





Authors:
Joanito Agili Lopo、Marina Indah Prasasti、Alma Permatasari
Paper:
https://arxiv.org/abs/2408.08805
Introduction
The advent of powerful Large Language Models (LLMs) like ChatGPT has revolutionized various domains, including education. These models have been effectively used in teacher-student collaborations, virtual tutoring, personalized learning experiences, and intelligent tutoring. However, the deployment of such models in educational dialogue systems presents challenges, such as delivering accurate and contextually appropriate responses consistently. Additionally, the large size of these models makes them impractical for many researchers and practitioners due to high memory consumption and slow generation times.
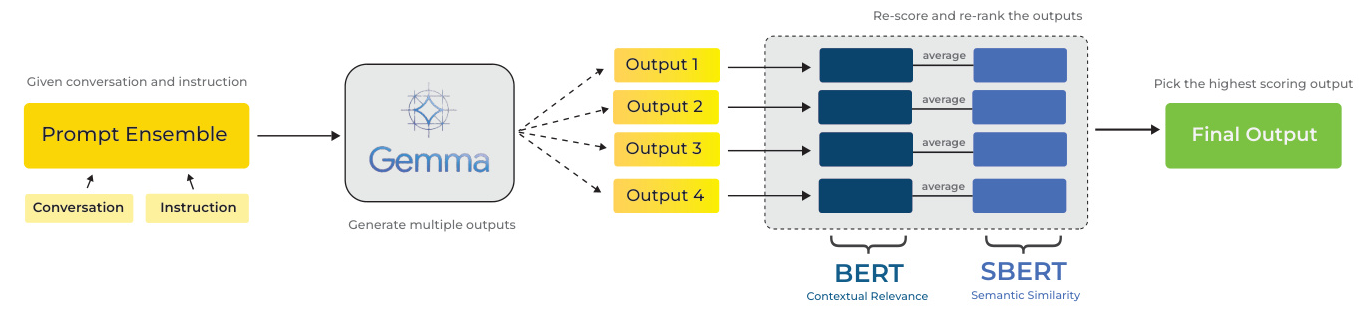
To address these challenges, the study introduces CIKMar, an efficient approach to educational dialogue systems powered by the Gemma Language model. By leveraging a Dual-Encoder ranking system that incorporates both BERT and SBERT models, CIKMar aims to deliver highly relevant and accurate responses while maintaining a smaller model size.
Related Work
Previous research has explored various approaches to enhance the performance of language models in educational contexts. Techniques such as Actor-Summarizer Hierarchical (ASH) prompting, role-play prompting, and modifying prompt structures have shown significant improvements in LLM performance. In the educational domain, models like GPT-3 and GPT-4 have been used to generate dialogue responses with high BERTScore results using hand-written zero-shot prompts.
Fine-tuning methods, such as the LoRa method and reinforcement learning via the NLPO algorithm, have also proven effective. However, these methods require high computational power. To address this, techniques like semantic in-context learning and knowledge distillation have been proposed to reduce LLM sizes while maintaining competitive performance.
CIKMar builds on these approaches by using the Gemma 1.1 IT 2B model, which is efficient and suitable for real-world applications. The system employs a Dual-Encoder strategy to rerank candidate outputs generated by the model using hand-written prompts, aiming to increase the relevance and effectiveness of responses in educational dialogues.
Methods
Data
The study uses data from the BEA 2023 shared task, sourced from the Teacher-Student Chatroom Corpus (TSCC). This corpus consists of conversations where an English teacher interacts with a student to work on language exercises and assess the student’s English proficiency. The dataset includes a training set of 2,747 conversations, a development set of 305 conversations, and a test set of 273 conversations.
Prompt Ensemble
Hand-written prompts from previous research were utilized to build the system. These prompts include Zero-shot and Few-shot types, targeting both general and specific scenarios. The prompts were tailored for teacher responses and continuations, ensuring general applicability to other datasets or conversations.
Gemma Instruct-tuned Model
The main system leverages the Gemma 1.1 IT 2B model, a 2-billion parameter open model developed by Google for efficient CPU and on-device applications. The model has shown strong performance across academic benchmarks for language understanding, reasoning, and safety. The study followed the instruction-formatted control tokens suggested in the Gemma technical report to avoid out-of-distribution and poor generation.
Dual-Encoder Reranking
The system generates multiple candidate outputs from different manually designed prompts and reranks these outputs using a heuristically defined scoring function. Specifically, SBERT and BERT models are used to average cosine similarity scores from their embeddings to assess fine-grained semantic relevance and context-response matching. The candidates are ranked based on these combined similarity scores in descending order.
Post-processing
The raw outputs from the model often included inconsistent formatting. A post-processing step was implemented to standardize these outputs by removing unwanted initial phrases and retaining only the relevant text. This step ensured that the final responses were concise and contextually appropriate.
Result & Analysis
Main Result
The main results, presented in Table 2, showcase comparisons among systems from the BEA Shared Task 2023, ranked primarily by BERTScore. CIKMar demonstrates competitive performance against baseline systems like NAISTeacher and Adaio, achieving a robust recall score of 0.70 and an F1-Score of 0.70. This indicates that the Dual-Encoder ranking effectively retrieves many contextually relevant responses compared to the reference answer.


Evaluation Metrics
To ensure the reliability of the approach, word overlap-based metric ROUGE and the neural network-based metric Dialog perplexity were employed. The ROUGE scores suggest that the system stays on-topic and uses relevant vocabulary, beneficial for educational content. However, challenges in maintaining coherence and well-structured responses were noted.

In-depth Output Analysis
A manual inspection of the model’s outputs revealed that the model sometimes struggled with teacher continuation problems and dialogues with minimal context. The contributions of each prompt to the final output were also analyzed, with Prompt 1 significantly influencing the final output in many examples.

Dual Encoder Effect
A manual investigation assessed the dual encoder’s impact on selecting the best candidates. The Dual-Encoder was found to avoid the pitfalls of distance-measurement-only, enhancing the model’s consideration of contextual relevance and semantic similarity between dialogues and responses.

Conclusion & Future Work
CIKMar, an educational dialogue generation approach using prompts and a Dual-Encoder ranking with the Gemma language model, yields promising results in educational settings. By utilizing the Gemma 2B model, the system maintains high performance in response relevance and accuracy with a smaller, more accessible model. However, limitations such as the Dual-Encoder prioritizing theoretical discussion over practical contextual responses were identified.
Future research should explore scenarios where either SBERT or BERT dominates ranking scores. Additionally, crafting more specific prompts is crucial for deeper contextual understanding in educational dialogues. Lastly, refining the Gemma model to focus on educational contexts and adapt to shifting conversation dynamics is recommended.


