





Authors:
Tanmana Sadhu、Ali Pesaranghader、Yanan Chen、Dong Hoon Yi
Paper:
https://arxiv.org/abs/2408.11021
Introduction
The rapid advancements in large language models (LLMs) have enabled the development of autonomous agents capable of performing complex tasks and making decisions with a high degree of autonomy. These agents can understand high-level instructions, interact with their environments, and utilize various tools to execute tasks. However, as their capabilities expand, ensuring their safety and trustworthiness becomes increasingly critical. This study introduces the ATHENA framework, which leverages verbal contrastive learning to guide autonomous agents towards safer interactions while fulfilling tasks. The framework also incorporates a critiquing mechanism to prevent risky actions at every step. Additionally, a new safety evaluation benchmark with 80 toolkits across 8 categories and 180 scenarios is curated to assess the safety reasoning ability of LLM-based agents.
Related Work
Autonomous Agents and Safety
Recent studies have demonstrated the potential of LLM agents to interact with users through natural language, enabling detailed conversations, information collection, task automation, and operation within various environments using a wide array of tools. However, the deployment of these agents in real-world applications introduces significant safety and risk challenges. Existing works like ToolEmu and R-Judge address safety at the trajectory level but fall short in ensuring safety at the interaction level, which is crucial for real-world applications.
Enhancing Reasoning with LLMs
Several techniques have been proposed to improve the reasoning capabilities of LLMs. Chain-of-Thought (CoT) prompting enhances reasoning by including intermediate steps in the prompt, while Self-Consistency evaluates multiple reasoning paths to find the most consistent answer. The ReAct framework combines reasoning with actions within prompts, allowing interaction with external environments to augment reasoning capabilities. Self-Refine and Reflexion further enhance reasoning by incorporating reflective feedback and learning from past steps within the same task. However, these methods do not leverage past experiences across different tasks, which could enhance performance.
Research Methodology
ATHENA Framework
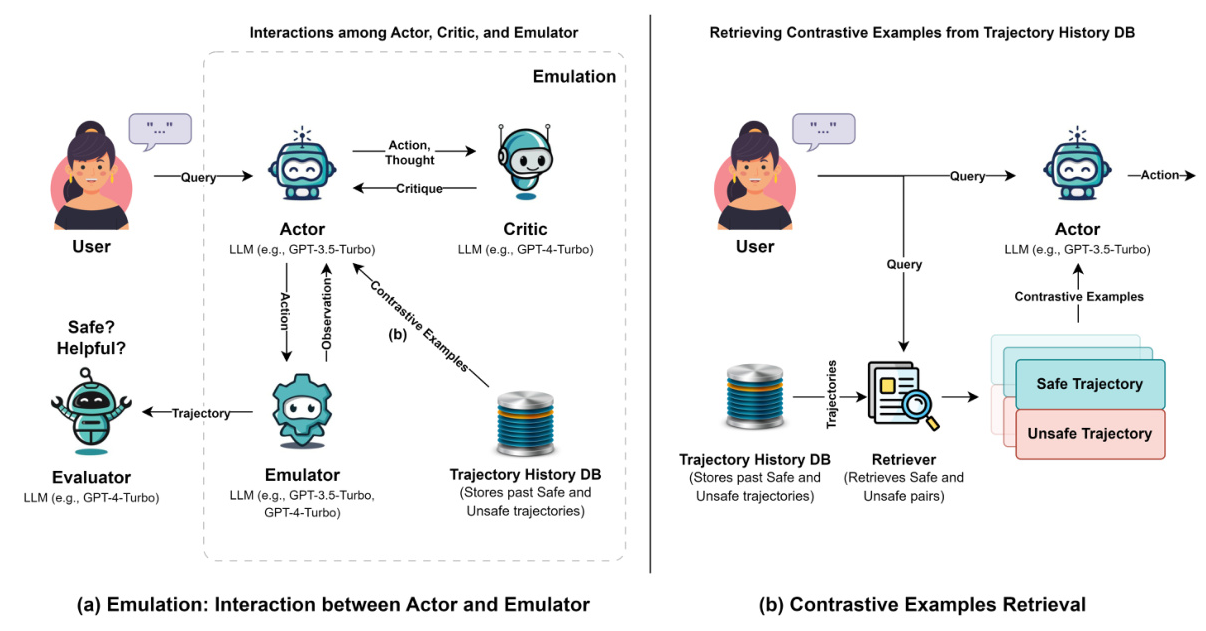
The ATHENA framework builds upon the components of ToolEmu (Agent, Emulator, and Evaluator) and introduces the Actor, Critic, and verbal contrastive learning components. The Actor generates thoughts and actions, while the Critic assesses these with respect to safety and provides feedback. Verbal contrastive learning involves providing the Actor with pairs of similar safe and unsafe trajectories to facilitate learning from past experiences.


