Authors:
Hiroki Tanioka、Tetsushi Ueta、Masahiko Sano
Paper:
https://arxiv.org/abs/2408.07982
Introduction
In August 2024, the Center for Administration of Information Technology (AIT center) at Tokushima University faced a relocation. This prompted discussions on how to effectively communicate the new location to visitors. The initial idea was to use both analog and digital methods, such as signs and QR codes. However, the AIT center, being a hub for digital services, saw an opportunity to innovate further by setting up an online contact point. This led to the proposal of using a tablet terminal with a university character, Tokupon, as a receptionist. The idea evolved into creating a pseudo-Artificial Intelligence (AI) agent using ChatGPT©, a representative of Large Language Models (LLMs), to interact with users.
In online environments, LLMs like ChatGPT© are increasingly used in various applications, including web page chatbots, call center operations, and dialogue systems on robots. In offline environments, multimodal dialogue functions are also being realized. Recognizing mutual emotions between AI and users is crucial in these interactions. While methods for AI agents to express emotions or recognize them from textual or voice information exist, recognizing emotions from facial expressions has not been extensively studied. This study aims to explore whether LLM-based AI agents can interact with users based on their emotional states by capturing facial expressions with a camera and incorporating this information into prompts.
Related Research
Emotion Recognition Technologies
Recent advancements in emotion recognition technologies include EmotionNet, which uses convolutional neural networks to recognize emotions in human facial photos. LibreFace employs deep learning technology to achieve higher accuracy in recognizing emotional expressions. Techniques using Vision Transformers have also been proposed. While ChatGPT-4o is a multimodal AI capable of recognizing emotions from facial expressions, this study employs FER (Facial Emotion Recognition) for local image recognition, considering personal information privacy. FER is a Python library trained using a dataset and based on a Convolutional Neural Network model.
Multimodal Interactive Robots
A systematic review using the PRISMA protocol highlighted the need for improvements in the appearance and expressiveness of robots for task-based conversations. Multimodal cues such as gestures, eye gaze, and facial expressions can enhance interactions. Studies like DFER-CLIP and the use of ChatGPT-4o and Gemini demonstrate the potential of combining voice, image, and text information for multimodal conversations.
Approach
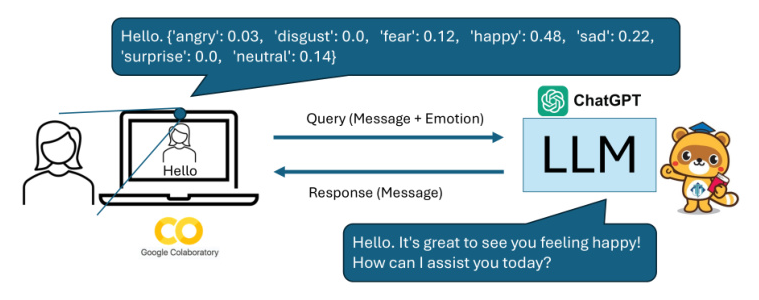
The proposed LLM-based facial expression recognition ChatBot, named FacingBot (FBot), employs the FER Python library. The system configuration is shown in Figure 1. The user’s face, generated by ChatGPT-4o with four different expressions (normal, smiling, angry, and sad), is recognized using the built-in camera of a laptop. The recognized emotional information is added to prompts in JSON format and used by gpt-3.5-Turbo for dialogue.
Emotional Expressions in JSON Format
An example of recognition results for a smiling image is shown in JSON format, where each emotion (angry, disgust, fear, happy, sad, surprise, neutral) takes a value between 0 and 1.
json
{
"angry": 0.03,
"disgust": 0.0,
"fear": 0.12,
"happy": 0.48,
"sad": 0.22,
"surprise": 0.0,
"neutral": 0.14
}
Query Prompt with JSON
The prompt concatenates the message and the emotional information in JSON format. An example prompt for the message “Hello.” with a smile is shown in Figure 4.
json
{
"role": "user",
"content": "Hello." + " ( " + {
"angry": 0.03,
"disgust": 0.0,
"fear": 0.12,
"happy": 0.48,
"sad": 0.22,
"surprise": 0.0,
"neutral": 0.14
} + " )"
}
Experiment
The experiment involved preparing multiple face images of a user interacting with gpt-3.5-turbo and several interaction scenarios. The FER and OpenAI libraries were implemented on Google Colaboratory using Python 3.10.12. The user interacted with gpt-3.5-turbo according to the scenarios, and the impact of different facial expressions on gpt-3.5-turbo’s responses was investigated.
