





Authors:
Wei Sun、Yuan Li、Qixiang Ye、Jianbin Jiao、Yanzhao Zhou
Paper:
https://arxiv.org/abs/2408.09097
Introduction
Background
Image semantic segmentation is a fundamental task in computer vision, aiming to partition an image into regions that are meaningful based on visual characteristics. This task is crucial for various applications such as object recognition, scene understanding, and image editing. Traditional methods primarily rely on color, contour, and shape cues from 2D images. However, these methods often struggle to capture the 3D structure of the scene, leading to less accurate results, especially in complex environments.
Problem Statement
To address the limitations of traditional methods, researchers have integrated depth information into the segmentation process. Depth information provides valuable geometric context, revealing crucial cues such as object distances and occlusion relationships. However, directly fusing depth information with image features poses a challenge due to the intrinsic distribution gap between the two modalities. Depth maps lack texture and fine details, which are abundant in RGB images, leading to potential semantic mismatches when combined using simplistic methods.
Proposed Solution
In this study, we introduce a novel Depth-guided Texture Diffusion approach to enhance the compatibility between depth and 2D images. Our method selectively accentuates textural details within depth maps, effectively bridging the gap between depth and vision modalities. By integrating this enriched depth map with the original RGB image into a joint feature embedding, our method enables more accurate semantic segmentation.
Related Work
RGB-D Scene Parsing
RGB-D scene parsing has seen significant advancements in three main areas: indoor semantic segmentation, salient object detection, and camouflaged object detection. These tasks benefit from the integration of RGB images with depth maps, which provide complementary spatial relationships not immediately discernible in RGB data. Various fusion models have been developed to leverage both RGB and depth data, enhancing overall scene understanding.
RGB-D Salient Object Detection
Salient Object Detection (SOD) has been revolutionized by incorporating depth maps, facilitating a more comprehensive understanding of scene depth and object prominence. Different fusion strategies, including early, intermediate, and late fusion, have been explored to merge RGB and depth data effectively. Transformer-based approaches have also been introduced to enhance multi-modal fusion and feature integration.
Camouflaged Object Detection
Camouflaged Object Detection (COD) aims to identify objects designed to blend into their surroundings. Traditional methods using handcrafted features often fall short in complex scenarios. Recent deep learning models, inspired by search mechanisms in predatory animals, have shown improved performance. Transformer-based models have further enhanced the ability to capture global contextual information necessary for identifying subtle differences in complex scenes.
Research Methodology
Overall Architecture
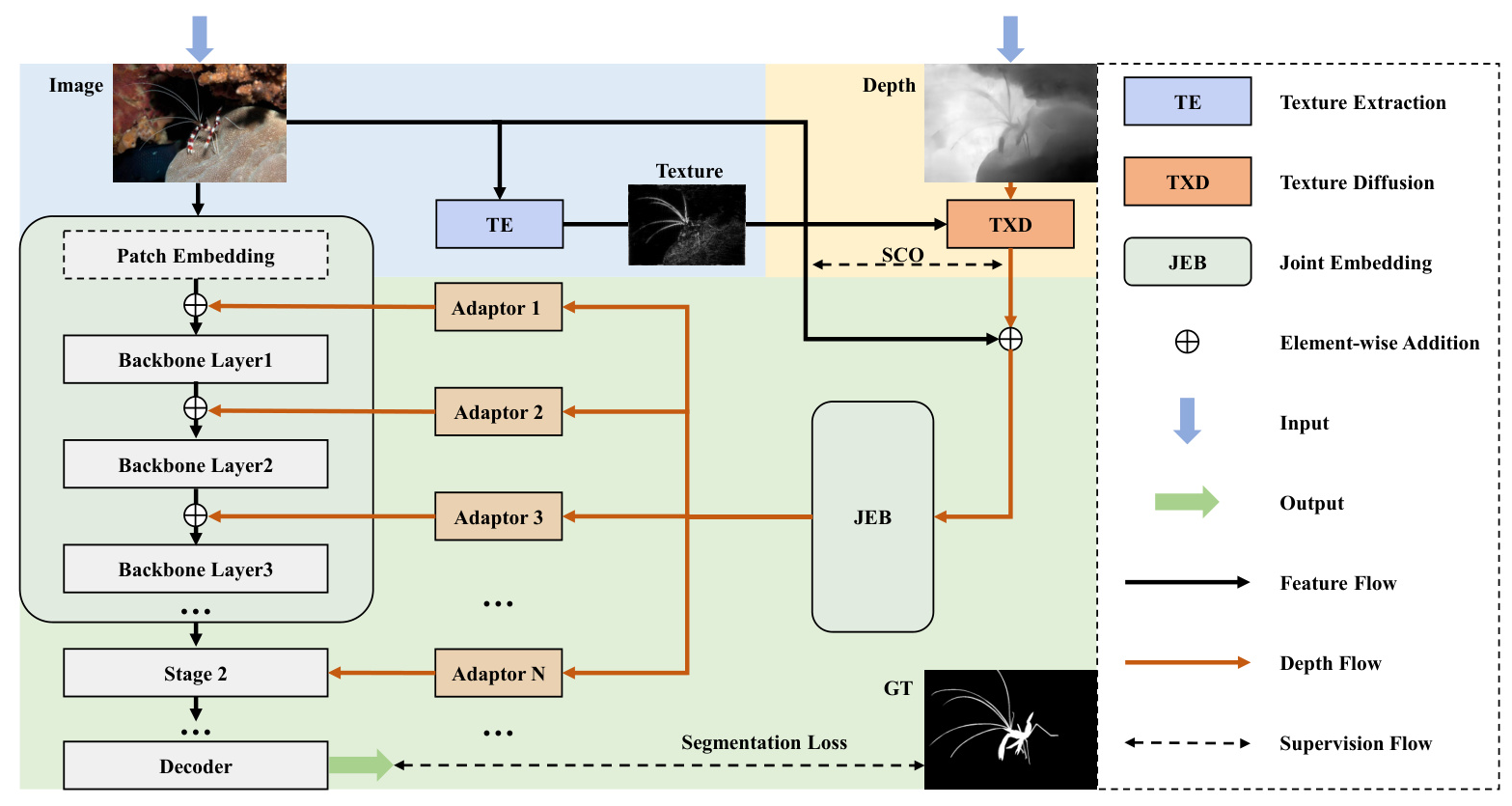
Our method comprises three primary modules: Texture Extraction (TE), Texture Diffusion (TXD), and Joint Embedding (JEB). The architecture is designed to capture and enhance textural features, propagate these features within depth maps, and integrate the texture-enriched depth with RGB images for improved feature synthesis and segmentation results.


