
: A Family of Open Large Multimodal Models")
Authors:
Le Xue、Manli Shu、Anas Awadalla、Jun Wang、An Yan、Senthil Purushwalkam、Honglu Zhou、Viraj Prabhu、Yutong Dai、Michael S Ryoo、Shrikant Kendre、Jieyu Zhang、Can Qin、Shu Zhang、Chia-Chih Chen、Ning Yu、Juntao Tan、Tulika Manoj Awalgaonkar、Shelby Heinecke、Huan Wang、Yejin Choi、Ludwig Schmidt、Zeyuan Chen、Silvio Savarese、Juan Carlos Niebles、Caiming Xiong、Ran Xu
Paper:
https://arxiv.org/abs/2408.08872
Introduction
Large Multimodal Models (LMMs) have garnered significant interest due to their potential applications and emergent capabilities. Despite recent advancements in both proprietary and open-source LMMs, there remains a gap in access to open weights, training recipes, and curated datasets. This gap hinders the open-source community from replicating, understanding, and improving LMMs. To address these challenges, the xGen-MM (BLIP-3) framework is introduced, which scales up LMM training by utilizing an ensemble of multimodal interleaved datasets, curated caption datasets, and other publicly available datasets. This framework aims to make LMM research and development more accessible to the community.

Related Work
Recent advancements in LMMs have explored two main architectural approaches: the cross-attention style and the decoder-only style. The cross-attention approach integrates vision and language modalities through a complex attention mechanism, while the decoder-only architecture connects pre-trained language models to visual inputs using lightweight connectors. The xGen-MM (BLIP-3) adopts the decoder-only architecture, which simplifies the integration process while maintaining robust multimodal capabilities. This approach has been effective in models such as MM1, VILA, LLaVA, phi3-vision, and Otter.
Model Architecture
Architecture Overview
The xGen-MM (BLIP-3) framework adopts an architecture consisting of a Vision Transformer (ViT), a vision token sampler (perceiver resampler), and a pre-trained Large Language Model (phi3-mini). The input to the model can be free-form multimodal interleaved texts and vision tokens from diverse multimodal data sources.
