

Authors:
Junwei You、Haotian Shi、Zhuoyu Jiang、Zilin Huang、Rui Gan、Keshu Wu、Xi Cheng、Xiaopeng Li、Bin Ran
Paper:
https://arxiv.org/abs/2408.09251
Introduction
Background
The field of autonomous driving has seen significant advancements, particularly with the development of end-to-end (E2E) systems. These systems manage the entire driving process, from environmental perception to vehicle control, using integrated machine learning models to process complex environmental data in real-time. The integration of large-scale machine learning models, such as large language models (LLMs) and vision-language models (VLMs), has further enhanced the capabilities of these systems.
Problem Statement
Despite the progress, there remains a notable gap in the application of foundation models like VLMs in E2E cooperative autonomous driving. Traditional AI models struggle with integrating complex and multimodal data from various sources. This study introduces V2X-VLM, an innovative E2E vehicle-infrastructure cooperative autonomous driving (VICAD) framework leveraging large VLMs to enhance situational awareness, decision-making, and overall driving performance.
Related Work
LLM Enhanced E2E Autonomous Driving
Recent research has highlighted the transformative potential of LLMs in E2E autonomous driving. For instance, DriveGPT4 integrates multi-frame video inputs and textual queries to predict vehicle actions, enhancing transparency and user trust. Similarly, LMDrive utilizes multimodal sensor data and natural language instructions to generate control signals, facilitating real-time interaction with complex environments.
VLM Advancement in E2E Autonomous Driving
The development of VLMs has expanded the capabilities of autonomous systems by integrating visual and linguistic processing. DriveVLM, for example, combines scene description, analysis, and hierarchical planning modules to tackle challenges in urban driving scenarios. VLP leverages VLMs to integrate common-sense reasoning into autonomous driving systems, enhancing the system’s ability to generalize across diverse urban environments.
V2X Enabled Cooperative Autonomous Driving
V2X communication systems enable vehicles to communicate with each other and with infrastructure elements, providing real-time updates and a broader context of the driving environment. Studies have demonstrated the potential of V2X systems to improve situational awareness, maneuvering capabilities, and overall traffic safety and efficiency.
Research Methodology
Problem Formulation
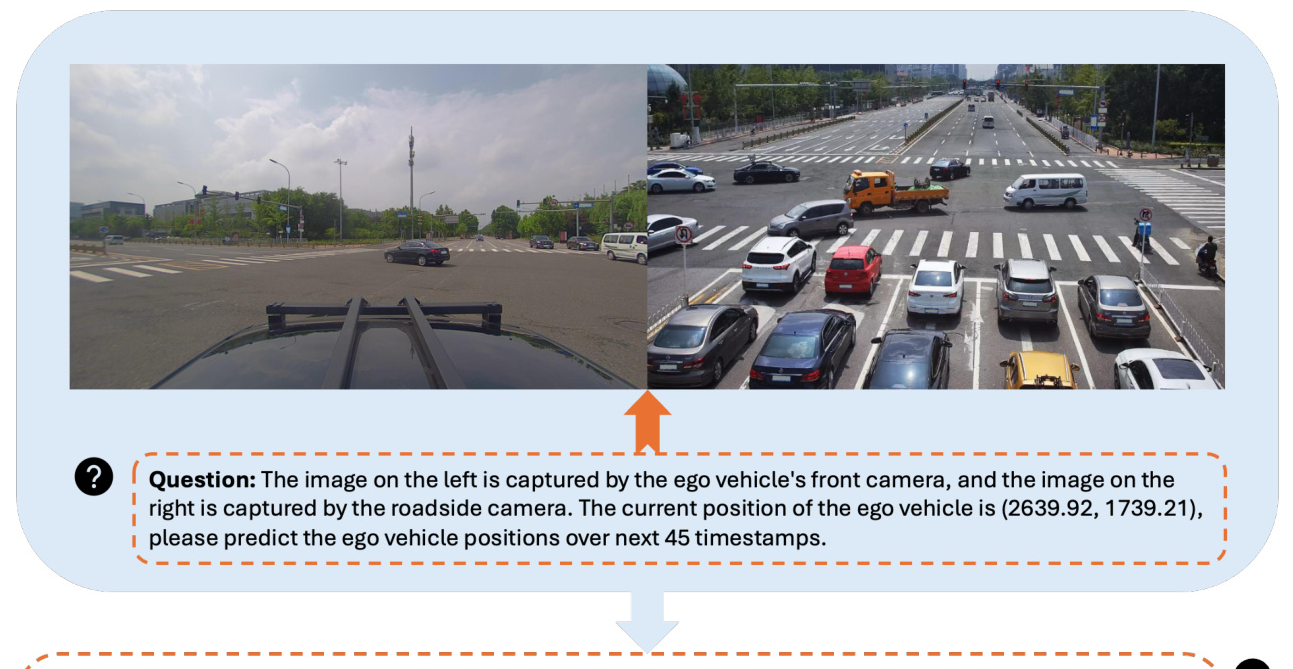
The goal of the proposed E2E framework V2X-VLM is to plan the optimal trajectory for the ego vehicle by integrating and processing multimodal data from various sources. The data includes images from vehicle-mounted cameras, infrastructure cameras, and textual information indicating the current vehicle position.
