





Authors:
Chengzhi Zhong、Fei Cheng、Qianying Liu、Junfeng Jiang、Zhen Wan、Chenhui Chu、Yugo Murawaki、Sadao Kurohashi
Paper:
https://arxiv.org/abs/2408.10811
Introduction
Large Language Models (LLMs) have revolutionized the field of Natural Language Processing (NLP), predominantly focusing on the English language. However, the performance of these English-centric models often declines when applied to non-English languages, raising concerns about cultural biases and language representation. This study, conducted by researchers from Kyoto University, the National Institute of Informatics, and the University of Tokyo, delves into the internal workings of non-English-centric LLMs to understand the language they ‘think’ in during intermediate processing layers.
Related Work
Multilingual Large Language Models
The development of multilingual LLMs has been a significant focus in recent years. Models like GPT-4, Gemini, and Llama-2 are primarily trained on English-centric corpora. Researchers have explored various methods to enhance these models’ multilingual capabilities, such as continued pre-training with second-language data and training with bilingual data from the outset. Notable examples include Swallow, which is based on Llama-2 and undergoes continued pre-training in Japanese, and LLM-jp, which is trained on balanced English and Japanese corpora.
Mechanistic Interpretability
Mechanistic interpretability aims to understand how machine learning models work by analyzing their internal components. Techniques like the logit lens and tuned lens focus on decoding the probability distribution over the vocabulary from intermediate vectors, aiding in comprehending how models generate text in target languages. Previous studies have shown that English-centric models like Llama-2 have an abstract “concept space” closer to English than other languages, influencing their performance on multilingual tasks.
Research Methodology
Overview
The study investigates the internal latent languages of three types of models used for Japanese processing: Llama-2 (an English-centric model), Swallow (an English-centric model with continued pre-training in Japanese), and LLM-jp (a model pre-trained on balanced English and Japanese corpora). The logit lens method is employed to un-embed each layer’s latent representation into the vocabulary space, allowing the researchers to analyze the language distribution in intermediate layers.
Logit Lens
The logit lens method converts hidden vectors into tokens by projecting them onto the vocabulary dimensions using an unembedding matrix. This method helps obtain the predicted token probability distribution from the intermediate layers, providing insights into the internal language representation of the models.
Measuring Multi-token Sequence Probability
Given the complexity of Japanese and Chinese writing systems, the study extends single-token analysis to multi-token analysis. This approach ensures a more precise expression by calculating the generation probability of a token sequence in the intermediate layers.
Categorization of Multilingual Large Language Models
The models are categorized into three types based on their training corpora:
1. English-Centric Models: Primarily trained on English data (e.g., Llama-2).
2. Multilingual CPT Models: Built upon an English-centric model with continued pre-training in a second language (e.g., Swallow).
3. Balanced Multilingual Models: Trained on roughly equal amounts of tokens from two or more languages (e.g., LLM-jp).
Experimental Design
Dataset Construction
The dataset includes parallel phrases in English, French, Japanese, and Chinese, along with their corresponding descriptions. The models are tested on three tasks: translation, repetition, and cloze tasks. The prompts are designed to minimize unnecessary interference and ensure consistency across tasks.
Experiment Settings
The study uses the 13B size of Llama-2, Swallow, and LLM-jp-v2.0 models for fair comparison. The dataset contains 166 parallel phrases, and the experiments are conducted to analyze the internal latent language behaviors of the models when processing Japanese and non-dominant languages.
Results and Analysis
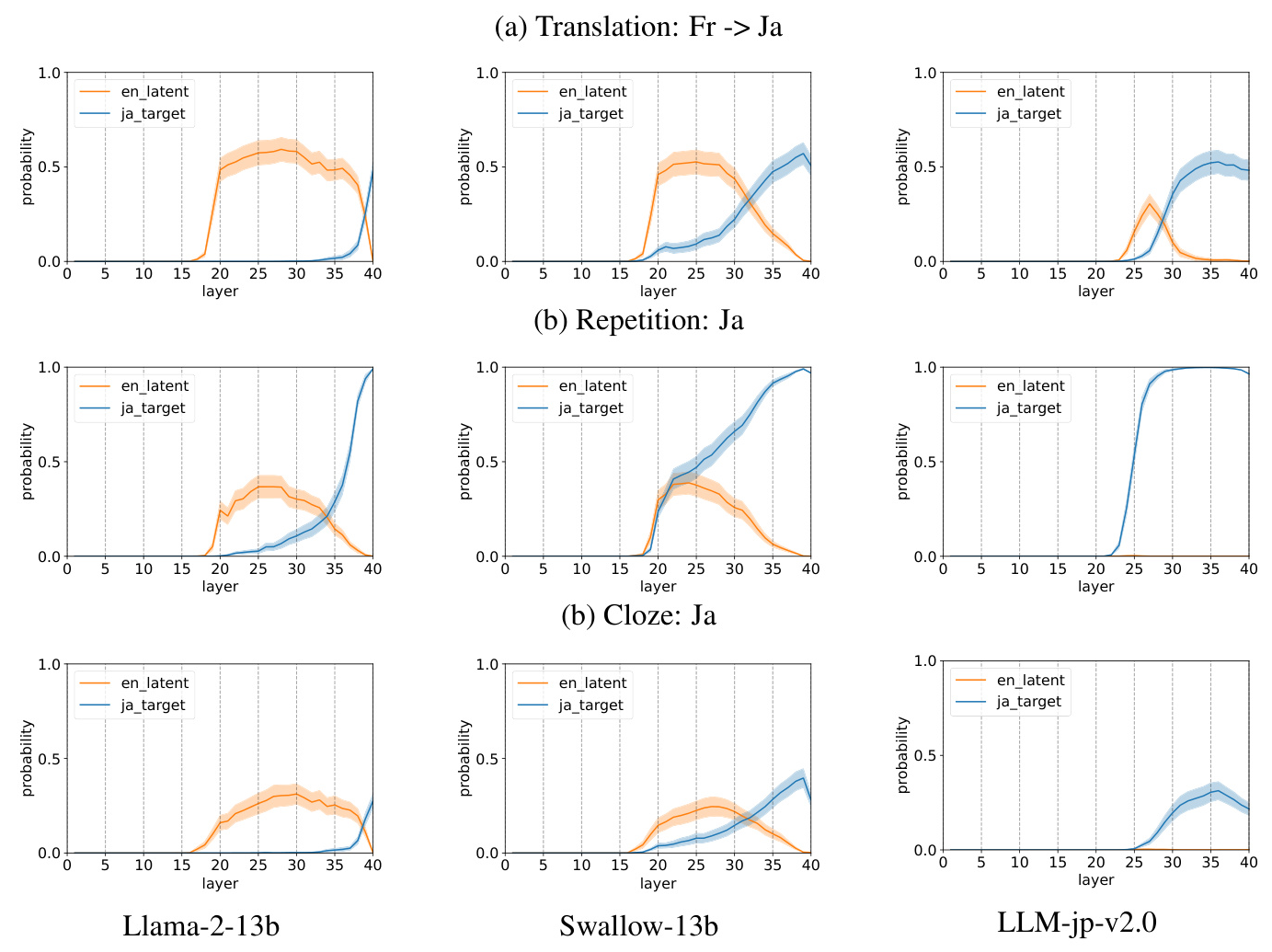
Main Experiment 1: Analysis on Specific Dominant Language – Japanese
The study compares the internal latent language behaviors of Llama-2, Swallow, and LLM-jp when processing Japanese. The results show that Llama-2 uses English as the internal latent language, while Swallow and LLM-jp exhibit a noticeable probability of Japanese in their intermediate layers. This indicates that Japanese-specific models lean towards utilizing Japanese as the latent language when processing Japanese.