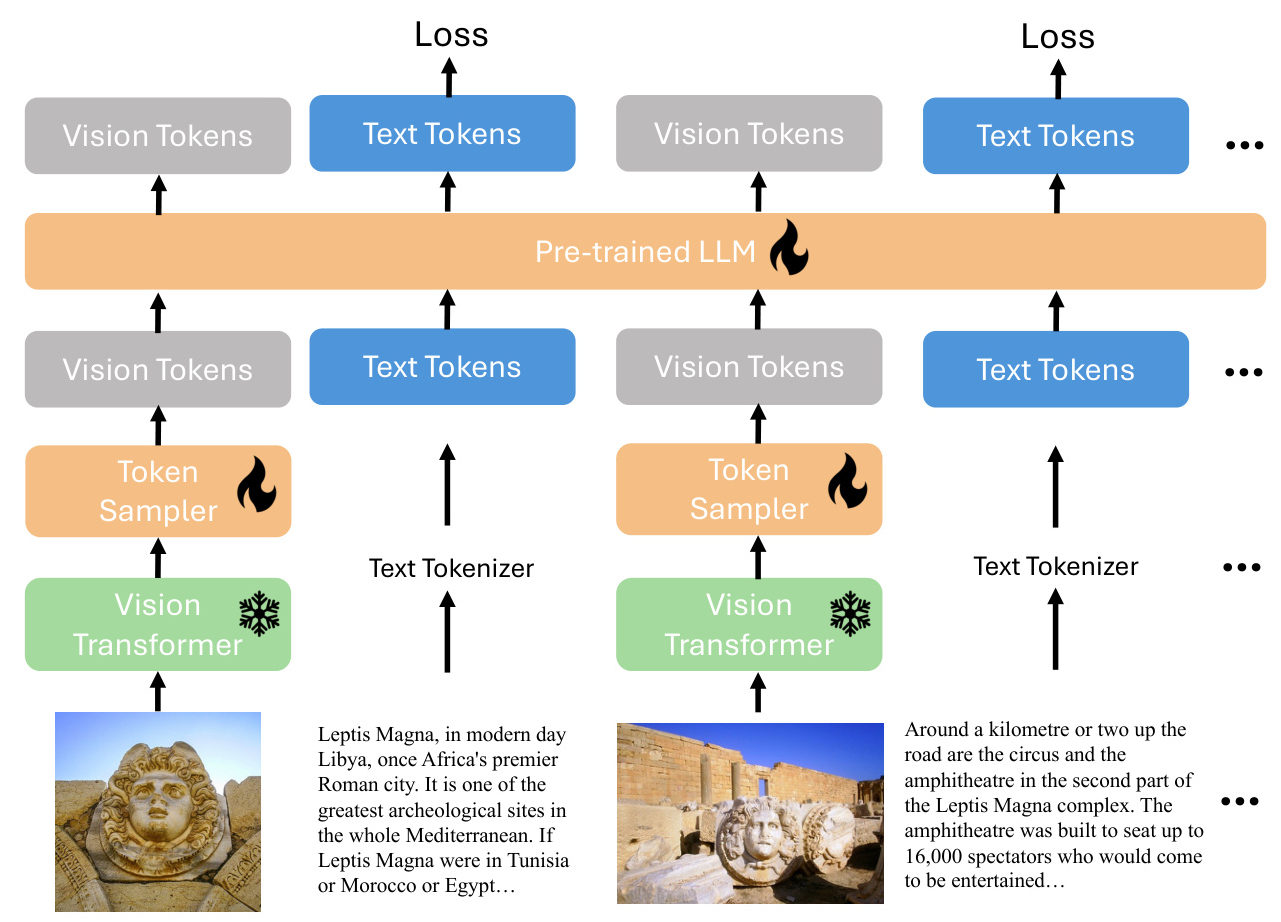
Any-Resolution Vision Token Sampling
The framework adopts a dynamic high-resolution image encoding strategy at the fine-tuning and post-training stages. This strategy preserves the resolution of the original image by splitting it into multiple patches and encoding them separately. The encoded image patches are concatenated with a downsized original image that provides global information. The perceiver resampler is used to downsample the vision tokens, reducing the sequence length of vision tokens by a factor of five or more.
Training
Pre-training
The pre-training objective is to predict the next text token across the dataset mixture. The base model xGen-MM-Phi3-mini-base-r is pre-trained for about 100 billion multimodal tokens from the ensembled dataset, with a pre-training resolution of 384×384 pixels.
Supervised Fine-tuning (SFT)
The pre-trained models are further fine-tuned on instruction-following examples to better understand and follow user queries. The fine-tuning stage uses a collection of publicly available instruction-following datasets. The any-resolution vision token sampling strategy is adopted to allow a better understanding of higher-resolution images.
Interleaved Multi-Image Supervised Fine-tuning
A second-stage fine-tuning is conducted on a mixture of multi-image and single-image instruction-following samples to enhance the model’s ability to comprehend interleaved image-text input. This stage also adopts the any-resolution vision token sampling strategy.
Post-training
Two stages of post-training are performed to improve the model’s helpfulness while mitigating harmful qualities such as hallucination and toxicity. Direct preference optimization (DPO) is performed to improve the model’s helpfulness and visual faithfulness, followed by safety fine-tuning to improve the model’s harmlessness.
Data
Pre-training Data Recipe
The pre-training data comprises an ensemble of diverse multimodal datasets with indicated sampling ratios.