Overall V2X-VLM Framework Architecture
The V2X-VLM framework integrates data from vehicle-mounted cameras, infrastructure sensors, and textual information to form a comprehensive E2E system for cooperative autonomous driving. The large VLM synthesizes and analyzes diverse input types to provide a holistic understanding of the driving environment.
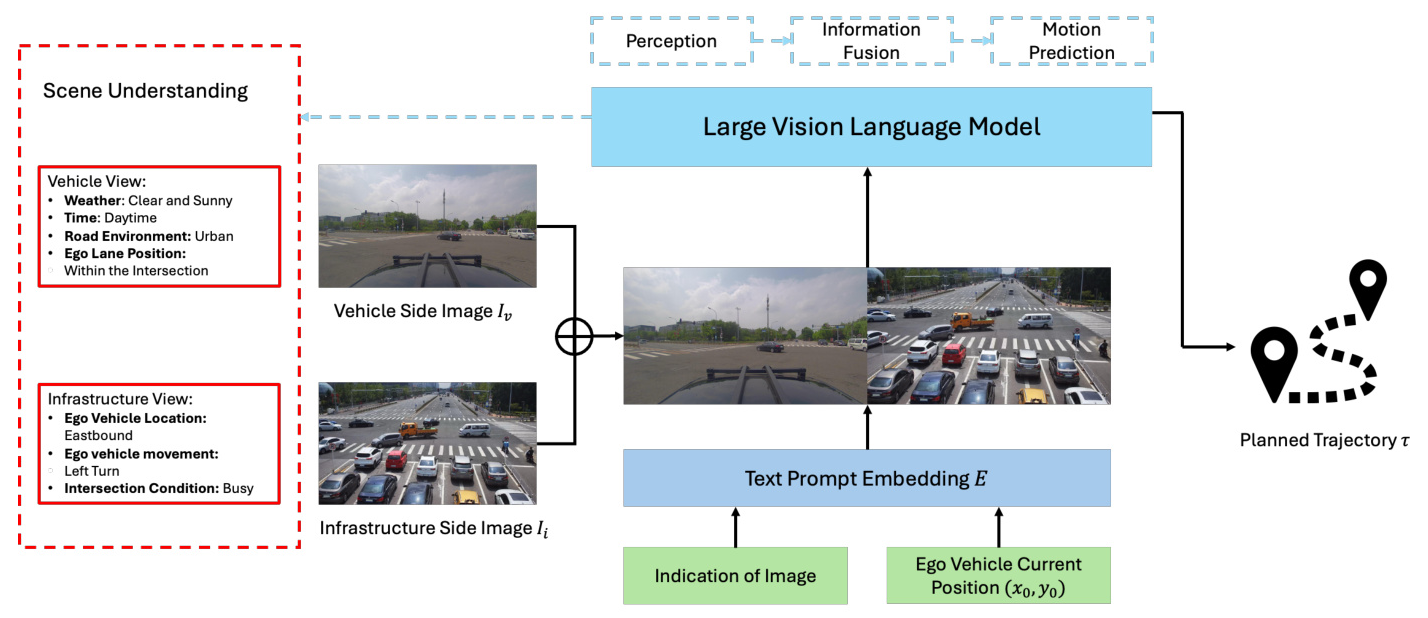
Scene Understanding and Interpretation
VLM plays a crucial role in understanding and interpreting perception images captured from both the vehicle and infrastructure sides. It identifies essential elements such as types of nearby vehicles, road signs, traffic signals, weather conditions, and broader traffic patterns, providing a comprehensive understanding of the environment.




