





Authors:
Alimjan Mattursun、Liejun Wang、Yinfeng Yu
Paper:
https://arxiv.org/abs/2408.06851
Introduction
In the realm of speech processing, background noise and room reverberation pose significant challenges, degrading the clarity and intelligibility of speech. This degradation impacts various applications such as conferencing systems, speech recognition systems, and speaker recognition systems. Speech enhancement (SE) tasks aim to extract clean speech from noisy environments, thereby improving speech quality and intelligibility. Recently, deep neural network (DNN) models have shown superior denoising capabilities in complex noise environments compared to traditional methods. This study introduces a novel cross-domain feature fusion and multi-attention speech enhancement network, termed BSS-CFFMA, which leverages self-supervised embeddings to achieve state-of-the-art (SOTA) results.
Related Work
SSL Model
Self-supervised learning (SSL) models can be categorized into generative modeling, discriminative modeling, and multi-task learning. Generative modeling reconstructs input data using an encoder-decoder structure, while discriminative modeling maps input data to a representation space and measures the corresponding similarity. Multi-task learning involves learning multiple tasks simultaneously, extracting features useful for all tasks through shared representations. In this study, two base SSL models, Wav2vec2.0 (Base) and WavLM (Base), are utilized to extract latent representations.
Cross Domain Features and Fine Tuning SSL
Previous studies have shown that cross-domain features improve the performance of automatic speech recognition (ASR) and speech enhancement (SE). SSL has demonstrated great potential in SE tasks, with methods like weighted sum SSL and fine-tuning significantly enhancing performance. This study employs SSL and Speech Spectrogram as two cross-domain features, using a weighted summed SSL and a more efficient partially fine-tuned (PF) approach to further improve SE performance.
Method
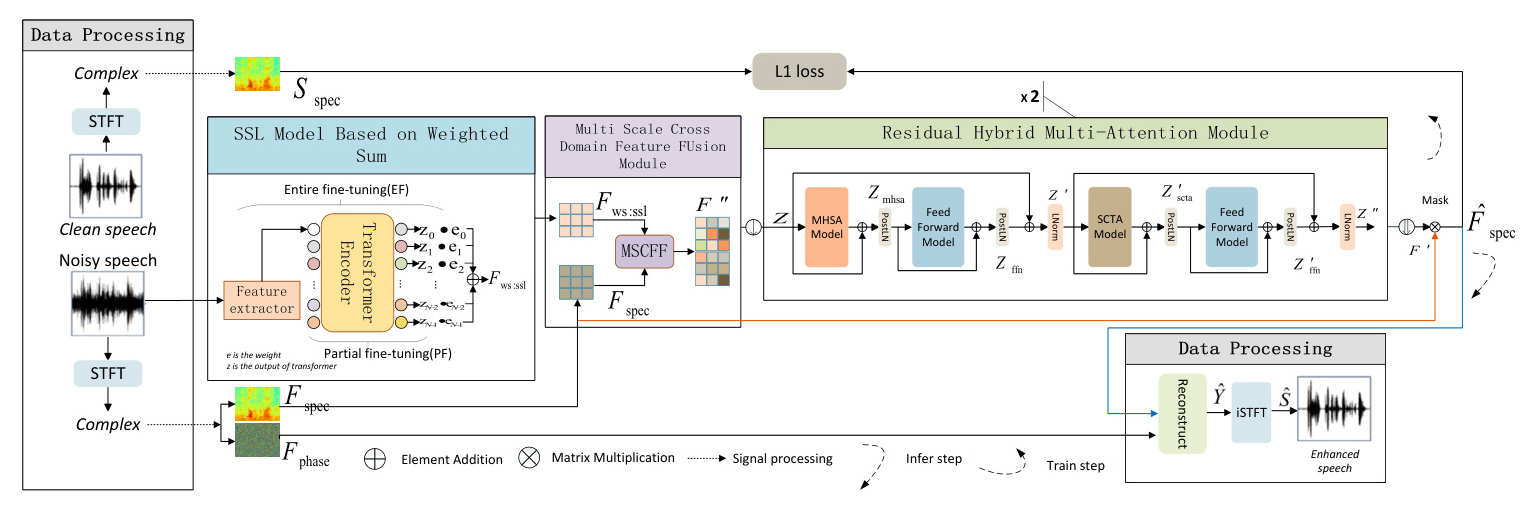
The BSS-CFFMA architecture comprises an SSL model with weighted summation, a multi-scale cross-domain feature fusion (MSCFF) module, and two residual hybrid multi-attention (RHMA) modules. The overall architecture is illustrated in Fig. 1 