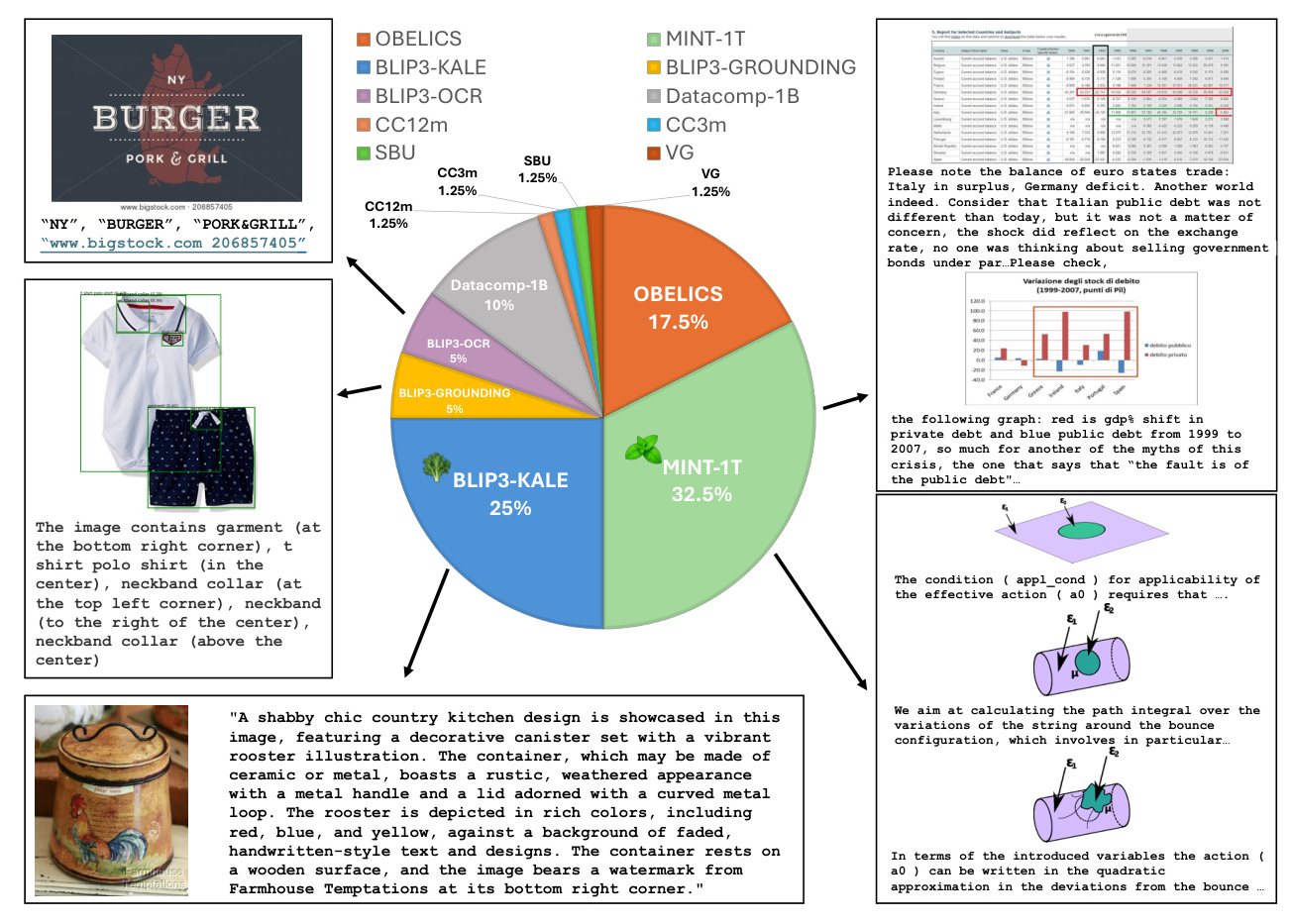
Interleaved Dataset Mixture
- MINT-1T: A trillion-token scale multimodal interleaved dataset containing data sources from HTML, PDF, and ArXiv.
- OBELICS: A large-scale multimodal interleaved dataset constructed from HTML documents.
Caption Dataset Mixture
- BLIP3-KALE: A large-scale curated high-quality caption dataset.
- BLIP3-OCR-200M: A curated large-scale OCR dataset to address limitations in handling text-rich images.
- BLIP3-GROUNDING-50M: A curated large-scale grounding dataset to enhance the ability to ground semantic concepts in visual features.
