





Authors:
Jie Wang、Jin Wang、Xuejie Zhang
Paper:
https://arxiv.org/abs/2408.09177
Introduction
Metaphors are a fundamental aspect of human language, enabling nuanced and creative expression. Recognizing and understanding metaphors is crucial for machines to achieve human-like language comprehension. Traditional methods for metaphor identification often rely on pre-trained models, which struggle with metaphors where the tenor (subject) or vehicle (comparative element) is not explicitly mentioned. This study introduces a multi-stage generative heuristic-enhanced prompt framework to improve the ability of Large Language Models (LLMs) in recognizing tenors, vehicles, and grounds in Chinese metaphors.
Related Work
Automated Metaphor Identification
Previous research has primarily treated metaphor identification as a sequence labeling task using architectures like BiLSTM and Transformer-based models such as BERT and RoBERTa. These models have shown significant success in various natural language processing tasks. However, they often require substantial computational resources and data, and their reasoning processes can be opaque.
Metaphor Recognition with LLMs
Recent studies have begun leveraging LLMs to identify and generate metaphors by constructing examples based on metaphor theory. These approaches aim to guide LLMs through the reasoning process of metaphor understanding via dialogue interactions.
Instruction Tuning
Chain-of-Thought (CoT) prompting techniques have been used to decompose complex reasoning tasks into intermediate steps, improving LLM performance. This study employs the Auto-CoT paradigm to automatically construct demonstrations with questions and reasoning chains.
Research Methodology
Task Description
The NLPCC-2024 Shared Task 9 focuses on generating Chinese metaphors by identifying the ground or vehicle in the metaphoric relation. It is divided into two subtasks:
- Subtask 1: Metaphor Generation – Creating a metaphor from a provided tuple consisting of TENOR, GROUND, and VEHICLE.
- Subtask 2: Metaphor Components Identification – Extracting TENORS, GROUNDS, and VEHICLES from a symbolic sentence.
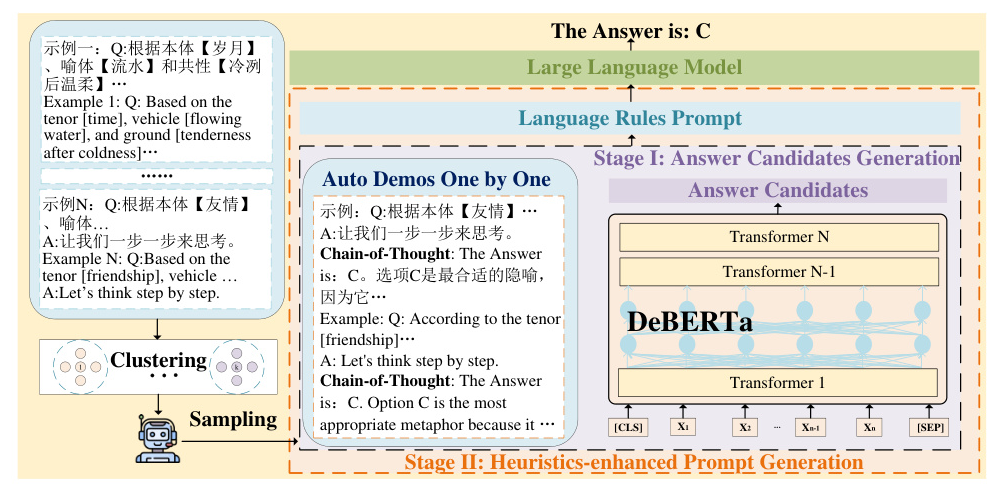
Stage I: Answer Candidates Generation
The DeBERTa model is used to generate answer candidates. Each input sequence includes a question and a list of options, which are embedded and processed to calculate confidence scores for each option. The cross-entropy loss function is used to optimize the model during training.


Stage II: Heuristics-enhanced Prompt Generation
Question Clustering
Questions are clustered using the k-means algorithm based on their vector representations computed by DeBERTa. The optimal number of clusters is determined using the elbow rule.
Demonstration Sampling
Examples are selected based on the shortest encoding length for the question and the consistency of the chain-of-thought reasoning with the correct answer. These demonstrations are combined with the test question to form a heuristic-enhanced prompt.
Experimental Design
Dataset and Evaluation Metrics
The dataset includes a training set of 34,463 metaphorical sentences with annotated tenors, vehicles, and grounds, and two validation sets of 500 sentences each. Accuracy is used to evaluate model performance across two tracks:
- Track 1: LLMs track – Encourages using large models to generate options directly.
- Track 2: Rule-based track – Encourages using traditional language rules or machine learning methods to compare and conclude options.
Implementation Details
Qwen2-plus is chosen as the LLM for response generation due to its high-quality Chinese responses. The DeBERTa model uses the IDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese checkpoint, with an AdamW optimizer and a learning rate of 2e-5. The neural ranker is trained for 5 epochs with a batch size of 1 and a weight decay of 0.01.
Results and Analysis
Empirical Results
The proposed method achieved high accuracy across all subtasks and tracks, ranking first in most categories. The results demonstrate the effectiveness of the multi-stage prompting framework in improving metaphor recognition.


Analysis and Discussion
Question Clustering and Demonstration Sampling
The k-means clustering algorithm effectively grouped questions, with the optimal number of clusters determined using the elbow method. Various methods for selecting examples were tested, with the shortest question length yielding the best results.

Direct Response Provision to LLMs
Providing direct answers to LLMs, such as DeBERTa predictions, did not significantly improve performance. Instead, the heuristic-enhanced prompts proved more effective.





Overall Conclusion
This study presents a multi-stage generative heuristic-enhanced prompt framework for Chinese metaphor recognition using LLMs. The proposed method effectively identifies tenors, vehicles, and grounds in metaphors, achieving high accuracy in the NLPCC-2024 Shared Task 9. The results highlight the potential of LLMs in understanding and generating metaphors, paving the way for more advanced natural language processing applications.


