





Authors: Thao Nguyen, Jeffrey Li, Sewoong Oh, Ludwig Schmidt, Jason Weston, Luke Zettlemoyer, Xian Li
ArXiv: http://arxiv.org/abs/2408.04614v1
Abstract:
We propose a new method, instruction back-and-forth translation, to construct high-quality synthetic data grounded in world knowledge for aligning large language models (LLMs). Given documents from a web corpus, we generate and curate synthetic instructions using the backtranslation approach proposed by Li et al.(2023a), and rewrite the responses to improve their quality further based on the initial documents. Fine-tuning with the resulting (backtranslated instruction, rewritten response) pairs yields higher win rates on AlpacaEval than using other common instruction datasets such as Humpback, ShareGPT, Open Orca, Alpaca-GPT4 and Self-instruct. We also demonstrate that rewriting the responses with an LLM outperforms direct distillation, and the two generated text distributions exhibit significant distinction in embedding space. Further analysis shows that our backtranslated instructions are of higher quality than other sources of synthetic instructions, while our responses are more diverse and complex than those obtained from distillation. Overall we find that instruction back-and-forth translation combines the best of both worlds — making use of the information diversity and quantity found on the web, while ensuring the quality of the responses which is necessary for effective alignment.
Summary:
The content discusses the use of large language models (LLMs) to respond to users’ queries through chat interfaces. The author found that the existing methods for creating instruction-response pairs used for training these models had some drawbacks, such as reliance on human annotations, noise in web data, and limited performance gains from data distillation.
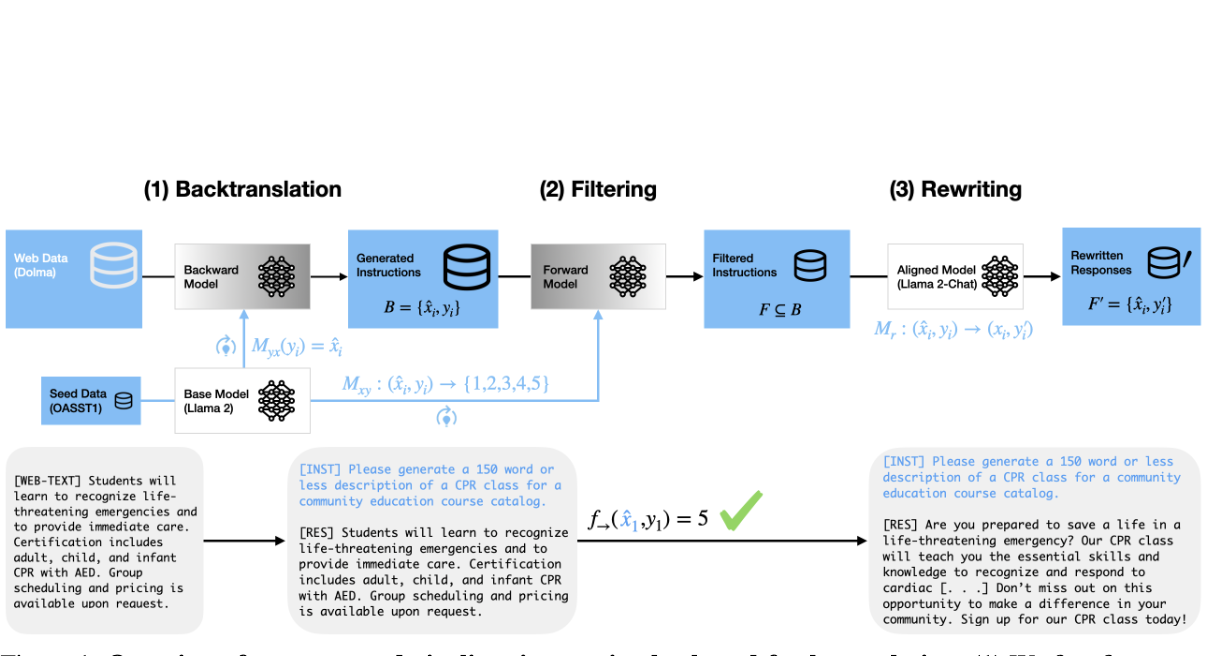
To address these issues, the author proposes a technique called “back-and-forth translation,” which involves generating instruction-response pairs from large-scale open-source documents rather than using more limited or expensive sources like ClueWeb. The author’s approach makes use of preprocessed documents from Dolma and backtranslation to create these pairs. However, since the raw HTML files from these sources don’t directly translate to structured responses, the author utilizes an LLM to rewrite the response based on the generated instruction and initial web text. This method helps to avoid overfitting to a specific LLM’s knowledge.
The results show that when the same amount of data is used, fine-tuning on the new instruction-response pairs improved the AlpacaEval win rate by 3.6% compared to previous work using backtranslation from ClueWeb. It also outperformed other existing distillation datasets by at least 3.2%. Fine-tuning on responses rewritten by the LLM instead of distilled responses led to better performance.
The content concludes that back-and-forth translation is an effective method to generate instruction-tuning data with a diverse range of information from the web while ensuring the quality of the response annotations through the use of aligned LLMs.
Thinking Direction:
1. How does the back-and-forth translation technique used for generating instruction-response data compare to existing methods such as distillation or backtranslation from web sources like ClueWeb?
2. What are the advantages of using an open-source corpus like Dolma for preprocessing documents compared to using paid-access corpora like ClueWeb?
3. How does fine-tuning an LLM, such as Llama-2-70B, on the instruction-response pairs generated through this method impact its performance on tasks like AlpacaEval, and how does it differ from fine-tuning on other dataset types?


