





Authors:
Jahir Sadik Monon、Deeparghya Dutta Barua、Md. Mosaddek Khan
Paper:
https://arxiv.org/abs/2408.06503
Introduction
Multi-agent Reinforcement Learning (MARL) is a critical framework for various decision-making and control tasks. Unlike single-agent systems, MARL requires successful cooperation among agents, especially in decentralized settings with partial observability and sparse rewards. This paper introduces CoHet, an algorithm leveraging Graph Neural Network (GNN)-based intrinsic motivation to facilitate learning in heterogeneous multi-agent systems.
Related Works
Existing literature often addresses either agent heterogeneity or reward sparsity but rarely both. Traditional methods use agent indexing or centralized critics, which are impractical for decentralized settings. CoHet addresses these gaps by using local neighborhood information for intrinsic reward calculation, enhancing cooperation without prior knowledge of agent heterogeneity.
Background
Markov Games
The Markov games framework generalizes Markov decision processes to multiple agents with cooperating or competing goals. The Partially Observable Markov Games (POMG) framework is used under partial observability, defined by the tuple ⟨V, S, O, A, {oi}i∈V, {Ri}i∈V, T, γ⟩, where V is the set of agents, S is the state space, O is the observation space, A is the action space, Ri is the reward function, T is the state transition model, and γ is the discount factor.
Message-passing Graph Neural Network
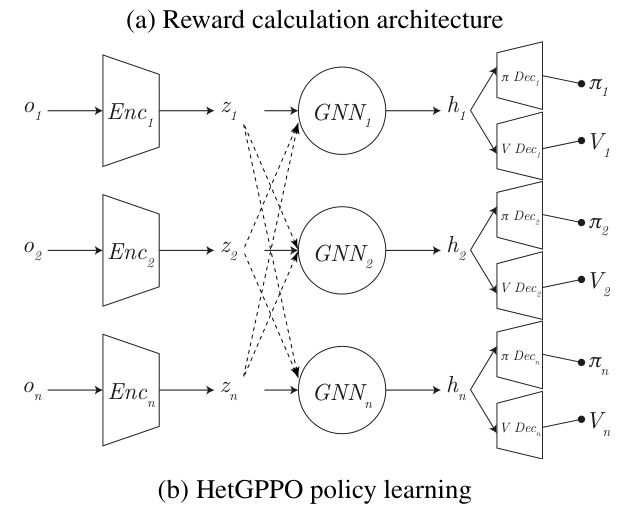
GNNs use message-passing to transfer information between nodes, effectively learning patterns in graphs. In CoHet, agents are represented as nodes, and edges are formed based on observation radii. Non-absolute features are used as node attributes, and relative positions and velocities as edge attributes, enhancing generalization.
The CoHet Algorithm
CoHet introduces a decentralized algorithm for enhancing cooperation among heterogeneous agents in partially observable environments with sparse rewards. It uses a GNN-based intrinsic reward mechanism to align agent actions with neighborhood predictions, reducing future uncertainty.
Algorithm Description
The CoHet algorithm initializes models for each agent, including encoders, MLPs, decoders, and dynamics models. Observations are processed to calculate node embeddings and edge features, which are used in the GNN to produce action and value outputs. Intrinsic rewards are calculated based on the alignment of agent predictions with their neighbors, and these rewards are combined with extrinsic rewards for policy optimization.
markdown
Algorithm 1: CoHet Algorithm
1: Initialize models ωi, ψi, ϕi, Ωi, Γi, fi with random values θi, where i ∈{1, 2, . . . , N}
2: for k = 1, 2, . . . do
3: Initialize set of trajectories for all agents, Dk ←{}
4: for t = 0, 1, . . . , T do
5: for i = 1, 2, . . . , N do
6: xt i ←trim(ot i){pt i,vt i}
7: zt i ←ωθi(xt i)
8: ht i ←ψθi(zt i)
9: for each j ∈N t i do
10: et ij ←pt ij∥vt ij
11: ht i ←ht i + L ϕθi(zt j∥et ij)
12: end for
13: at i ←Ωθi(ht i)
14: V t i ←Γθi(ht i)
15: end for
16: at ←at 1∥at 2∥. . . ∥at N
17: end for
18: for t = 0, 1, . . . , T do
19: for i ∈{1, 2, . . . , N} do
20: rt inti ←0
21: for each j ∈N t i ∩N t+1 i do
22: wj ← d(i,j) P k∈N t i ∩N t+1 i d(i,k)
23: rt inti ←rinti + wj × −∥ot t+1 −fθj(ot i, at i)∥
24: end for
25: rt totali ←rt exti + β × rt inti
26: end for
27: rt total ←rt total1∥rt total2∥. . . ∥rt totalN
28: Dk ←Dk ∪(ot, at, rt total, ot+1)
29: end for
30: Use Dk to for Multi-PPO policy optimization
31: end for
Intrinsic Reward Calculation
Intrinsic rewards are calculated using the dynamics model predictions of neighboring agents. The misalignment between predicted and actual observations is penalized, encouraging agents to align their actions with neighborhood predictions.


Experiments
CoHet was evaluated in six scenarios using the Multi-agent Particle Environment (MPE) and Vectorized Multi-Agent Simulator (VMAS) benchmarks. It outperformed the state-of-the-art HetGPPO and IPPO algorithms in most scenarios, demonstrating superior performance in cooperative tasks.
Environments
- VMAS Flocking: Agents flock around a landmark, avoiding obstacles.
- MPE Simple Spread: Agents aim to occupy different landmarks.
- VMAS Reverse Transport: Agents push a package to a goal.
- VMAS Joint Passage: Agents navigate through a narrow passage.
- VMAS Navigation: Agents reach color-matched landmarks.
- VMAS Sampling: Agents collect rewards in a grid environment.
Empirical Results
CoHet variants (CoHetteam and CoHetself) consistently outperformed HetGPPO and IPPO in cooperative tasks. CoHetteam showed better performance in most scenarios, while CoHetself excelled in the MPE Simple Spread task.

CoHetteam vs. CoHetself
CoHetteam uses neighborhood dynamics models for intrinsic reward calculation, while CoHetself uses the agent’s own model. CoHetteam generally performed better in cooperative tasks, while CoHetself was advantageous in specific scenarios.

Reward Architecture Evaluation
The dynamics model loss decreased over time, indicating improved understanding of environmental dynamics. This led to a reduction in intrinsic reward penalties, demonstrating the effectiveness of the reward architecture.

Robustness to Increasing Number of Agents
CoHetteam maintained robustness with an increasing number of heterogeneous agents, as evidenced by consistent mean episodic rewards.

Conclusions and Future Work
CoHet introduces a novel GNN-based intrinsic reward mechanism for decentralized heterogeneous MARL. It enhances cooperation among agents in partially observable environments with sparse rewards. Future work could explore alternative intrinsic motivation types and different weighting mechanisms for predictions.

The CoHet algorithm represents a significant advancement in decentralized heterogeneous MARL, providing a robust framework for real-world multi-agent systems.


