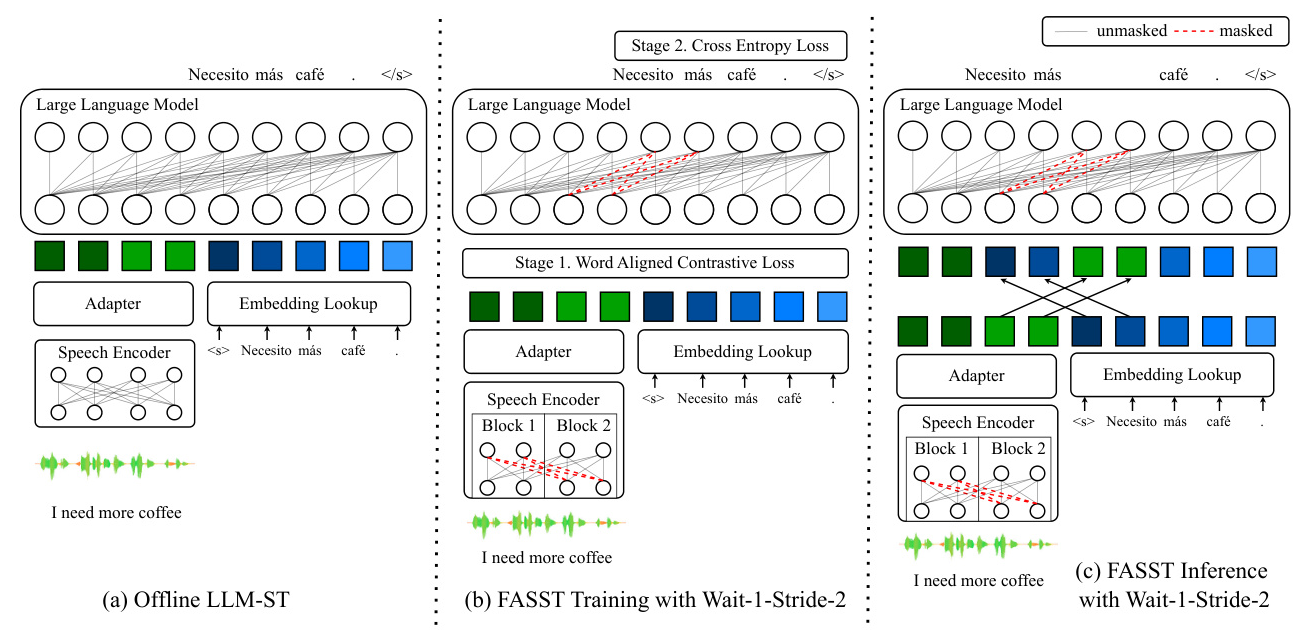
Model Architecture
FASST consists of three main components:
- Blockwise-Causal Speech Encoder (BCSE): This component incrementally extracts contextualized acoustic features from the raw waveform using causal convolutional layers and a blockwise-causal Transformer encoder.
- Adapter: The adapter converts speech encoder outputs into the LLM embedding space using causal convolutional layers and a linear layer.
- LLM Decoder: The LLM decoder receives speech embeddings and previously generated token embeddings to decode autoregressively according to a wait-k-stride-n policy.
Training Strategy
FASST employs a two-stage training strategy:
- Speech-Text Alignment: Aligns speech embeddings with LLM input embeddings using word-aligned contrastive (WACO) loss.
- Finetuning for Simultaneous Translation: Finetunes the entire model using the wait-k-stride-n policy, ensuring that text generation during inference does not affect the positional embeddings of speech embeddings.
Experimental Design
Dataset
Experiments are conducted on the MuST-C v1.0 dataset, focusing on English to Spanish (En-Es) and English to German (En-De) translations. The dataset contains around 400 hours of audio recordings, with average utterance durations of less than 10 seconds. To simulate long speech scenarios, adjacent utterances are concatenated to create longer utterances, resulting in the MuST-C-Long dataset.


Model Configurations
The speech encoder is initialized with the wav2vec 2.0 large model, and the LLM is initialized with Llama2 7b Base. The adapter consists of causal convolutional layers and a linear layer to project features into the LLM embedding space. The model is trained with mixed MuST-C-Short and MuST-C-Long data using AdamW optimizer and cosine learning rate decay.
Inference
During inference, the speech segment size is set to 1 second to match the block size. The model waits for a specified number of segments before starting to generate translations, encoding speech embeddings incrementally and generating words with greedy decoding.
Results and Analysis
Main Results
FASST achieves the best quality-latency trade-off for the En-Es direction, outperforming strong prior methods by an average of 1.5 BLEU at the same latency. For the En-De direction, FASST achieves competitive results, with slightly better quality at lower latencies.

Ablation Studies
Speech Encoder and LLM
Replacing wav2vec 2.0 with HuBERT and Llama2 with Mistral shows that FASST consistently has lower latency than the baseline, demonstrating its robustness to different pretrained models.

Incremental Encoding and Decoding
Incremental speech encoding and LLM decoding significantly reduce computational latency compared to recomputing the entire encoder and decoder at each step.

Training Strategy
Using WACO loss for speech-text alignment and training with mixed MuST-C-Short and MuST-C-Long data results in the best performance, highlighting the importance of these components in the training strategy.

Generalizability to Other Policies
FASST is also tested with the hold-n policy, showing that it can generalize to different policies, although the advantage is less pronounced compared to wait-k-stride-n due to the heavier autoregressive decoding involved in hold-n.

Overall Conclusion
FASST introduces a fast and efficient method for simultaneous speech translation using large language models. By employing blockwise-causal speech encoding, incremental LLM decoding, and a novel two-stage training strategy, FASST achieves a significant reduction in computation overhead while maintaining high translation quality. The method shows promise for real-time applications and can generalize to different translation policies.
Limitations
- Potential data leakage due to the extensive pretraining of LLMs.
- Limited testing on only two language directions.
- Quality gap between blockwise-causal and bidirectional speech encoding.
- Exploration limited to one LLM-ST architecture.
Overall, FASST represents a significant advancement in the field of simultaneous speech translation, offering a practical solution for real-time multilingual communication.