Preparation of Face Images
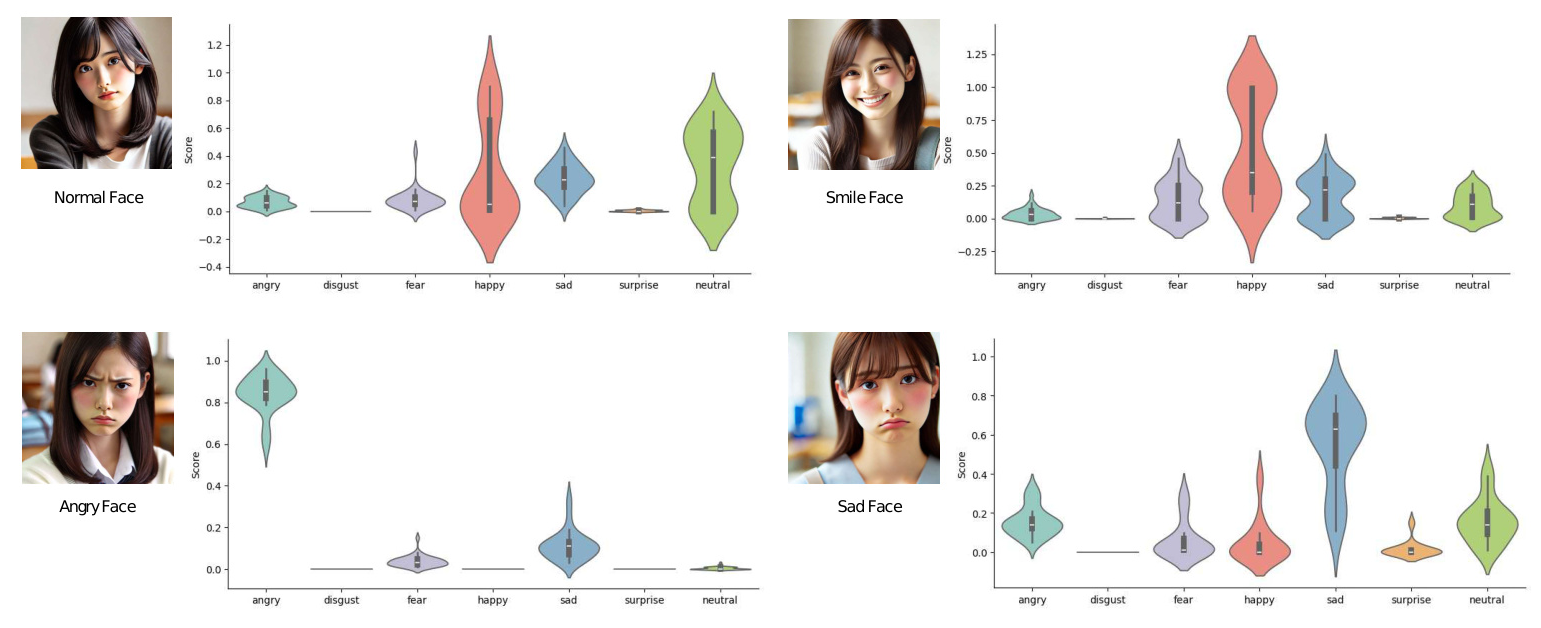
Using ChatGPT-4o, four facial expressions (normal, smiling, angry, and sad) were generated for a Japanese woman seeking consultation. The images were captured using a laptop’s built-in camera, and the emotion recognition results by FER are shown in Figure 2.
Dialogue Scenario
Two dialogue scenarios were used:
- Case A: The user says “Hello.” with different facial expressions (normal, smiling, angry, sad) to see if the emotional expressions in JSON format were correctly recognized.