- Other Public Datasets Mixture: Includes datasets such as Datacomp-1B, CC12M, CC3M, VG, and SBU.
Supervised Fine-tuning Data Recipe
The fine-tuning stage uses public datasets from various domains, including multi-modal conversation, image captioning, visual question answering, chart/document understanding, science, and math. A mixture of 1 million publicly available instruction-tuning samples is collected for fine-tuning.
Post-training Data Recipe
Improving Truthfulness by Direct Preference Optimization
VLFeedback, a synthetically annotated multimodal preference dataset, is used to generate responses to a diverse mix of multimodal instructions. Preference data is constructed by marking preferred and dispreferred responses, and DPO is performed on the combined preference dataset.

Improving Harmlessness by Safety Fine-tuning
Safety fine-tuning is performed on the VLGuard dataset, which contains examples of unsafe images and instructions. The dataset consists of unsafe examples belonging to various subcategories, including privacy-violating, risky/sensitive topics, deception, and discrimination.
Experiments
Pre-training
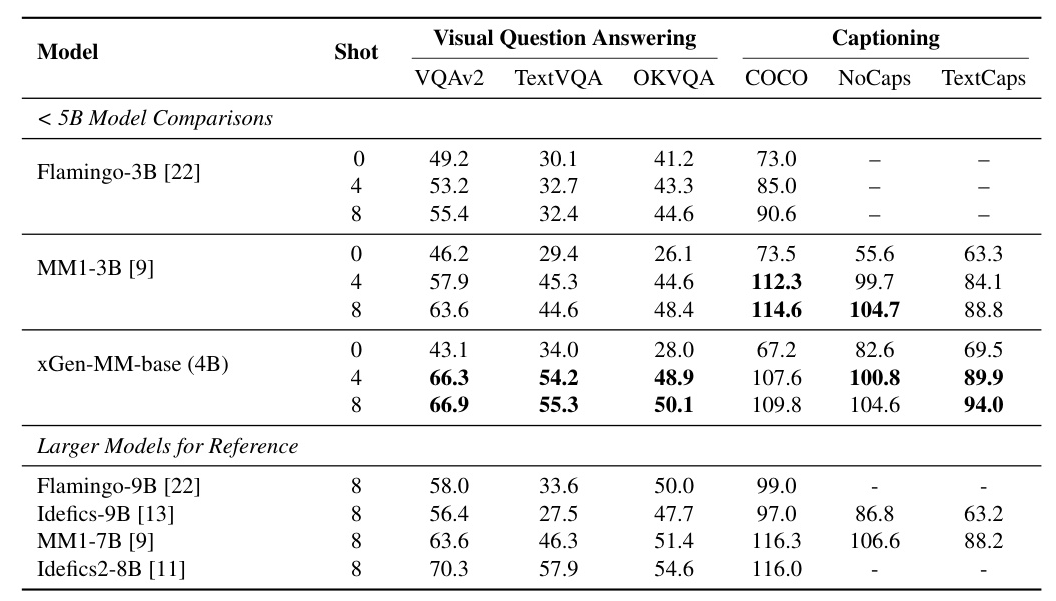
Few-shot evaluation is conducted on classic captioning and VQA tasks, comparing the pre-trained model with previous models that support few-shot learning multi-modal evaluation. The model achieves competitive multimodal in-context learning performance and significantly outperforms MM1-3B and larger models such as Idefics-9B and MM1-7B on OCR tasks and VQA-v2.

