





Authors:
Zhiwei Xu、Hangyu Mao、Nianmin Zhang、Xin Xin、Pengjie Ren、Dapeng Li、Bin Zhang、Guoliang Fan、Zhumin Chen、Changwei Wang、Jiangjin Yin
Paper:
https://arxiv.org/abs/2408.09501
Introduction
Background
Cooperative Multi-Agent Reinforcement Learning (MARL) has seen significant advancements and applications in various domains such as online ride-hailing platforms, drone swarm management, and energy system scheduling. However, a persistent challenge in MARL is the partial observability of the environment, where agents only have access to local observations. This limitation hinders their ability to make optimal decisions during decentralized execution.
Problem Statement
In partially observable Markov decision processes (POMDPs), the absence of global state awareness during execution can impede the agents’ ability to make optimal choices. Traditional methods like Recurrent Neural Networks (RNNs) and representation learning techniques have attempted to address this issue but have not fully leveraged the global state during decentralized execution.
Proposed Solution
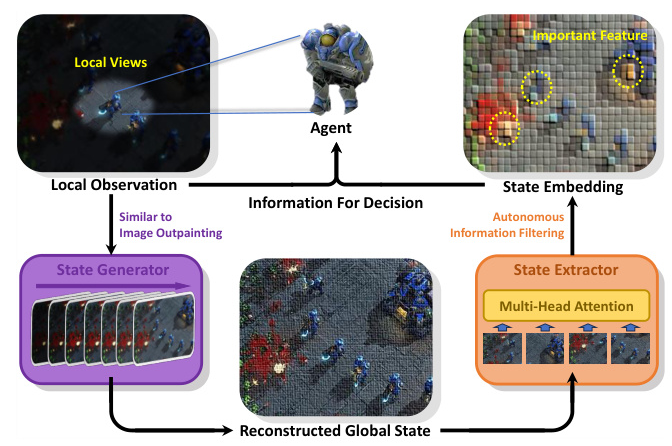
Inspired by image outpainting, this study proposes the State Inference with Diffusion Models (SIDIFF) framework. SIDIFF uses diffusion models to reconstruct the original global state based solely on local observations. The framework consists of a state generator and a state extractor, enabling agents to make decisions by considering both the reconstructed global state and local observations. SIDIFF can be seamlessly integrated into existing MARL algorithms to enhance their performance.
Related Work
Partially Observable Problems
In both single-agent and multi-agent scenarios, POMDPs require agents to make decisions based on incomplete information. Popular approaches to mitigate this issue include:
- Recurrent Neural Networks (RNNs): Methods like DRQN, R-MADDPG, QMIX, and MAPPO use RNNs to integrate local observation data over time, providing agents with a form of long-term memory.
- Belief Tracking: Techniques like particle filters require predefined models to track beliefs about the global state.
- Generative Models: Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) have been used to generate latent state representations.
- Communication Methods: Agents exchange information to mitigate the need for global information, though this incurs high communication costs.
Diffusion Models for Reinforcement Learning
Diffusion models, known for generating diverse data and capturing multimodal distributions, have been integrated into reinforcement learning to improve performance and sample efficiency. These models have been used for:
- Fitting Environment Dynamics: Serving as planners to generate trajectories that align with environmental dynamics.
- Data Augmentation: Acting as data synthesizers in offline reinforcement learning.
- Direct Policy Implementation: Addressing challenges like over-conservatism and limited adaptability in offline settings.
However, most studies have focused on offline settings or single-agent tasks. SIDIFF, in contrast, targets online multi-agent tasks, explicitly addressing partial observability challenges.
Research Methodology
State Generator
The state generator module models data distribution using the diffusion model, similar to image outpainting tasks. It is based on the U-Net architecture and consists of an encoder and a decoder. The encoder extracts contextual state information, while the decoder reconstructs the original state using skip-connection techniques to merge feature maps from the encoder with those in the decoder.
The state generator integrates time-sensitive data, unique identifiers for each agent, and trajectory history to ensure the uniqueness of conditions used to generate the state. The training and sampling regimen closely resemble traditional diffusion models, with the goal of predicting the noise introduced in the forward process rather than directly reconstructing the original global state.
State Extractor
The state extractor module extracts decision-relevant information from the inferred global state. Inspired by the Vision Transformer (ViT), the global state is divided into fixed-size 1D patches, which are then arranged in sequence with position embeddings. These vectors serve as input to the Transformer model, which uses multi-head attention to derive the abstracted feature embedding for the global state. This embedding is concatenated with the agent’s local observation and fed into the agent network.
Unlike other studies that replace the global state with low-dimensional embeddings, the state extractor is directly optimized end-to-end by the reinforcement learning process, allowing agents to actively select information conducive to their decision-making.
Experimental Design
Platforms and Scenarios
SIDIFF was evaluated on three experimental platforms: SMAC, VMAS, and the newly proposed Multi-Agent Battle City (MABC). These platforms feature partial observability and diverse scenarios for evaluating cooperation between agents.
SMAC (StarCraft Multi-Agent Challenge)
SMAC is a cooperative MARL environment based on StarCraft II, where agents select actions based on local observations within their visual field. The goal is to command allied units to eliminate enemy units controlled by built-in heuristic algorithms.
VMAS (Vectorized Multi-Agent Simulator)
VMAS is an open-source framework for efficient MARL benchmarking, featuring a vectorized 2D physics engine and a collection of challenging multi-agent scenarios. Agents can only observe their own positions and information related to their specific goals.
MABC (Multi-Agent Battle City)
MABC is a novel experimental platform inspired by the classic video game Battle City. In this environment, agents only have access to local observations, and scenarios can be flexibly customized. A specific 2 vs 8 scenario was designed to demonstrate the importance of the global state in decision-making.
Results and Analysis
SMAC Performance
SIDIFF was applied to the value decomposition method QMIX and compared with other baselines. The results indicate that SIDIFF enhances the performance of the original algorithm, outperforming QMIX in nearly all tasks. In more challenging tasks, SIDIFF significantly outperformed other baselines, demonstrating the effectiveness of reconstructing the global state within the original state space.


VMAS Performance
SIDIFF was applied to VDN and MAPPO algorithms, representing value decomposition and multi-agent policy gradient approaches, respectively. The SIDIFF variants outperformed the original algorithms across three representative scenarios, demonstrating that SIDIFF can be easily applied to various algorithms to improve their performance.

MABC Case Study
In the 2 vs 8 scenario, agents controlled by SIDIFF were able to perceive changes in the global state and avoid falling into local optima. They prioritized attacking or drawing away enemy tanks that posed a significant threat to the base, demonstrating the importance of the global state in decision-making.

Ablation Study and Visualization
Ablation experiments showed that both the state generator and state extractor components in SIDIFF are essential. Visualizations of the actual state sequence and the states reconstructed by the agents demonstrated that the state generator effectively allows agents to infer the global state based solely on local observations.

Overall Conclusion
SIDIFF addresses the issue of agents being unable to access the global state during decentralized execution in Dec-POMDP tasks. The state generator reconstructs the global state based on the agents’ trajectory history, while the state extractor processes the reconstructed global state to extract decision-relevant information. These components work together to provide superior performance in various cooperative multi-agent environments.
The introduction of MABC as a novel multi-agent experimental environment allows for flexible customization of scenarios, encouraging further contributions from the MARL community. Future work will explore the application of SIDIFF in multi-task multi-agent scenarios and the use of faster generative diffusion models to improve inference efficiency.