E2E VICAD Multimodel Input Paradigm for VLMs
The proposed paradigm for handling multimodal data emphasizes simplicity and effectiveness. Data from vehicle-mounted and infrastructure cameras are combined into pairs, with each pair embedded with a text prompt indicating the ego vehicle’s current position. This approach reduces computational overhead and redundancy, making real-time processing more feasible.

Experimental Design
Dataset
The DAIR-V2X dataset is used for evaluation. It includes extensive data from vehicle-mounted and infrastructure sensors, capturing RGB images and LiDAR data across diverse traffic scenarios. The dataset features detailed annotations, facilitating the development of advanced V2X systems.
Setups
V2X-VLM utilizes a pre-trained VLM known as Florence-2. The vision tower of the model is pre-trained and frozen during fine-tuning to leverage robust visual feature representations. The experiments are conducted on a single NVIDIA RTX 4090 GPU.

Baselines
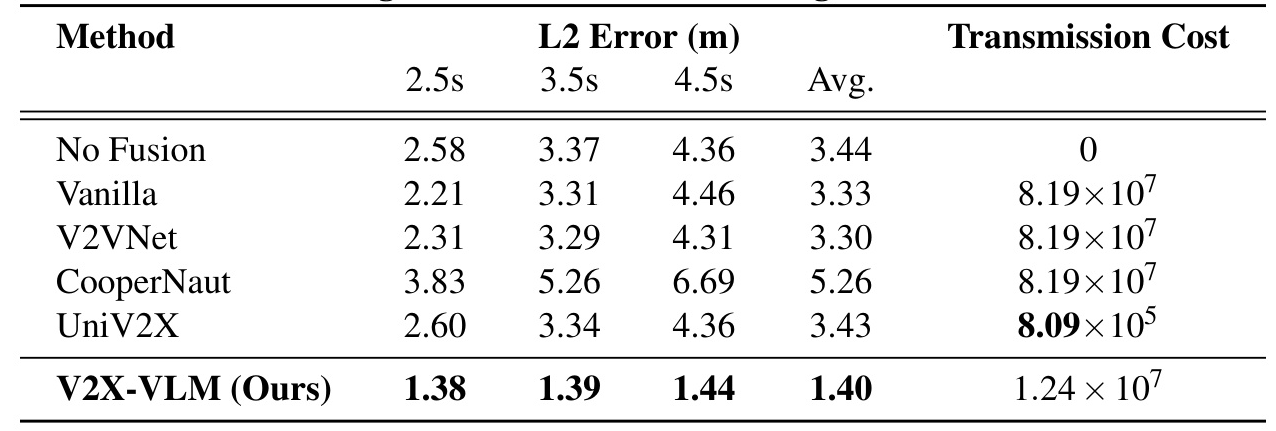
The performance of V2X-VLM is evaluated against several baseline methods, including No Fusion, Vanilla, V2VNet, CooperNaut, and UniV2X. Metrics such as L2 Error and Transmission Cost are used to assess the effectiveness, safety, and communication efficiency of the proposed framework.
Results and Analysis
Results Evaluation
The V2X-VLM framework demonstrates superior performance with the lowest average L2 Error of 1.40 meters, significantly outperforming all baseline methods. The transmission cost, while higher than some methods, is justified by the significantly improved accuracy and safety outcomes.
