Authors:
João Gonçalves、Nick Jelicic、Michele Murgia、Evert Stamhuis
Paper:
https://arxiv.org/abs/2408.06931
The Advantages of Context-Specific Language Models: The Case of the Erasmian Language Model
Introduction
Large Language Models (LLMs) have become a focal point in machine learning, with significant investments aimed at enhancing their performance. The prevailing trend involves scaling up the number of parameters and the volume of training data. However, this approach incurs substantial computational, financial, and environmental costs, and raises privacy concerns. This paper introduces the Erasmian Language Model (ELM), a context-specific, 900-million parameter model developed for Erasmus University Rotterdam. The ELM demonstrates that smaller, context-specific models can perform adequately in specialized domains, offering a viable alternative for resource-constrained and privacy-sensitive applications.
Improving Language Model Efficiency
The performance of LLMs is often gauged using standardized benchmarks like Massive Multitask Language Understanding (MMLU). However, the pursuit of higher performance through scaling up parameters and training data has significant drawbacks, including environmental impact and resource concentration in a few organizations. Efforts to improve efficiency, such as quantization and knowledge distillation, have shown promise but do not fully address the need for larger models. An alternative approach involves training smaller models that excel in specific contexts, leveraging high-quality data over large quantities.
Context-Specific Language Models
Context-specific models focus on excelling within a particular domain, challenging the assumption that general-purpose models always outperform specialized ones. Examples include models trained exclusively on programming code or financial data. These models mitigate some computational costs and privacy concerns by restricting the training dataset to relevant data. The ELM follows this approach, being trained exclusively on data from Erasmus University Rotterdam, ensuring alignment with the institution’s specific needs and values.