Supervised Fine-tuning
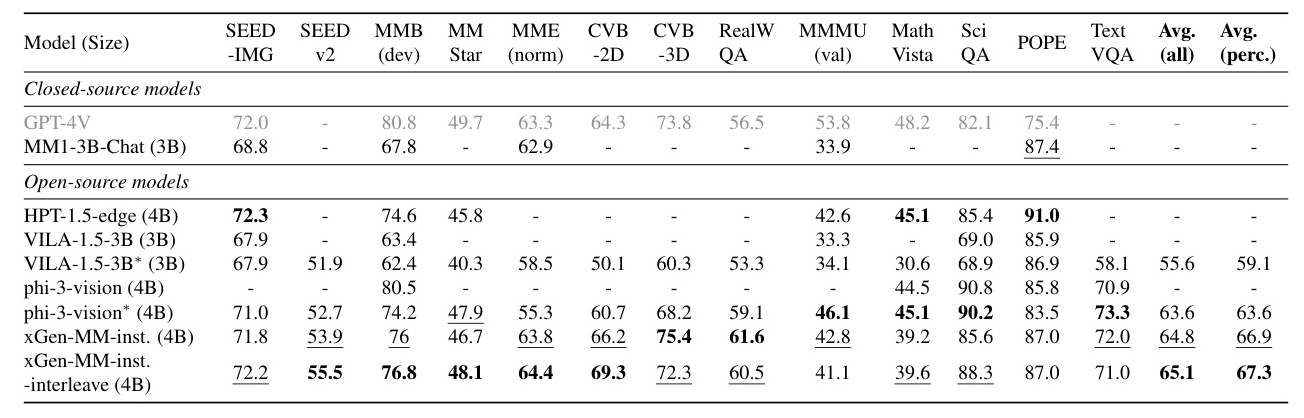
The model is evaluated on a comprehensive suite of multi-modal benchmarks, assessing its ability from multiple perspectives, including general VQA benchmarks, visual perception, domain knowledge, OCR ability, and hallucination. The model outperforms previous baselines on general VQA and visual perception benchmarks.

Post-training
Two post-training strategies are evaluated: DPO and safety fine-tuning. DPO enhances truthfulness by improving hallucination benchmarks, while safety fine-tuning significantly reduces the attack success rate (ASR) on the VLGuard test split. Helpfulness is also improved slightly.

Ablation Studies
Pre-training Ablation
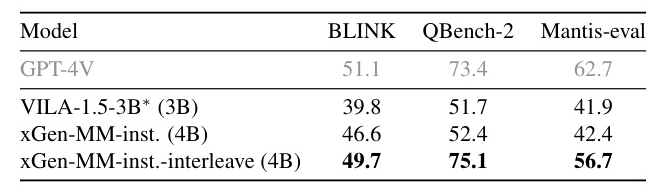
Scaling Pre-training Data
An ablation study explores the relation between the amount of pre-training data and the pre-train evaluation metrics. Scaling up the number of multimodal tokens from 2B to 60B leads to substantial gains for image-text and OCR tasks, with moderate additional benefits when increasing the data size to 100B.
Pre-training Data Recipe
Different data recipes for pre-training are explored. Using MINT-1T for image-text alignment and OCR tasks shows performance improvement, while adding text data helps attain performance on knowledge-intensive tasks.
Visual Backbones
Different visual backbones are compared, with SigLIP providing better visual representations that boost performance on OCR tasks.

Number of Visual Tokens
The impact of different numbers of visual tokens is studied, showing that reducing the number of visual tokens from 128 to 64 can still attain similar performance.

SFT Ablation
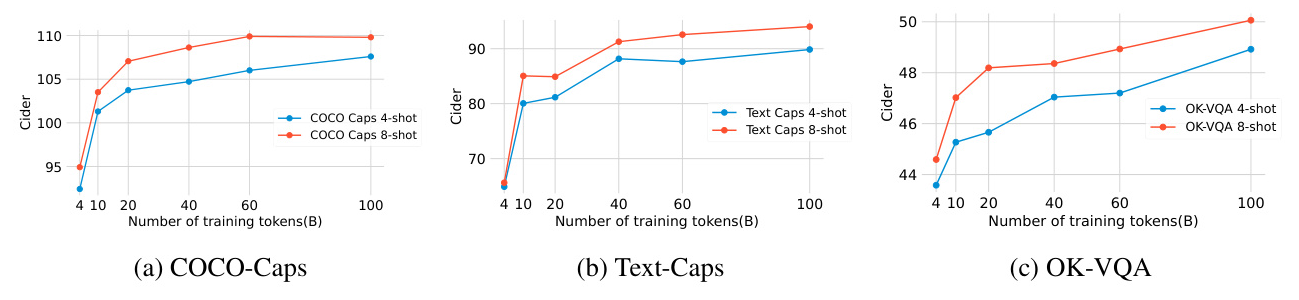
Any-Resolution Vision Token Sampling
The effectiveness of the any-resolution strategy is compared with a fixed-resolution baseline and other downsampling designs. The any-resolution strategy shows significant improvements on text-rich tasks.
