





Authors:
Paper:
https://arxiv.org/abs/2408.09404
Introduction
Word co-occurrence networks (WCN) have garnered significant interest due to their potential applications in various linguistic and computational fields, such as semantic similarity, keyword extraction, and text summarization. Understanding the structure of these networks is crucial for leveraging their full potential. Previous studies have shown that WCNs built from well-formed texts exhibit certain properties, including being small-world, following a two-regime power law distribution, and being generally disassortative. Conversely, WCNs constructed from ill-formed texts, such as microblog posts, display different characteristics, such as being scale-free and following a power law distribution.
However, these observations have primarily been made in the context of the English language. This study aims to investigate whether these properties are universal across different languages and whether similar characteristics can be observed in word similarity networks (WSN). Specifically, this research focuses on Taiwan Mandarin texts, comparing WCNs and WSNs derived from ill-formed internet forum posts and well-formed judicial judgments.
Related Work
Word Co-occurrence Networks
Previous studies have established that WCNs built from well-formed texts exhibit small-world properties, follow a two-regime power law distribution, and are generally disassortative. These networks have been extensively studied in the context of English texts, revealing consistent structural properties.
Ill-formed Texts
Research on WCNs derived from ill-formed texts, such as microblog posts, has shown that these networks are also small-world and disassortative but differ in their degree distribution, being scale-free and following a power law distribution. However, these studies have primarily focused on English texts, leaving a gap in understanding whether these properties are universal across languages.
Word Similarity Networks
While WCNs have been extensively studied, WSNs have received less attention. This study aims to fill this gap by comparing the structural properties of WCNs and WSNs derived from both ill-formed and well-formed Taiwan Mandarin texts.
Research Methodology
Data Collection
The study collected data from two sources:
1. PTT Data: 139,578 posts from the Gossiping, Food, and HatePolitics forums on PTT, including comments, resulting in a total of 4,148,879 texts.
2. Judicial Judgment Data: 53,272 judgments from Taiwanese courts between 2004 and 2008, segmented into 4,017,811 texts.
Data Preprocessing
The texts were preprocessed by converting numbers to 0, converting alphabets to lowercase, and removing non-Mandarin characters. The preprocessed texts were then segmented using the CKIP segmentation system.
Word Embedding
Word similarities were obtained using a skip-gram word2vec model trained separately for the PTT and judicial judgment data, with a window size of 10 and vector sizes of 500. Only words with more than three occurrences were included in the vocabularies.
Network Building
Four networks were constructed:
1. WCN-P: Word co-occurrence network for PTT data.
2. WSN-P: Word similarity network for PTT data.
3. WCN-J: Word co-occurrence network for judicial judgment data.
4. WSN-J: Word similarity network for judicial judgment data.
To reduce computational load, only 1/10 of the vocabulary was randomly selected for network building. For WCNs, word co-occurrence was determined by the presence of two words in the same text. For WSNs, a similarity threshold was set at the 99th percentile, and words were considered similar if their similarity exceeded this threshold.
Experimental Design
Degree Distribution
The degree distributions of the four networks were assessed by fitting them to power law and two-regime power law models. The goodness of fit was evaluated using sums of squared residuals (SSR) and Akaike Information Criterion (AIC).
Small-world Property
The small-world property was determined by comparing the average clustering coefficients (CC) of the target networks with those of Erdos-Renyi (ER) random networks. A network is considered small-world if its CC is significantly larger than that of an ER random network.
Assortativity
Assortativity was measured using the degree assortativity coefficient (DAC), which indicates the tendency for nodes to connect with nodes of similar or different degrees. A positive DAC indicates assortativity, a negative DAC indicates disassortativity, and a DAC close to zero indicates a random distribution.
Results and Analysis
Degree Distribution
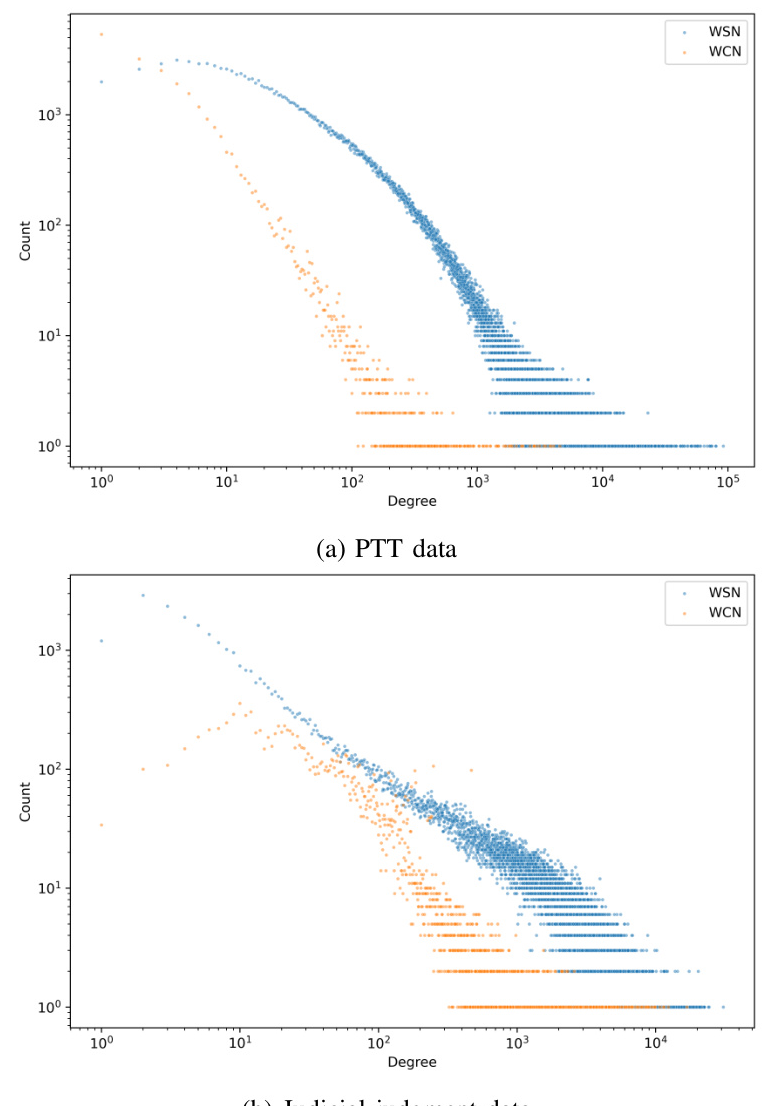
The degree distributions of the four networks are illustrated in Figure 1.