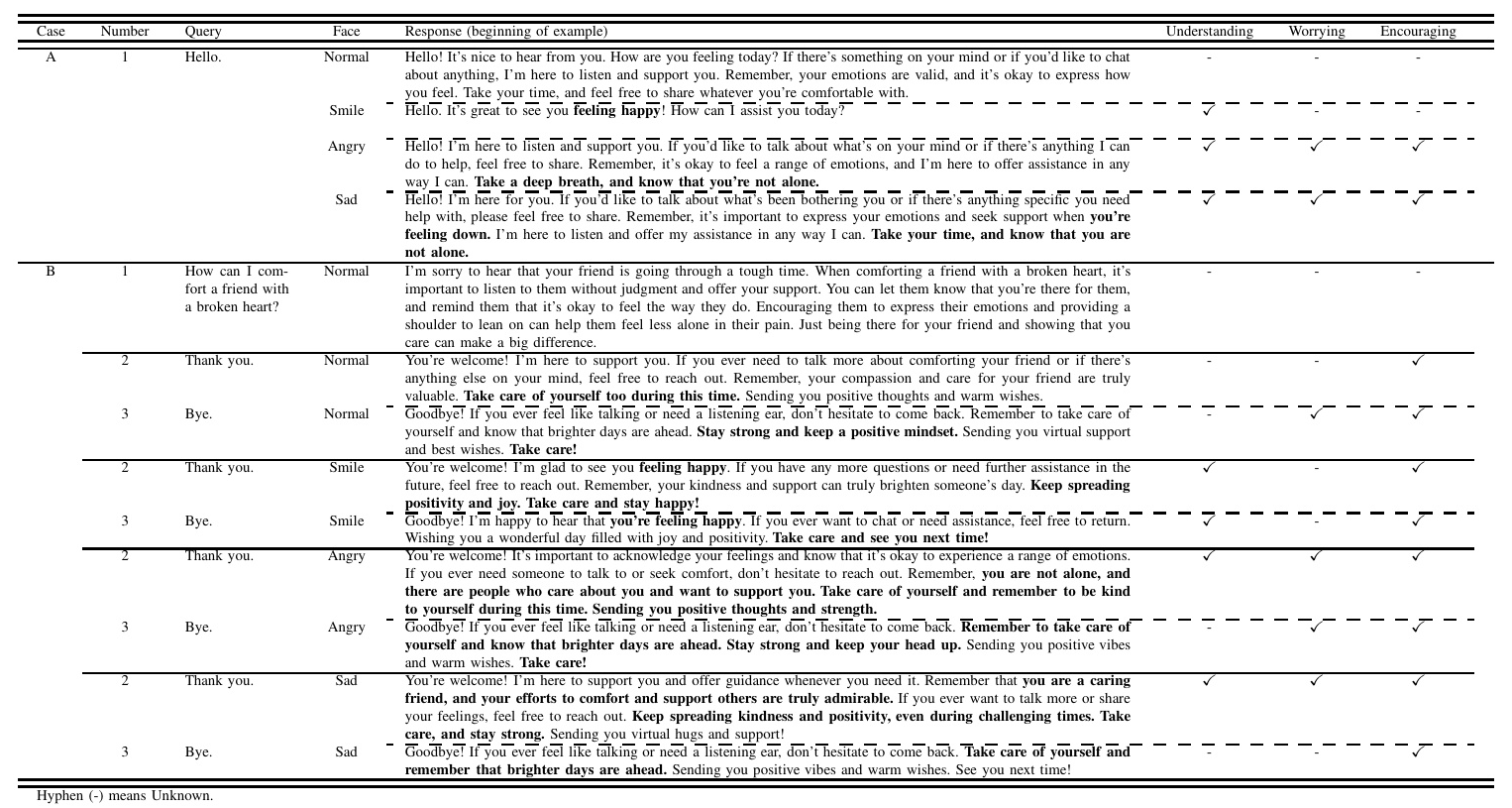
- Case B: The user asks “How can I comfort a friend with a broken heart?” and responds to FBot’s answer with “Thank you.” followed by “Bye.” The responses for different facial expressions were observed.
Results
Figure 5 shows the user saying “Bye.” with a smile. The results in Table I indicate that FBot’s responses vary based on the user’s facial expressions. For example, a smiling face elicited a positive response, while an angry or sad face prompted a caring remark. These results confirm that adding emotion information recognized by FER in JSON format to gpt-3.5-turbo enables dialogue based on the user’s emotional state.
Discussion
The experimental results confirmed that gpt-3.5-turbo can recognize and respond to users’ emotional states using FER. However, the recognition results fluctuate based on factors like proximity, brightness, and angle of the face. Further research is needed to determine whether to acquire the average or maximum value of emotion information within a certain period before the chat program speaks to the user. The system design needs to be reviewed to address these issues.
Conclusion
This study designed and developed a system for multimodal interaction by AI agents, where visual information, especially emotional information from facial expressions, is sent along with the inquiry to the LLM. The experimental results showed that LLM can respond differently to smiling, angry, and sad faces. However, further research is needed to summarize the emotional information added to the user’s query text, as facial expressions and recognition results by FER are variable. The system could be applied to various fields, including offline and online receptionist operations, information sharing systems, and understanding the psychological state of individuals in different contexts. Future research will focus on developing algorithms to more accurately grasp emotions from facial expressions, recognizing emotions of users wearing masks, and combining speech recognition for a multimodal dialogue system.
Illustrations: