

Authors:
Jiri Hron、Laura Culp、Gamaleldin Elsayed、Rosanne Liu、Ben Adlam、Maxwell Bileschi、Bernd Bohnet、JD Co-Reyes、Noah Fiedel、C. Daniel Freeman、Izzeddin Gur、Kathleen Kenealy、Jaehoon Lee、Peter J. Liu、Gaurav Mishra、Igor Mordatch、Azade Nova、Roman Novak、Aaron Parisi、Jeffrey Pennington、Alex Rizkowsky、Isabelle Simpson、Hanie Sedghi、Jascha Sohl-dickstein、Kevin Swersky、Sharad Vikram、Tris Warkentin、Lechao Xiao、Kelvin Xu、Jasper Snoek、Simon Kornblith
Paper:
https://arxiv.org/abs/2408.07852
Introduction
Despite significant advancements in the capabilities of large language models (LMs), hallucinations—instances where models generate incorrect or nonsensical information—remain a persistent challenge. This paper investigates how the scale of LMs influences hallucinations, focusing on cases where the correct answer appears verbatim in the training set. By training LMs on a knowledge graph (KG)-based dataset, the study aims to understand the extent of hallucinations and their detectability.
Controlling What an LM Knows
The Knowledge Graph Dataset
A core challenge in studying LM hallucinations is the uncertainty about the information the model was exposed to during training. To address this, the authors use a KG, which provides structured, factual data in the form of [subject, predicate, object] triplets. This setup allows precise control over the training data, enabling a clear assessment of whether a generated fact exists in the dataset.
The KG used in this study contains semantic triples, which are formatted into strings with special tokens indicating their identity. This structured data removes the ambiguity of natural language, making it easier for LMs to learn facts but harder due to the lack of correlation between data samples.
Training LMs on the Knowledge Graph
The authors trained decoder-only transformer LMs with varying numbers of parameters (3.15M–1.61B) on different sizes of the KG dataset (1%–100%). The training involved optimizing the autoregressive cross-entropy loss over formatted strings created from triplets. The study varied the total number of training steps to examine the effect of multi-epoch training.
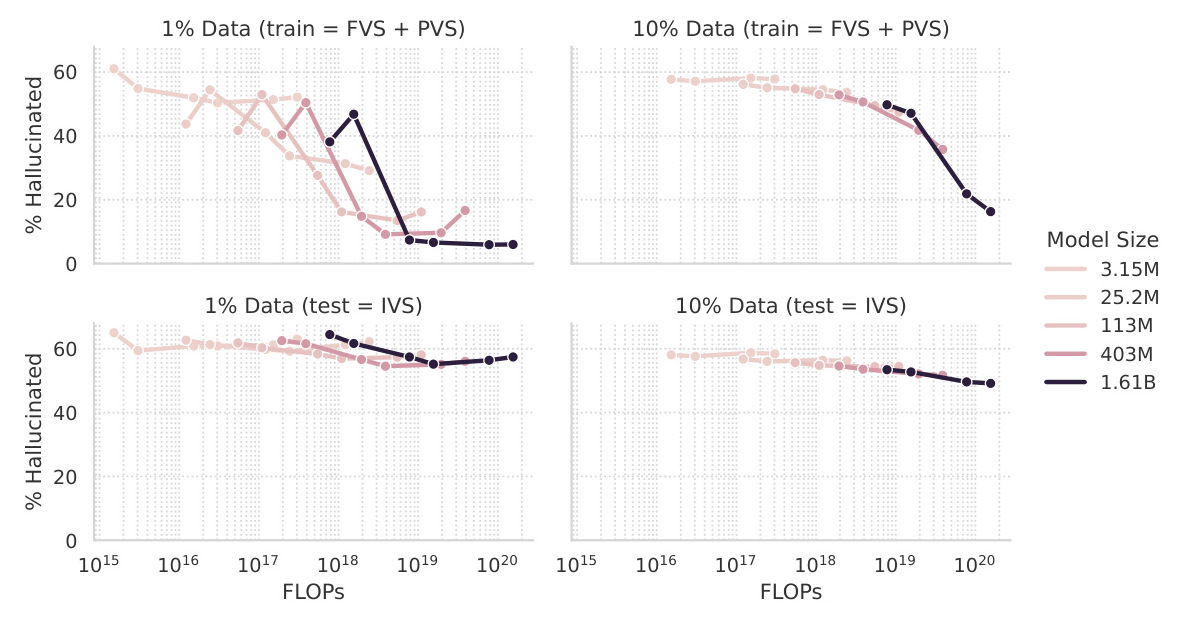
Hallucination Rate and How It Scales
Scaling laws suggest that the cross-entropy loss of LMs decays as a power law of the model and training set size. However, the study finds that hallucination rates do not follow this trend. Larger, longer-trained models tend to hallucinate less for a fixed dataset size, but increasing the dataset size yields a higher hallucination rate. This is because many triplets in the KG require memorization, and each triplet appears only once in the training set.
