Authors:
Xucheng Wan、Naijun Zheng、Kai Liu、Huan Zhou
Paper:
https://arxiv.org/abs/2408.10524
XCB: An Effective Contextual Biasing Approach to Bias Cross-Lingual Phrases in Speech Recognition
Introduction
In recent years, End-to-End (E2E) Automatic Speech Recognition (ASR) models have made significant strides in improving speech recognition accuracy. Models such as Transformer, Transducer, and Conformer have set new benchmarks in various speech recognition tasks. However, these models often struggle with recognizing rare words, such as jargon or unique named entities, especially in real-world applications. One popular solution to this problem is contextualized ASR, which integrates contextual information from a predefined list of rare words to enhance recognition accuracy.
Despite these advancements, contextualized ASR models face challenges in bilingual settings, particularly in code-switching scenarios where phrases from multiple languages are used interchangeably. This study introduces a novel approach called Cross-lingual Contextual Biasing (XCB) to address this issue. The XCB module is designed to improve the recognition of phrases in a secondary language by augmenting a pre-trained ASR model with an auxiliary language biasing module and a supplementary language-specific loss.
Related Work
Contextualized ASR
Contextualized ASR models have been developed to improve the recognition of uncommon phrases by integrating contextual information from a predefined hotword list. Paraformer, a non-autoregressive (NAR) model, has gained attention for its high accuracy and efficient inference. SeACo-Paraformer extends Paraformer by adding a semantic-augmentation contextual module to enhance hotword customization capabilities.
Code-Switching ASR
In the domain of code-switching ASR, various methods have been proposed to learn language-specific representations and discriminate between different languages. These include employing language expert modules, language-aware encoders, and separate language-specific representations with adapters. However, these methods typically require large-scale training data, which is often impractical.
Research Methodology
XCB Module
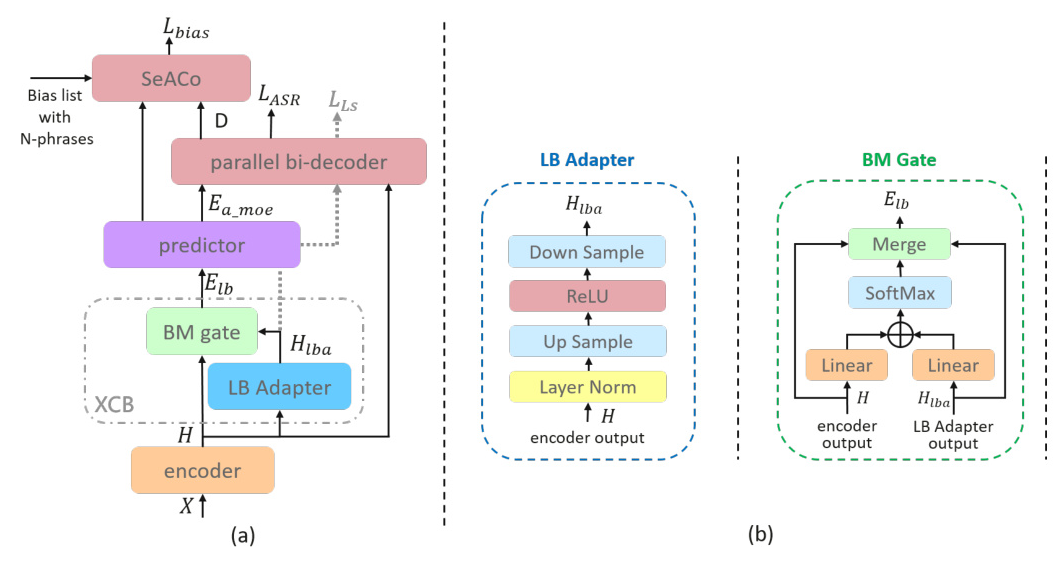
The XCB module is integrated into the SeACo-Paraformer backbone to enhance the recognition of cross-lingual phrases. The module consists of two core components: the Language Biasing Adapter (LB Adapter) and the Biasing Merging Gate (BM Gate).
LB Adapter
The LB Adapter transforms hidden representations of acoustic features into language-biased hidden representations. It distinguishes frames associated with the secondary language (L2nd) and enhances the corresponding representations in the feature space.