Texture Extraction
The Texture Extraction (TE) module captures intricate texture features from the RGB domain using Fourier Transform (FFT). By transforming the image to the frequency domain and applying a high-pass filter, we extract high-frequency components and transform them back to the RGB domain, preserving shift invariance and local consistency.

Texture Diffusion
The Texture Diffusion (TXD) module integrates texture features into depth maps, enriching them with essential visual details. This process involves converting the depth map into latent features, predicting diffusion weights based on texture features, and iteratively updating the latent features to propagate texture information.

Structural Consistency Optimization
To ensure structural consistency between the texture-enhanced depth map and the RGB image, we employ a Structural Similarity Index (SSIM) as a loss function. This optimization step maintains the structural integrity of the depth map, facilitating seamless depth-RGB fusion and precise semantic segmentation.
Joint Embedding
The Joint Embedding (JEB) module combines the texture-enhanced depth map with the RGB image through element-wise addition. The combined representation is processed through an embedding network to refine the features for subsequent decoding, ensuring coherent feature synthesis and enhanced segmentation results.
Experimental Design
Datasets
We conduct experiments across various datasets for Salient Object Detection (SOD), Camouflaged Object Detection (COD), and indoor semantic segmentation.
- SOD Datasets: NJUK, NLPR, STERE, SIP
- COD Datasets: CHAMELEON, CAMO, COD10K, NC4K
- Indoor Semantic Segmentation Datasets: NYUDepthv2, SUN-RGBD
Evaluation Metrics
We employ several metrics to evaluate our models:
- Structure-measure (Sm)
- F-measure (Fβ)
- Enhanced-alignment measure (Eξ)
- Mean Absolute Error (M)
- Mean Intersection over Union (mIoU) for indoor semantic segmentation
Experimental Setup
For SOD and COD challenges, we use HitNet as the backbone, while for indoor semantic segmentation, we utilize DFormer. Training images are resized, and various data augmentation strategies are applied. The AdamW optimizer is employed with specific learning rates and decay schedules. Experiments are conducted on NVIDIA GeForce RTX 3090 GPUs.
Results and Analysis
Quantitative Results
Our method consistently outperforms existing baselines across all datasets, demonstrating superior performance in terms of Fβ, Eξ, and other metrics.


Qualitative Results
Visual comparisons show that our model can accurately identify objects in challenging scenarios, maintain robust layout perception, and precisely segment object details.

Ablation Studies
We conduct ablation studies to demonstrate the effectiveness of our proposed components and design choices. Incremental stacking of components on a base HitNet structure shows significant performance improvements.


Overall Conclusion
In this study, we introduce a Depth-guided Texture Diffusion approach that enhances image semantic segmentation by bridging the gap between depth and vision modalities. Our method effectively integrates texture features into depth maps, improving segmentation accuracy. Extensive experiments and ablation studies confirm the robustness and effectiveness of our approach, establishing new state-of-the-art results across various datasets. This research highlights the critical role of texture in depth maps for complex scene interpretation, paving the way for future advancements in depth utilization.