Main Experiment 2: Analysis on Non-Dominant Languages
The study further investigates the internal latent language used when processing non-dominant languages like French and Chinese. The results show that Llama-2 consistently uses English as the internal pivot language, while Swallow and LLM-jp exhibit dual internal latent languages. The internal latent language distribution in Swallow includes both English and Japanese, while LLM-jp tends to favor the language more closely related to the target language.

Cultural Conflict QA
The study explores how the models handle questions with different answers in different cultural contexts. The results show that Llama-2’s English-dominant intermediate layers prefer answers based on American cultural context, while Swallow and LLM-jp align more closely with the target language’s cultural context.

Semantic and Language Identity Dimensions
The study investigates whether semantic and language identity dimensions can be recognized in the models. The results suggest that language identity dimensions can be distinguished, serving the role of representing languages, while semantic dimensions are dense and shared across languages.

Overall Conclusion
This study provides valuable insights into the internal language representation of non-English-centric LLMs. The findings reveal that Japanese-specific models like Swallow and LLM-jp utilize Japanese as their internal latent language when processing Japanese. When dealing with non-dominant languages, these models exhibit dual internal latent languages, favoring the language more closely related to the target language. The study also highlights the influence of cultural context on the models’ reasoning and the potential to distinguish semantic and language identity dimensions. These insights pave the way for future research to further explore the behavior and mechanisms of non-English-centric LLMs.



