

Authors:
Zeyu Gao、Hao Wang、Yuanda Wang、Chao Zhang
Paper:
https://arxiv.org/abs/2408.06385
Introduction
Assembly code search is a crucial task for reverse engineers, enabling them to quickly locate specific functions within extensive binary files using natural language queries. Traditional methods, such as searching for unique strings or constants, are often inefficient and time-consuming. This paper introduces a novel approach using a Large Language Model (LLM) to emulate a general compiler, termed as Virtual Compiler (ViC), to facilitate assembly code search.
Background and Related Works
Assembly Code Analysis
Compilation transforms high-level source code into assembly code, which is directly executable by a CPU. This process often results in the loss of original context and structure, making binary code analysis challenging. Reverse engineering is a common methodology used to analyze binary files without the source code, aiming to reconstruct functionality and logic.
Assembly Code Modeling
Modeling assembly code presents unique challenges due to the absence of high-level logical structures. Techniques such as Binary Code Similarity Detection (BCSD) are used to assess the similarity between different assembly codes. Various models, including GNN, DPCNN, LSTM, and Transformer-based models, have been developed to capture the semantics of assembly code.
Code Search
Code search enables developers to query and retrieve valuable code snippets using natural language queries. This process typically involves pre-training models on extensive corpora of unpaired code and natural language, followed by fine-tuning on specialized code search datasets.
Overview
The workflow for enhancing assembly code search capabilities using ViC involves three phases:
- Code Dataset Construction: Compiling a vast collection of packages from Ubuntu to obtain a mapping between source and assembly code.
- Virtual Compiler Training: Training the CodeLlama model on this dataset to emulate compiler behavior.
- Assembly Code Encoder Training: Using the trained model to perform virtual compilations on existing code search datasets, producing an augmented assembly code search dataset.
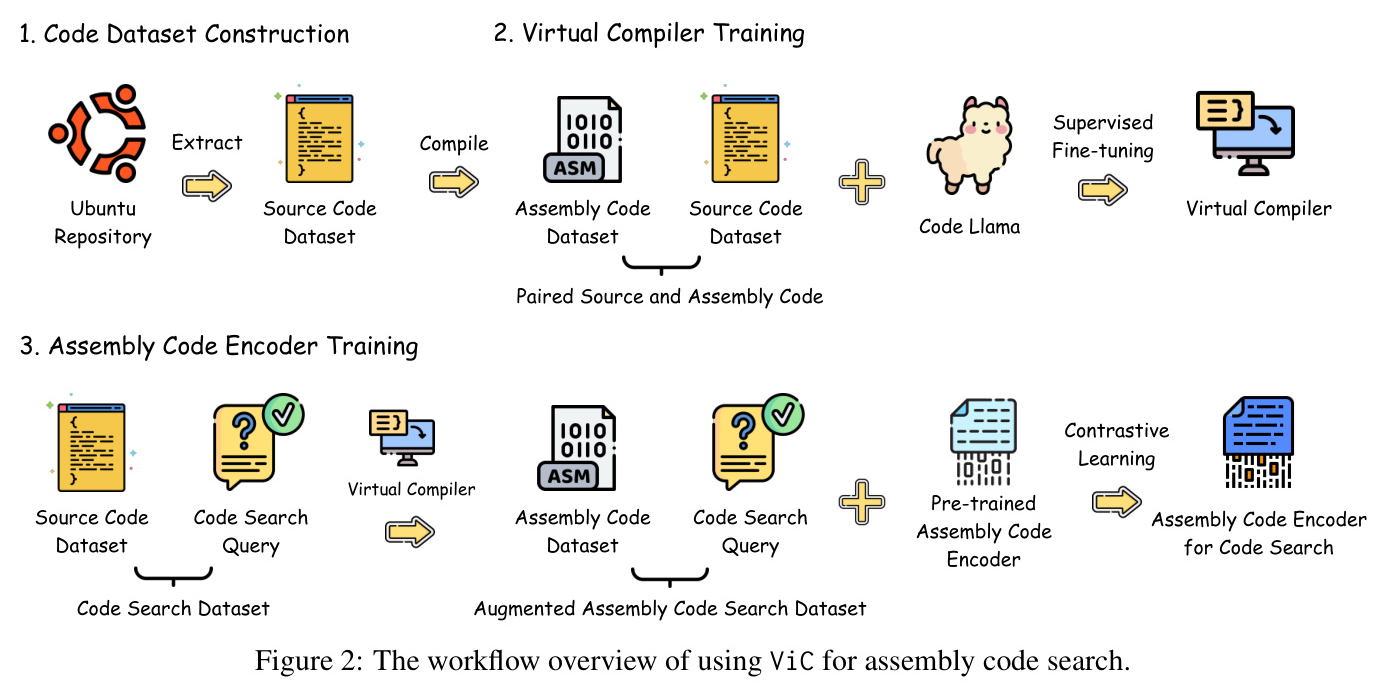
Virtual Compiler
Code Dataset Construction
To train a model to compile source code to assembly code, over 6,000 C/C++ packages from Ubuntu were compiled using different versions of GCC and Clang compilers at various optimization levels. This process yielded a dataset of 15 million source-to-assembly pairs, exceeding 20 billion tokens.