The results indicate that while WCN-P is straightforwardly scale-free, the other three networks are ambiguous between power law and two-regime power law distributions. However, goodness-of-fit results show that all four networks are generally scale-free, as indicated by lower SSR and AIC values for the power law models (Table II).

Small-worldness
The clustering coefficients for the four networks are listed in Table III, showing that all four networks possess small-world properties.
Assortativity
The degree assortativity coefficients for the four networks are listed in Table IV. The negative DAC values suggest general disassortativity, with WSN-J being relatively neutral. WCN networks are generally more disassortative than WSN networks for both well-formed and ill-formed data.

Overall Conclusion
Degree Distribution for Networks Based on Ill-formed and Well-formed Data
The study found that the scale-free property is not exclusive to networks derived from ill-formed texts. Judicial judgment data, which is well-formed, also exhibited scale-free properties. This suggests that the scale-free property may be related to the specificity of the texts rather than their well-formedness.
Universality of the Three Parameters
The analysis showed that the structural properties of WCNs and WSNs for Taiwan Mandarin texts are similar to those observed in previous studies on English texts. This indicates that these characteristics are universal across languages and potentially shared among different network types.
Potential Different Tendencies of Word Similarity Networks
While both WCNs and WSNs demonstrated similar properties, WSNs exhibited smaller clustering coefficients and DAC values closer to zero, indicating less significant small-worldness and disassortativity compared to WCNs. Further research is needed to determine whether these discrepancies are consistent across different types of texts.
In summary, this study provides valuable insights into the structural properties of word co-occurrence and word similarity networks for Taiwan Mandarin texts, highlighting the universality of these properties across languages and network types.