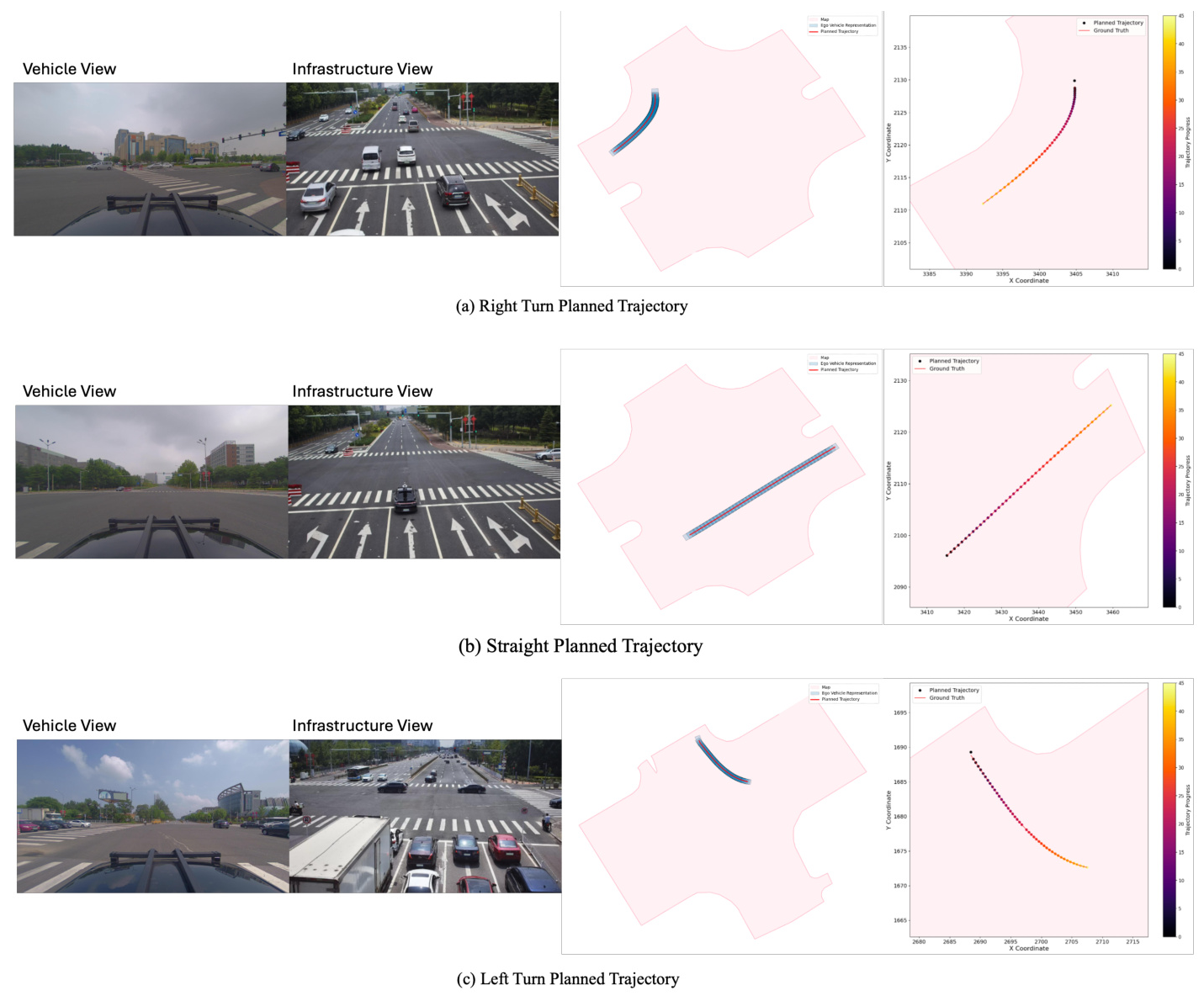
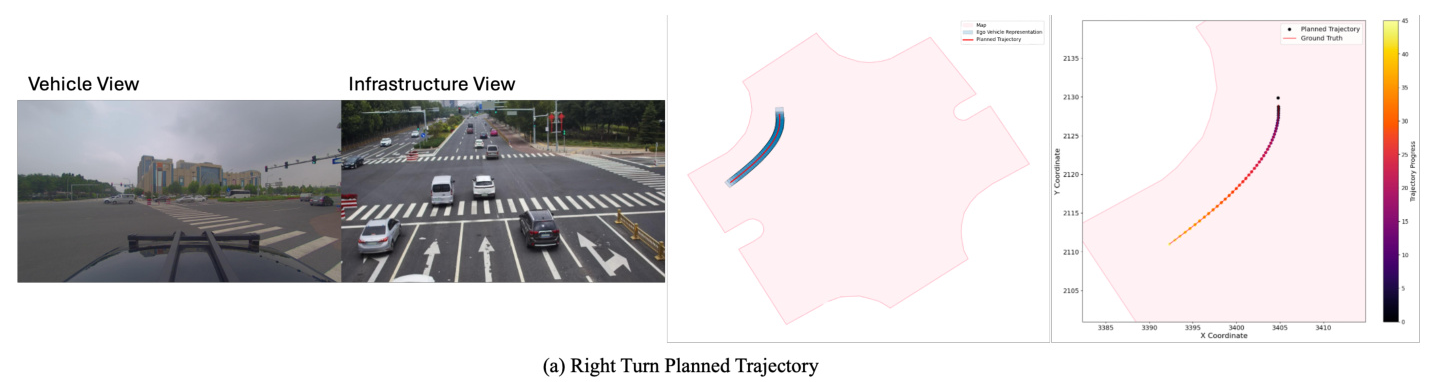
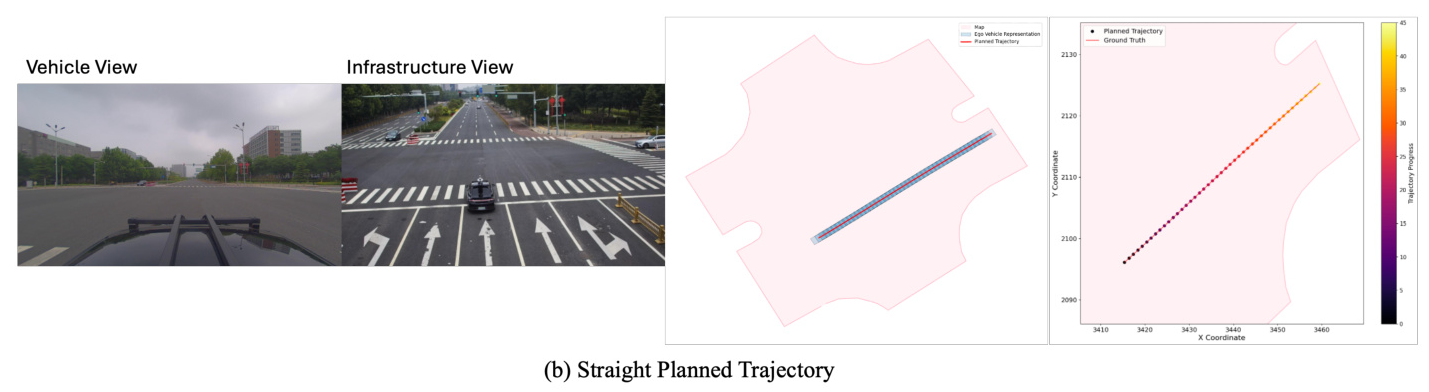
Results Visualization
Figure 4 visualizes the planned trajectories from the V2X-VLM framework, demonstrating its ability to produce high-quality trajectory outputs across various driving scenarios.

Overall Conclusion
This study presents V2X-VLM, an innovative framework that advances the field of VICAD by leveraging the capabilities of large VLMs. V2X-VLM excels in integrating and processing multimodal data, resulting in precise and efficient trajectory planning. Future research will focus on diversifying the model’s output, optimizing data transmission efficiency, and training on more diverse datasets to improve the system’s adaptability and robustness.
Author Contributions
Junwei You, Haotian Shi, Zhuoyu Jiang, Zilin Huang, Rui Gan, Keshu Wu, Xi Cheng, Xiaopeng Li, and Bin Ran collectively developed the research concept and methodology. Junwei You, Haotian Shi, Zhuoyu Jiang, Zilin Huang, Rui Gan, Keshu Wu, and Xi Cheng contributed to the implementation and experiments. Xiaopeng Li and Bin Ran provided overall guidance and supervision. All authors reviewed and approved the final manuscript.