Epistemic-Functional Approach
The decision to develop context-specific models is not purely technical but also involves considering the values and norms of the community. The epistemic-functional approach links functionality to the knowledge processes within a community, ensuring that the model fits the epistemic needs and capacities of its users. This approach emphasizes the involvement of the community in the development process, ensuring that the model aligns with their values and expectations.
Methods
Model Architecture
The ELM is based on the LLaMA 2 architecture, scaled down to 160 million and 900 million parameters for different use cases. The smaller model serves as a teaching tool, while the larger model supports research and education tasks. A custom tokenizer was developed to ensure domain-specific performance.
Datasets
The ELM was pre-trained on a corpus of documents produced by Erasmus University Rotterdam, including research papers and theses. This dataset, consisting of approximately 2.7 billion tokens, ensures that the model reflects the institution’s knowledge and context.
EUR Research Output
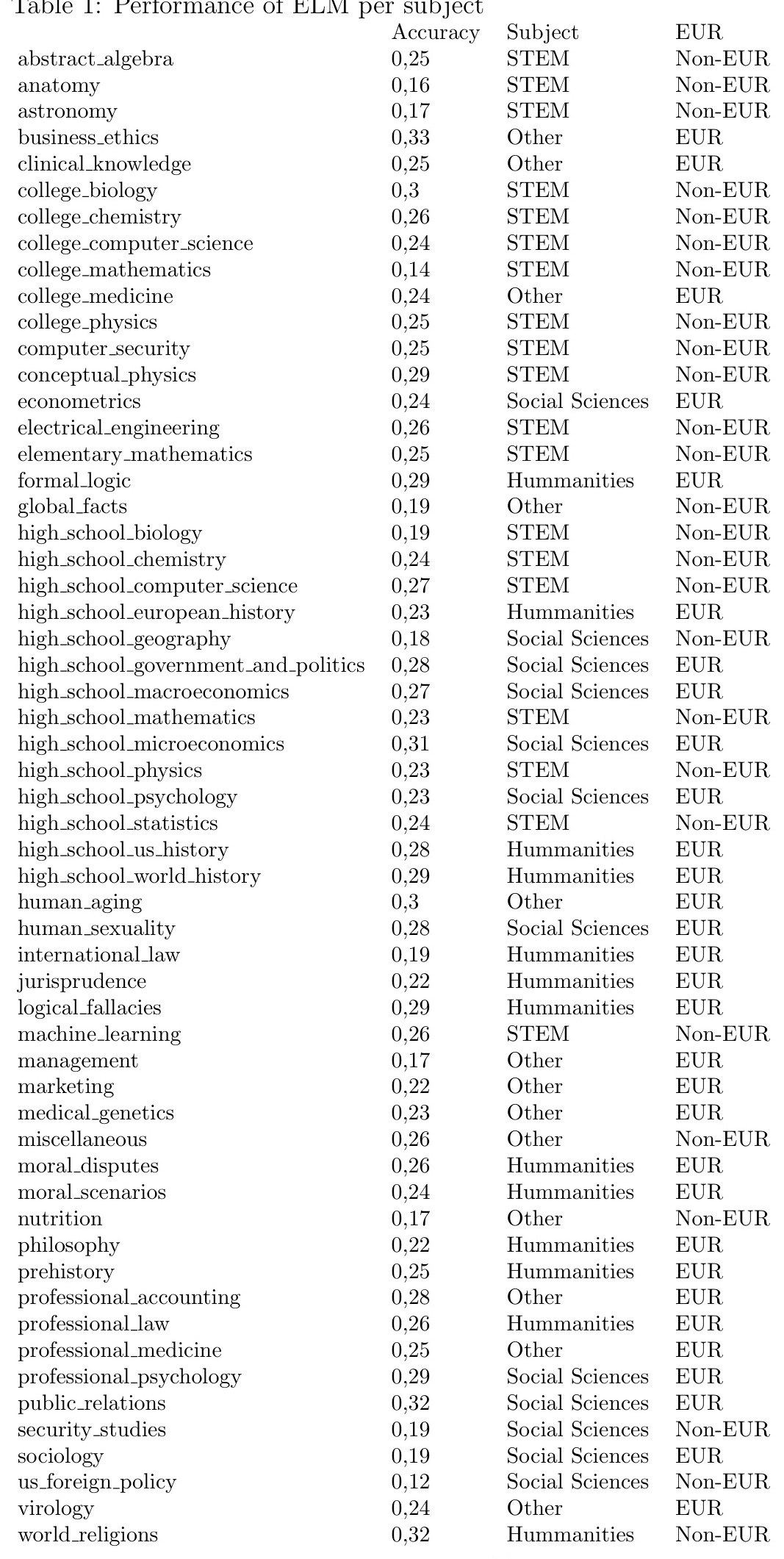
The research output dataset includes 75,355 documents from 1977 to 2023, totaling 1.9 billion tokens. These documents are primarily in English and Dutch.
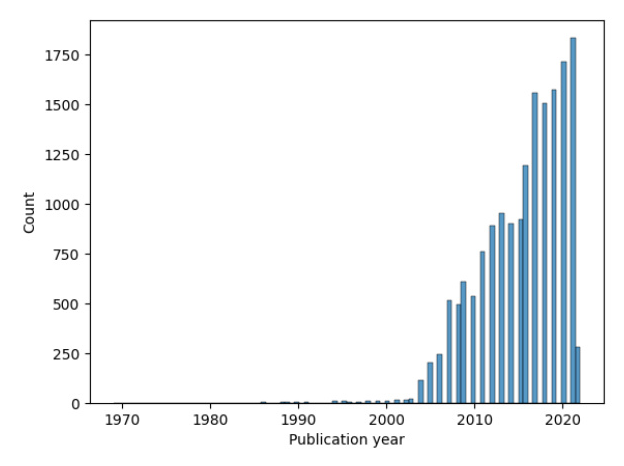
EUR Theses
The thesis dataset includes 16,983 theses from 1969 to 2022, totaling 864 million tokens. Only public theses were used to preserve privacy.
Instruction Dataset
An instruction dataset was constructed with 485 input-output pairs, supplemented with the Alpaca dataset and its Dutch translation to ensure the model could follow instructions effectively.