Model Training
The model, based on Codellama 34B, was trained using Supervised Fine-Tuning (SFT). The training involved a context length of 4,096 tokens and was conducted on 64 NVIDIA A100 GPUs, exceeding a total of 1,000 GPU days.
Code Search Contrastive Learning
Dataset
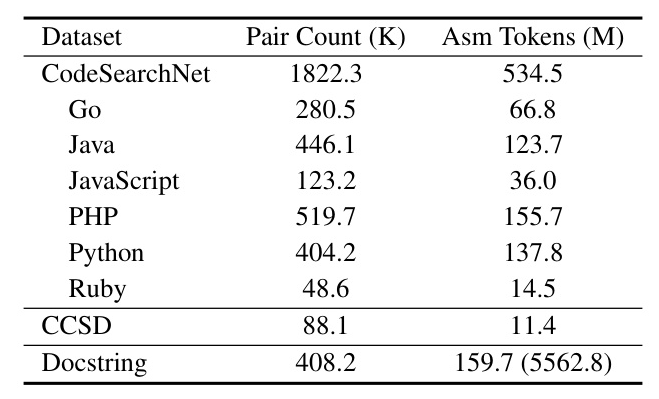
Two datasets were used for code search contrastive learning: CCSD and CodeSearchNet. The virtual compilation approach was applied to these datasets to generate virtual assembly codes, expanding their applicability to assembly code search.
Model Architecture
The text encoder and assembly code encoder were decoupled, with the assembly code encoder using a roformer-base model. The text encoder was initialized using sentence-transformers.
Assembly Code Encoder Training
The assembly code encoder was trained using in-batch negative sampling and InfoNCE loss. The training involved a learning rate of 1e-6 for the text encoder and 2e-5 for the assembly code encoder.
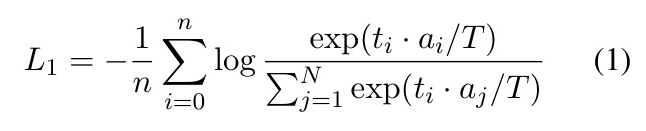
Evaluation
Evaluation Setup
ViC was implemented using Pytorch 2.1 and evaluated using IDA Pro 8.3 for disassembling and extracting functions from binary executable files. The evaluation involved multiple servers with 128 cores and 2TB RAM each, and 32 NVIDIA Tesla A100 GPUs.
Evaluation of Virtual Compiler
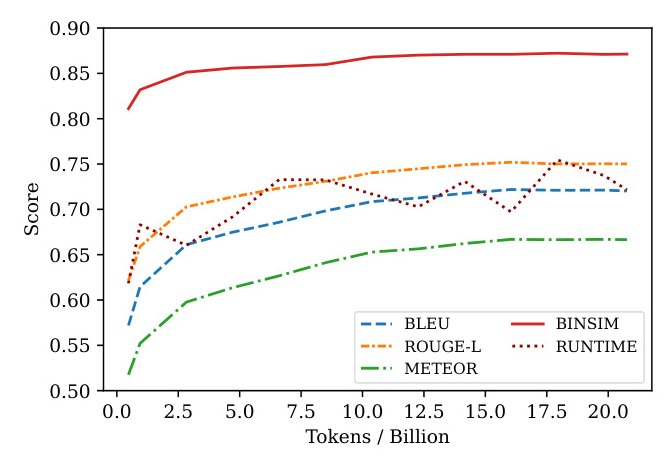
The quality of the assembly code generated by the virtual compiler was assessed using various similarity metrics, runtime characteristics, and semantic similarity.