The study also finds that 20+ epochs are necessary to achieve a minimal hallucination rate for a given LM size, contrasting with the current practice of training LMs for only one or a few epochs. However, training for more epochs can decrease the model’s ability to generalize to unseen data, presenting a trade-off between hallucination rates and other performance measures.
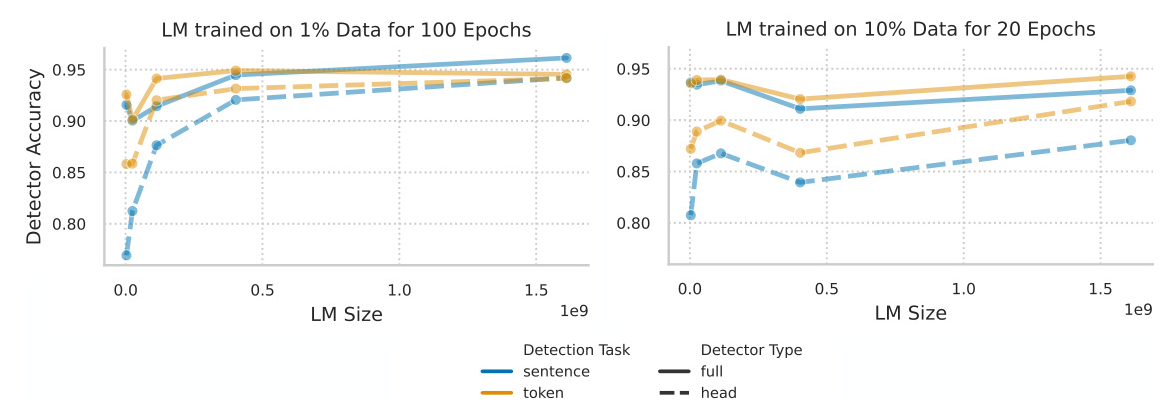
Hallucination Detectability and How It Scales
Setup
The study explores how the effectiveness of hallucination detectors depends on the scale and training length of the LM they are judging. Two types of detection tasks are considered: sentence-level and token-level. For each task, two types of hallucination detectors are used: head detectors, which add a new readout head on top of the pretrained LM, and full detectors, which finetune all the LM’s weights.
Results
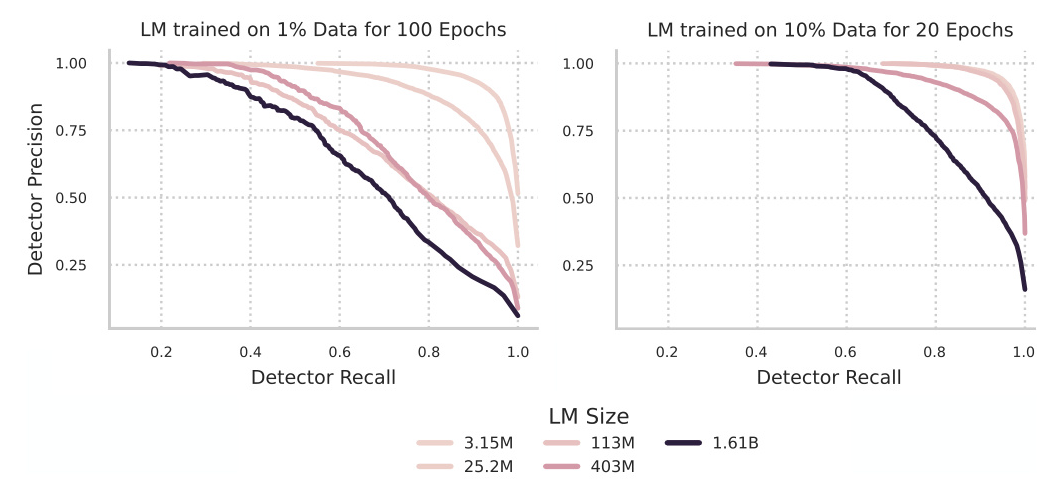
The results show that full detectors outperform head detectors, and token-level detection generally yields better accuracy than sentence-level detection. However, the detectability of hallucinations is inversely proportional to the LM size. Larger LMs have lower hallucination rates, but their hallucinations are harder to detect.
Limitations
Several factors may limit the generalizability of the results to state-of-the-art LMs. The KG differs from the data normally used for LM training, and the LMs trained in this study are significantly smaller than state-of-the-art LMs. Additionally, the study focuses on hallucinations resulting from not remembering something that appeared verbatim in the training data, which may not translate to other types of hallucinations.
Conclusion
The study sheds light on the relationship between LM hallucinations and their scale. Larger, longer-trained LMs hallucinate less, but increasing the dataset size also increases the hallucination rate. Achieving a low hallucination rate requires LMs much larger than currently considered optimal, trained for much longer. The detectability of hallucinations is inversely proportional to the LM size, making it harder to detect hallucinations in larger, more powerful LMs.
This research highlights the trade-offs between reducing hallucination rates and other performance metrics, and the challenges in detecting hallucinations in large LMs. Future work may explore alternative methods for reducing and detecting hallucinations, such as retrieval-augmentation or self-correction techniques.