SSL Model based on Weighted Sum
Using the last layer of SSL directly may result in the loss of some local information necessary for speech reconstruction tasks in deeper layers. Therefore, a learnable parameter ( e(i) ) is designed for each transformer layer’s output ( z(i) ) in SSL:
[ F_{ws:ssl} = \sum_{i=0}^{N-1} [e(i) \cdot z(i)] ]
Multi Scale Cross Domain Feature Fusion (MSCFF)
The MSCFF module better integrates and extracts information from SSL and spectrogram features, addressing issues of SSL information loss and insufficient feature fusion. The architecture of the MSCFF model is illustrated in Fig. 2 
Residual Hybrid Multi-Attention (RHMA) Model
The RHMA module incorporates a selective channel-time attention fusion module (SCTA) using a self-attention design to obtain different attention feature representations and achieve improved speech enhancement. The structure of the RHMA module is shown in Fig. 1
Selective Channel-Time Attention Fusion (SCTA) Module
The SCTA module consists of two components: selective channel-attention fusion (SCA) and selective time-attention fusion (STA). The structure of the SCA and STA blocks are shown in Fig. 3 

Experiment
Dataset
The performance of BSS-CFFMA was evaluated on the VoiceBank-DEMAND and WHAMR! datasets. The VoiceBank-DEMAND dataset consists of 11572 utterances, while the WHAMR! dataset includes noise and reverberation, simulating typical home and classroom environments.
Evaluation Metrics
The following metrics were selected to evaluate the performance of BSS-CFFMA: wideband perceived assessment of speech quality (WB-PESQ), narrowband perceived assessment of speech quality (NB-PESQ), scale-invariant source-to-noise ratio (SI-SNR), short-time objective intelligibility (STOI), speech signal distortion prediction (CSIG), background noise invasion prediction (CBAK), overall performance prediction (COVL), and real-time factor (RTF).
Experimental Setup
All speech signals were downsampled to 16 kHz and randomly selected for training 100 rounds with a duration of 2.56 seconds. The STFT and ISTFT parameters were set as follows: FFT length is 25 ms, window length is 25 ms, and hop size is 10 ms. Batch size ( B ) was set to 16. The Adam optimizer and dynamic learning rate strategy were used, with the learning rate for SSL fine-tuning set to ( 0.1 \times \text{learning-rate} ). Training was conducted using two Precision T4 GPUs, with an average training time of approximately 7 minutes per epoch.
Results
Performance Comparison on Two Datasets
The denoising performance of BSS-CFFMA was compared with 14 baseline methods on the VoiceBank-DEMAND dataset. The results, shown in Table I 
The denoising, dereverberation, and joint denoising-dereverberation performance of BSS-CFFMA were evaluated under three test scenarios on the WHAMR! dataset. The results, shown in Table II 
Ablation Analysis
Ablation experiments were conducted to validate each module. The results, shown in Table III 

Conclusions
The BSS-CFFMA model for single-channel speech enhancement demonstrates its effectiveness, outperforming other baseline models. However, the performance seems to reach a plateau, attributed to challenges in phase processing. Future work will focus on the computation and optimization of phases to further improve the model’s performance.