BM Gate
The BM Gate generates language-biased acoustic embeddings by merging the hidden representation and the language-biased representation. This process involves linear projection, scaling by language-specific weights, and merging the results with residual connections.
Language-Specific Loss
To encourage the learning of language-biased acoustic embeddings, an additional loss component (L2nd) is introduced. This loss is calculated using a ground truth label set that retains only the L2nd context. The total loss function is a linear combination of the original ASR training loss and the language-specific loss.
Experimental Design
Data Preparation
The proposed ASR model with the XCB module is trained and evaluated on an internal code-switching dataset (Mandarin-English) containing 14k utterances with a duration of 20 hours. The dataset is split into training and testing sets. Additionally, the model is evaluated on the ASRU 2019 Mandarin-English code-switching challenge dataset.
Experimental Setup
The SeACo-Paraformer model, pre-trained on 50k hours of Mandarin speech data, serves as the baseline. The XCB-enhanced ASR model is trained for 10 epochs with a learning rate of 0.0002 and a batch size of 30. The weight for the language-specific loss is set to 0.3.
Evaluation Metrics
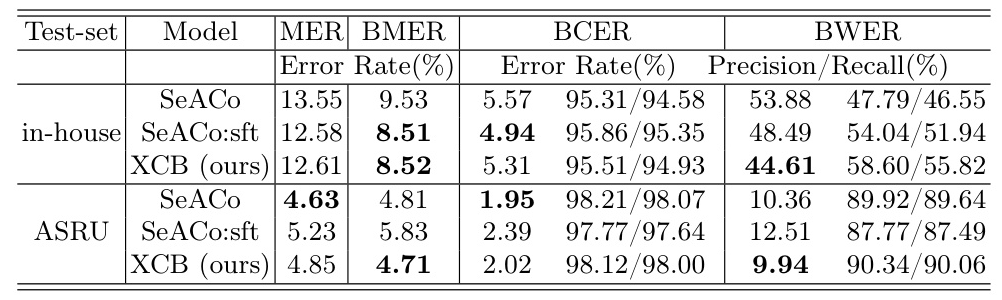
The performance of the models is evaluated using the mixed error rate (MER), biasd character error rate (BCER) for Mandarin, biasd word error rate (BWER) for English, and biasd mixed error rate (BMER).
Results and Analysis
Experimental Results
The experimental results demonstrate that the XCB-enhanced ASR model significantly outperforms the baseline models in terms of BWER. The XCB model shows a 17.2% relative reduction in BWER compared to the vanilla backbone and an 8% reduction compared to the fine-tuned backbone. The results also indicate that the XCB model maintains consistent performance on the dominant language (L1st) and improves the precision and recall of biased English phrases.
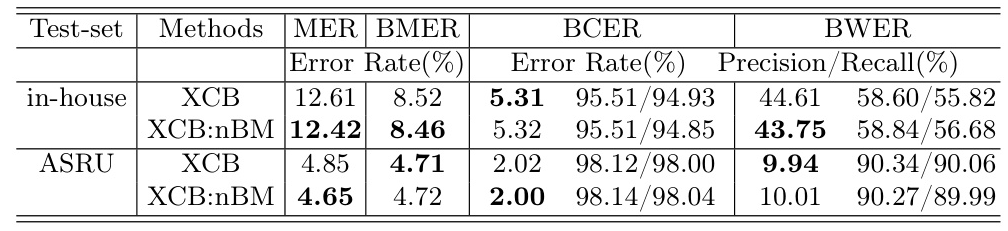
Active vs. Inactive XCB
An additional experiment was conducted to compare the performance of the XCB model with the auxiliary module inactive during inference. Interestingly, the inactive XCB model (XCB:nBM) showed even better performance than the active XCB model, suggesting that the XCB training might encourage discrimination of L2nd in the lower features produced by the encoder.
Overall Conclusion
The study introduces a novel Cross-lingual Contextual Biasing (XCB) module to enhance the performance of contextualized ASR models in recognizing phrases in a secondary language within code-switching utterances. The proposed approach offers significant improvements in recognizing bias phrases of the secondary language, maintains consistent performance on the dominant language, and provides generalizability across different datasets. Future work will focus on investigating the reasons behind the better performance of the inactive biasing module and expanding the method to other end-to-end ASR backbones.