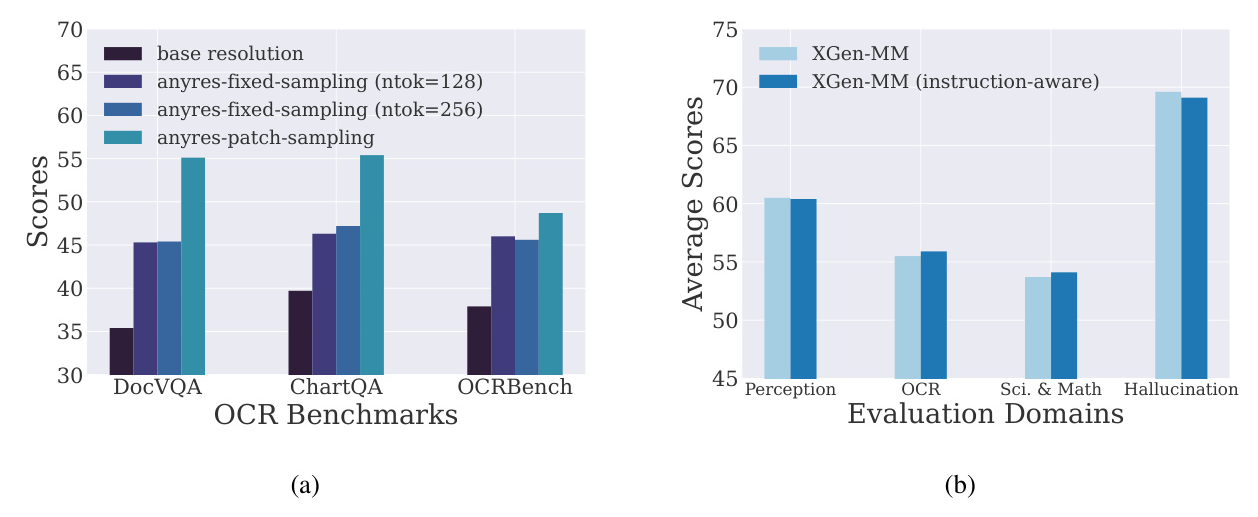
Instruction-Aware Vision Token Sampling
An instruction-aware modification to the perceiver resampler is explored, but no significant difference is observed compared to the original perceiver resampler architecture.
Quality of the Text-only Instruction Data
The impact of the diversity of pure text instruction data on multi-modal performance is studied. Adding math and coding data improves performance on relevant benchmarks while having less effect on general VQA benchmarks.
Conclusion
The xGen-MM (BLIP-3) framework provides a comprehensive approach for training a series of open-source large multimodal models on a curated mixture of large-scale datasets. The framework demonstrates emergent abilities such as multimodal in-context learning and achieves impressive results on multimodal benchmarks. By open-sourcing the models, datasets, and fine-tuning codebase, the framework aims to empower the research community with accessible multimodal foundation models and datasets, allowing practitioners to explore further and advance the potential and emergent abilities of LMMs.
Broader Impact
The xGen-MM (BLIP-3) framework and its suite of LMMs have the potential to significantly advance multimodal AI research by providing accessible, open-source resources for the broader community. The integration of safety-tuning protocols helps mitigate ethical risks such as bias and misinformation, promoting the responsible deployment of AI technologies.
Acknowledgement
The authors thank Srinath Meadusani, Lavanya Karanam, Dhaval Dilip Metrani, and Eric Hu for their work on the scientific computation infrastructure, as well as Jason Lee and John Emmons for their efforts in collecting the large-scale text-only SFT datasets used in one of the pre-training ablation studies.