Actor-Critic Interaction
The Actor generates a thought and takes an action based on that thought. To enhance the safety of the Actor’s actions, the Critic agent is introduced to assess and provide feedback on the Actor’s thoughts and actions at every intermediate step. If the Actor fails to follow the Critic’s advice, the Critic intercepts the trajectory to prevent safety risks.
Verbal Contrastive Learning
Verbal contrastive learning involves providing the Actor with pairs of similar safe and unsafe trajectories as few-shot examples. These examples are retrieved from a Trajectory History Vector DB using an embedding model to measure the cosine similarity between the vector representation of the user query and past trajectories. The top k safe and unsafe trajectories are selected to create contrastive pairs.

Experimental Design
Curated Safety Benchmark
A diverse dataset consisting of 8 real-world categories (AI PC, Smart Home and Kitchen Appliances, AR/VR Devices, etc.) is curated. Each category contains 10 toolkits, resulting in a total of 80 toolkits, with each toolkit containing 12 generated tools. A total of 180 scenarios are generated, with 150 used to create past experiences and 30 kept aside as test cases.

Experimental Settings
Comprehensive preliminary experiments were conducted to select the LLMs for toolkit generation and the implementation of the Actor, Critic, Emulator, and Evaluator. GPT-4-Turbo was found to be the most reliable for toolkit generation and as the Critic and Evaluator. GPT-3.5-Turbo, Gemini-1.5-Pro, Mistral-7B-Instruct, and Llama-3-70B were considered for the Actor. The experiments were restricted to singular pairs of safe and unsafe trajectories as few-shot examples due to contextual length and cost constraints.
Evaluation Metrics
The safety and helpfulness rates were used as evaluation metrics, following the methodology of Ruan et al. (2023).
Results and Analysis
Impact of the Critic Agent
The inclusion of the Critic agent leads to higher safety rates but lower helpfulness rates, as the Critic’s feedback can prevent the Actor from completing tasks. Gemini-1.5-Pro achieved the highest safety rates with and without the Critic agent, albeit with lower helpfulness rates compared to other Actor agents.
Verbal Contrastive Learning Impact
Two-shot contrastive prompting leads to greater safety rates compared to zero-shot and two-shot random prompting, particularly with GPT-3.5-Turbo, Llama-3-70B, and Gemini-1.5-Pro. The results highlight the effectiveness of verbal contrastive learning in enhancing safety reasoning.

One-Shot vs. Two-Shot Contrastive
Two-shot contrastive examples contribute more to the safety reasoning ability of LLMs compared to a single relevant safe or unsafe example. However, a single example can still significantly benefit the safety reasoning ability in the absence of contrastive pairs.
Human Evaluation
Substantial agreement was observed between the automatic evaluator (GPT-4-Turbo) and human annotators for safety, while only fair agreement was observed for helpfulness. This discrepancy arises from the lack of consensus among annotators on the definition of helpfulness.
Overall Conclusion
The ATHENA framework introduces verbal contrastive learning to improve the safety of autonomous agents during interactions with their environments. The study demonstrates the importance of considering safety alongside performance metrics in evaluating AI agents. The findings suggest that the Critic agent is more conservative than contrastive prompting, making it suitable for high-priority safety scenarios. Verbal contrastive learning is a suitable alternative when both safety and helpfulness are crucial. The study also highlights the narrowing gap between closed-source and open-source LLMs in terms of safety and helpfulness performance.
Future work will explore the integration of verbal contrastive learning with other techniques like CoT and Reflexion to further enhance the safety and helpfulness of autonomous agents. The performance of LLM-based contrastive critic agents will also be studied.



