





Authors:
Bhuvanashree Murugadoss、Christian Poelitz、Ian Drosos、Vu Le、Nick McKenna、Carina Suzana Negreanu、Chris Parnin、Advait Sarkar
Paper:
https://arxiv.org/abs/2408.08781
Introduction
The paper “Evaluating the Evaluator: Measuring LLMs’ Adherence to Task Evaluation Instructions” explores the effectiveness of using Large Language Models (LLMs) as judges in automatic evaluation tasks. This method, known as LLMs-as-a-judge, aims to replace human judgments with automated evaluations using LLMs. The study investigates whether LLMs’ assessments are influenced by the instructions provided in prompts or if they reflect a preference for high-quality data similar to their fine-tuning data. The research analyzes prompts with varying levels of instruction and compares them to a prompt-free method using model perplexity as a quality measure.
LLMs-as-a-Judge
LLMs-as-a-judge refers to using LLMs to evaluate AI-generated responses, replacing human annotations. The study focuses on judging textual examples, such as AI-generated summaries or solutions to mathematical reasoning questions. The task is to judge the quality of an AI-generated solution given a specific task. The study evaluates the impact of different prompting settings on the alignment of LLM judgments with human judgments.
Prompting Settings
- Perplexity: Scoring each task solution by its perplexity under the corresponding LLM, given only the task description.
- Generic Quality Prompt: Prompting the LLM with a basic instruction to measure the quality of the task solution without specific criteria.
- Criteria Specific Prompt: Prompting the LLM with an instruction to measure the quality for a specific criterion, relying on the model’s prior knowledge.
- Full Rubric Prompt: Prompting the LLM with detailed instructions and definitions for specific quality criteria.


Datasets
The study uses eight different open-source benchmark datasets commonly used for LLM-based evaluations with human annotations. These datasets cover various aspects, from coarse-grained NLG-quality evaluations to fine-grained task-specific evaluations. The datasets include:
- SummEval: News article summaries with human annotations for quality criteria like fluency.
- TopicalChat: Human conversations annotated for quality criteria like engagement.
- OpinSummEval: Opinion summarization dataset with annotations for aspects, opinions, and sentiments.
- InstruSumm: News article summaries with annotations for content-specific quality criteria.
- Hanna: Creative stories annotated for NLG and style-based criteria.
- TheNextChapter: Creative stories with annotations for unconventional criteria like surprise.
- Roscoe: Reasoning tasks with GPT3-generated solutions and human annotations for task-specific criteria.
- Flask: Knowledge and problem-solving tasks with LLM-generated solutions and human annotations for fine-grained criteria.
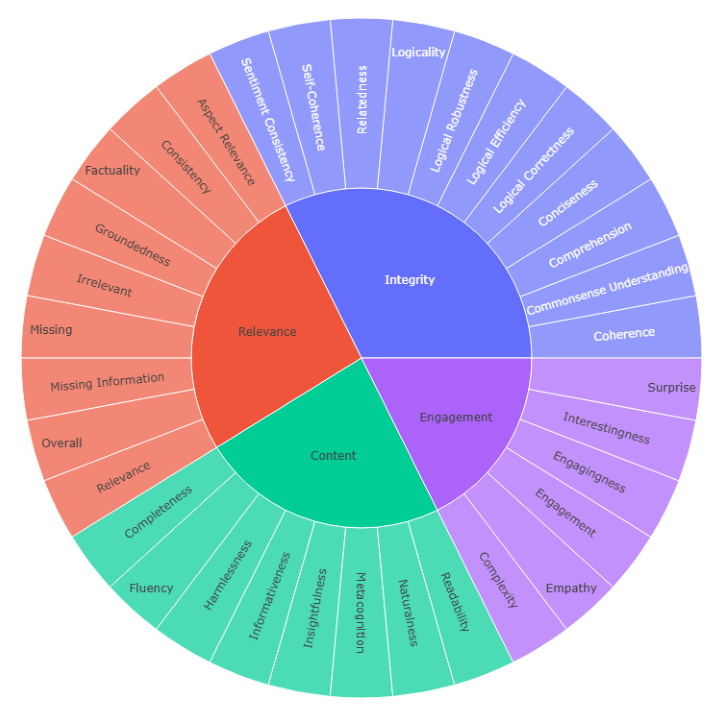
Criteria Taxonomy
The study introduces a taxonomy of quality evaluation criteria based on current state-of-the-art benchmark datasets. The criteria are grouped into four categories:
- Content-based Criteria: Measure the quality of the content as presented to the user.
- Engagement-based Criteria: Measure how engaging the solution is.
- Integrity-based Criteria: Measure the coherence and logical consistency of the solution.
- Relevance-based Criteria: Measure the relevance of the solution to the given task.

Model Selection for LLM-as-a-Judge
The study evaluates several current LLMs to understand how model size and fine-tuning affect performance across different quality criteria and prompting settings. The models tested include:
- GPT4-Turbo
- Llama3 70b
- Llama3 8b
- Mistral-v0.3
- Phi3-Medium-128k
- Prometheus-2
Results
Model Level Results
The study finds that providing LLMs-as-a-judge with more detailed rubric information generally has a small influence on evaluation performance for large and mid-size models. Smaller models like Llama3 8b and Mistral see improvements with comprehensive rubric information. GPT4 performs best among all models, showing high agreement with human judgments even without detailed instructions.

Dataset Level Results
The study observes that quality criteria from datasets with simple textual content creation tasks show high agreement with models’ perplexity compared to simple prompting. More complex NLG tasks benefit from more detailed rubric information. Dataset-level analysis can be misleading, so the study uses the introduced taxonomy to analyze results on a per-criteria class basis.

Criteria Level Analysis
- Content-based Criteria: Perplexity is a viable alternative to prompting for evaluating textual quality. Simple prompts generate judgments with high agreement with human judgments.
- Engagement-based Criteria: These criteria benefit the most from full rubric information due to their subjective nature.
- Relevance-based Criteria: Larger models perform better in evaluating relevance-based criteria. Full rubric information is not always necessary.
- Integrity-based Criteria: Evaluating integrity-based criteria requires models to understand and solve the task. Larger models like GPT4 perform significantly better.

Conclusion
The study concludes that detailed quality criteria information might not be necessary for the most powerful models like GPT4, which show high agreement with human judgments even without detailed instructions. Simple perplexity values are effective at estimating textual quality, often outperforming prompting with basic instructions. Judging task-specific quality criteria requires more capable, larger models.

This research provides valuable insights into the effectiveness of LLMs-as-a-judge and highlights the potential of using model perplexity as an alternative to prompting for certain evaluation tasks.