Reinforcement Learning
A dataset for direct preference optimization was created, allowing student assistants to choose the best output from two generated by the model. This approach eliminated the need for post-training filtering.
Training
The ELM-small model was pre-trained on a single Nvidia A10 GPU for 48 hours, while the ELM-medium model took 720 hours. Fine-tuning was conducted using low-rank adaptation and reinforcement learning with human feedback. The training process was conducted on the secure SURF research cloud, demonstrating the feasibility of training context-specific models with limited resources.
Results
Qualitative Assessment
Qualitative assessment involved students using the ELM-small model to write essays and reflecting on its performance. Students found the model’s outputs coherent and aligned with academic language but noted limitations in generating long texts and maintaining coherence on abstract topics.
Quantitative Assessment
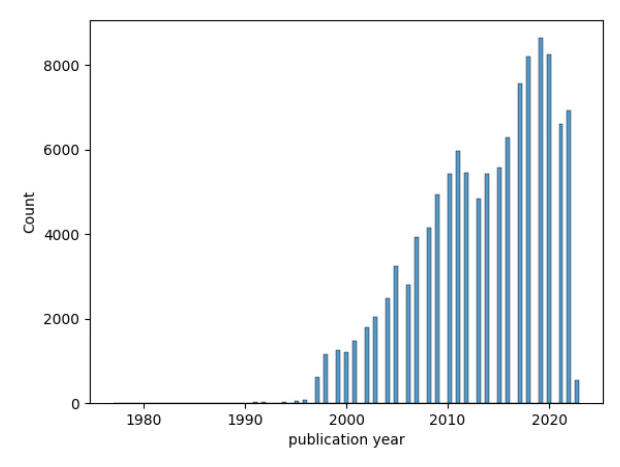
The ELM’s performance was assessed using the MMLU benchmark, focusing on subjects relevant to Erasmus University. The model specialized in social sciences and humanities, aligning with the university’s profile.
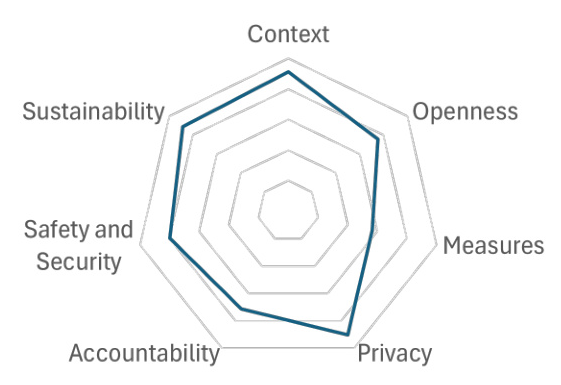
COMPASS Assessment
The COMPASS framework was used to evaluate the ELM’s trustworthiness across several criteria. The model scored highly in context definition, privacy, and sustainability but identified areas for improvement in defining success metrics and embedding explainability methods.
Conclusion
The ELM demonstrates that context-specific models can achieve acceptable performance with limited resources, offering a viable alternative to large commercial models. The iterative development process, involving feedback from students, highlighted the benefits of smaller, context-bound models. The ELM serves as a proof of concept, showing that organizations with resource constraints can develop effective language models tailored to their specific needs.
Acknowledgements
The authors acknowledge the contributions of Ilias McAuliffe and Marios Papamanolis in dataset production and model development. The project was funded by Convergence AI, Data & Digitalisation, and Erasmus Trustfonds, with logistical support from the Erasmus Center for Data Analytics, SURF, and the Erasmus Future Library Lab. Special thanks to the students of the AI and Societal Impact minor for their feedback.
Author Contributions
João Gonçalves coordinated the technical development of ELM and wrote the majority of the paper. Nick Jelicic developed a substantial part of the code and acquired the data. Michele Murgia led the project, wrote the section on the epistemic-functional approach, and managed student assistants. Evert Stamhuis provided insights and facilitated collaboration.