Sequence Similarity
Metrics such as BLEU, ROUGE-L, and METEOR were used to evaluate the similarity between generated assembly code and the reference ground truth.
Runtime Similarity
The runtime characteristics of the generated assembly code were studied using Keystone and Unicorn, comparing memory reads and writes, function return values, and stack registers.
Semantic Similarity
Binary Code Similarity Detection (BCSD) was used to evaluate the semantic similarity of the generated assembly code.

Case Study
A case study highlighted the differences between model-generated and compiler-generated assembly code, revealing various categories of mismatches.
Evaluation of Assembly Code Search
The enhancement of code search capabilities was validated using a real-world evaluation dataset and compared against general embedding models.
Training Dataset
The training dataset included docstrings extracted from Ubuntu source code and virtual assembly code from CodeSearchNet and CCSD.

Evaluation Dataset
The evaluation dataset was constructed from popular binaries across different platforms, with manually crafted queries reflecting real-world reverse engineering tasks.
Baselines
General embedding models such as sentence-transformers, GTE, and Voyage AI models were used as baselines for comparison.
Metric
Recall and Mean Average Precision (MAP) were used to measure the performance of the models.
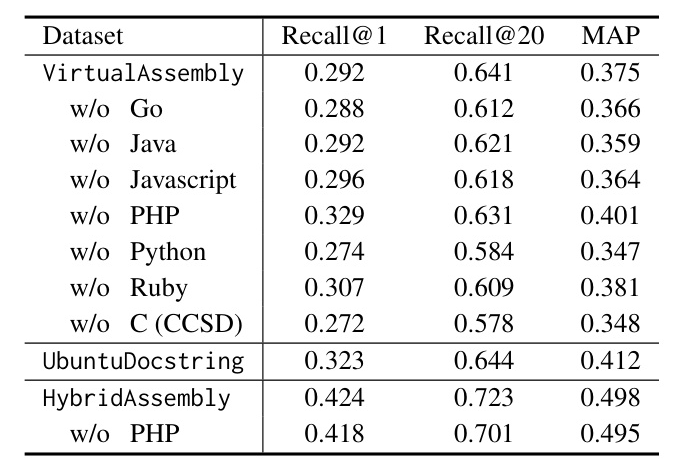
Main Result
The model trained on the HybridAssembly dataset outperformed the baseline models, demonstrating the effectiveness of the virtual compiler approach.
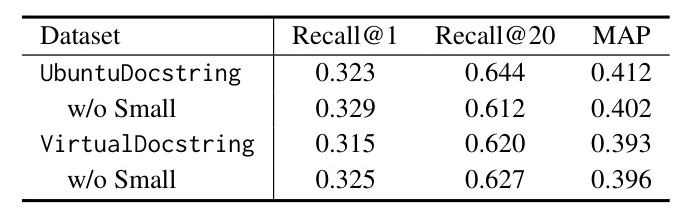
Virtual vs. Real Assembly Code
The performance of virtual assembly code was compared against real assembly code, showing similar outcomes when small functions were excluded.
Dataset Contributions
The contributions of different datasets to assembly code search performance were evaluated, highlighting the importance of incorporating low-level concepts in training sets.
Limitation & Discussion
Code Search Dataset Quality
The quality of the assembly code search dataset is tied to the underlying code search datasets, which are often derived from docstrings. The potential lack of strong relevance in docstrings poses a challenge.
Broader Impacts
Assembly code search as a Retrieval-Augmented Generation (RAG) module can aid reverse engineering but also poses risks of exploitation by malicious actors.
Future Work
Future work will focus on expanding the evaluation dataset and improving model initialization for better assembly code search performance.
Conclusion
This study introduces a pioneering method to improve assembly code search by training an LLM to function as a virtual compiler, ViC. This approach addresses the challenge of compiling difficulties and enhances dataset quality for assembly code search, significantly boosting performance and offering a promising direction for future advancements in software engineering and security analysis.
Acknowledgements
The authors thank the reviewers for their valuable feedback and extend special thanks to Bolun Zhang and Jingwei Yi for their invaluable comments and assistance.