





Authors:
Jinghuai Jie、Yan Guo、Guixing Wu、Junmin Wu、Baojian Hua
Paper:
https://arxiv.org/abs/2408.10527
Introduction
Edge detection is a fundamental task in computer vision, crucial for various applications such as object recognition, image segmentation, and scene understanding. Traditional methods primarily rely on local features like color and texture variations, while more recent deep learning approaches leverage convolutional neural networks (CNNs) to capture global and semantic features. However, CNNs often struggle to preserve intricate local details. This paper introduces EdgeNAT, a one-stage transformer-based edge detector that utilizes the Dilated Neighborhood Attention Transformer (DiNAT) as its encoder. EdgeNAT aims to efficiently and accurately extract object boundaries and meaningful edges by capturing both global contextual information and detailed local cues.


Related Work
Edge Detection
Early edge detection methods focused on local features such as color, texture, and intensity variations. Machine learning-based approaches improved performance by using handcrafted low-level features to train classifiers. CNN-based methods expanded receptive fields to capture global features, leading to significant advancements in edge detection. Recent methods have further enhanced performance by exploiting hierarchical and multi-scale feature maps produced by CNN encoders. The introduction of Vision Transformers (ViTs) for edge detection, such as EDTER, marked a significant milestone, although these models often suffer from high computational costs.
Vision Transformer
Transformers have become increasingly popular in the vision field since the introduction of ViT. Hierarchical transformers like Swin Transformer and NAT have shown remarkable performance in various vision tasks. DiNAT, an extension of NAT, combines neighbor attention and dilated neighbor attention to capture long-range dependencies and global features efficiently.
Feature Fusion Module
Feature fusion modules are essential for improving feature representations in edge detection and other vision tasks. Techniques like SENet, CBAM, and ECA have explored different strategies for channel and spatial attention to enhance global feature extraction. The proposed SCAF-MLA decoder in EdgeNAT aims to leverage both spatial and channel attention for effective feature fusion.
Research Methodology
Overview of EdgeNAT
EdgeNAT is a one-stage end-to-end edge detector that employs DiNAT as the encoder and introduces a novel decoder, SCAF-MLA, to facilitate feature fusion. The architecture of EdgeNAT is designed to capture both local detail information and global semantic features, enabling accurate and efficient edge detection.

Dilated Neighborhood Attention Transformer (DiNAT)
DiNAT serves as the encoder in EdgeNAT, preserving locality, maintaining translation equivariance, expanding the receptive field, and capturing long-range dependencies. The encoder employs a series of convolutional layers and dilated neighborhood attention mechanisms to process input images and generate multi-scale feature maps.

SCAF-MLA Decoder
The SCAF-MLA decoder integrates spatial and channel attention through the Spatial and Channel Attention Fusion Module (SCAFM). This module concurrently extracts spatial and channel features, preserving distinctive attributes while capturing higher-level features. The decoder also employs a pre-fusion strategy to enhance feature integration, reducing the channels of feature maps before fusion.

Loss Function
The loss function used in EdgeNAT is designed to supervise both the primary edge map and side edge maps. It incorporates a balance between positive and negative pixel samples, ensuring effective training. The overall loss function combines the losses for the primary and side edge maps, with a weight parameter to balance them.
Experimental Design
Datasets
EdgeNAT is evaluated on two mainstream datasets: BSDS500 and NYUDv2. BSDS500 consists of 500 RGB images, while NYUDv2 includes 1449 labeled pairs of aligned RGB and depth images. The datasets are augmented through flipping, scaling, and rotating to increase the number of training samples.
Implementation Details
EdgeNAT is implemented using PyTorch and is based on mmsegmentation and NATTEN. The model is initialized with pre-trained weights of DiNAT and trained using the AdamW optimizer. The training process involves a cosine decay learning rate scheduler and a batch size of 8 for BSDS500 and 4 for NYUDv2. All experiments are conducted on an RTX 4090 GPU.
Evaluation Metrics
Optimal Dataset Scale (ODS) and Optimal Image Scale (OIS) are used as evaluation metrics. Non-maximum suppression is performed on the predicted edge maps before evaluation. The tolerance distance between detected edges and ground truth is set to specific values for each dataset.
Results and Analysis
Ablation Study
Ablation experiments are conducted to verify the effectiveness of the proposed decoder. The results demonstrate that pre-fusion without PPM achieves the best performance, indicating its suitability for DiNAT-based edge detection models.
Network Scalability
EdgeNAT is evaluated in different model sizes to adapt to various application scenarios. The scalability experiments show that as the model size decreases, the ODS and OIS scores decrease, but the throughput increases. The L model achieves the highest performance due to its pre-training on ImageNet-22K.

Comparison with State-of-the-Arts
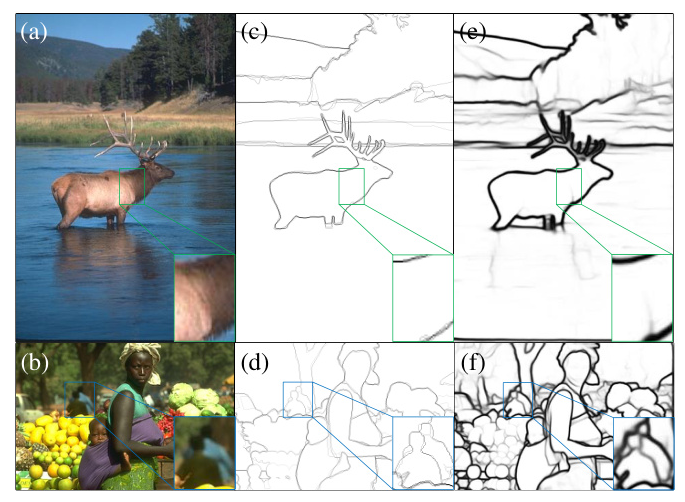
EdgeNAT is compared with traditional, CNN-based, and transformer-based edge detectors on the BSDS500 and NYUDv2 datasets. The results show that EdgeNAT outperforms all competing methods in terms of ODS and OIS scores, demonstrating its superiority in both efficiency and accuracy.

Overall Conclusion
EdgeNAT introduces a novel approach to edge detection by leveraging the powerful feature extraction capabilities of transformers. The combination of DiNAT as the encoder and the innovative SCAF-MLA decoder enables efficient and accurate edge detection. Extensive experiments on multiple datasets validate the effectiveness and scalability of EdgeNAT, establishing it as a state-of-the-art method in edge detection.

Code:
https://github.com/jhjie/edgenat


