

Authors:
Yuankun Xie、Xiaopeng Wang、Zhiyong Wang、Ruibo Fu、Zhengqi Wen、Haonan Cheng、Long Ye
Paper:
https://arxiv.org/abs/2408.06922
Introduction
The rapid advancement of text-to-speech (TTS) and voice conversion (VC) technologies has led to a significant increase in deepfake speech, making it challenging for humans to discern real from fake. The ASVspoof challenge series aims to foster the development of countermeasures (CMs) to discriminate between genuine and spoofed speech utterances. The fifth edition, ASVspoof5, focuses on deepfake detection and is divided into two tracks: the deepfake detection track and the SASV task. This paper addresses the problem of open-domain audio deepfake detection in ASVspoof5 Track 1 open condition, exploring various CMs, including data expansion, data augmentation, and self-supervised learning (SSL) features.
Countermeasure
Data Expansion
In the open condition, expanding the training data is permissible, making it crucial to enhance the generalization of the CM. Several representative datasets were selected for co-training with the ASVspoof5 training set, ensuring no overlap with the ASVspoof5 source domain and maintaining data quality and diversity in spoofing techniques.
- ASVspoof2019LA (19LA): Includes six spoofing methods in the training and development sets and thirteen in the test set, totaling 96,617 speech samples.
- MLAAD: Utilizes 54 TTS models and 21 different architectures, comprising 76,000 speech samples.
- Codecfake: Designed for Audio Language Model (ALM) based audio detection, containing 1,058,216 audio samples synthesized using seven different neural codecs. A subset of 79,369 audio samples was selected for co-training.
Data Augmentation
Freqmask Data Augmentation Method
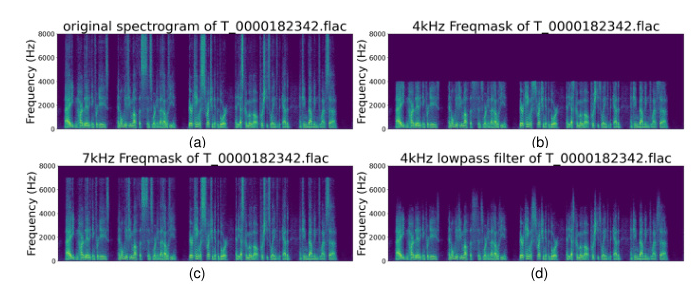
The ASVspoof5 dataset exhibits high-frequency band gaps, which significantly impact CM performance. To address this, a novel augmentation method called Frequency Mask (Freqmask) was proposed. This method randomly masks frequency bands to simulate the high-frequency band gap phenomenon, enhancing CM robustness.
Algorithm 1: Freqmask Method
1. Compute the Short-Time Fourier Transform (STFT) of the input speech.
2. Choose a random frequency threshold.
3. Mask the magnitude of frequencies greater than the threshold.
4. Compute the Inverse STFT to obtain the augmented speech.
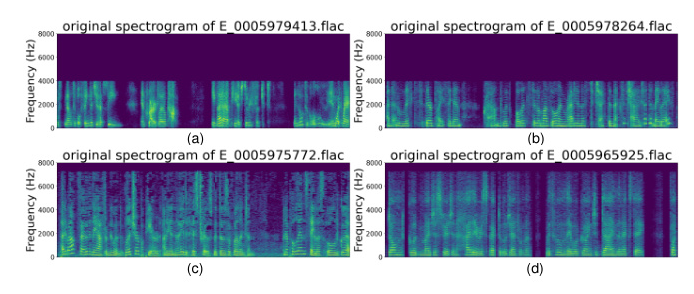
Other Data Augmentation Methods
To better fit real-world scenarios, additional data augmentation techniques were applied, including MUSAN and RIR for noise augmentation, high-pass filtering, pitch shifting, and time stretching.
Self-Supervised Learning Feature
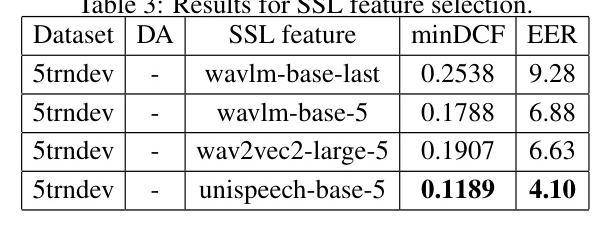
SSL Feature Selection
In the open condition, SSL pre-trained features play a crucial role. The following SSL features were investigated:
- WavLM: Built on the HuBERT framework, emphasizing spoken content modeling and speaker identity preservation.
- Wav2vec2-large: Learns robust representations solely from speech audio.
- UniSpeech: Enhances SSL framework for speaker representation learning by integrating multi-task learning and mixing strategies.
Reconsidering the Time Duration Length
The choice of audio length for SSL feature extraction was reconsidered, exploring durations from 4 to 16 seconds. The optimal duration was found to be 10 seconds, balancing the need for temporal information and model performance.

Backbone
The AASIST backbone network was employed, adapted for SSL features. The front-end dimension of the fully connected (FC) layer was adjusted to match the SSL dimensions.
Experiments
Details of ASVspoof5 Dataset
The ASVspoof5 dataset includes training, development, evaluation progress, and evaluation full sets, with varying spoofing methods and audio durations. Detailed analysis of the duration distribution was conducted to inform CM development.

Implementation Details
Experiments were conducted with a consistent set of parameters, including an initial learning rate, training epochs, and a weighted cross-entropy loss function to address data imbalance. Performance was evaluated using minDCF and EER metrics.
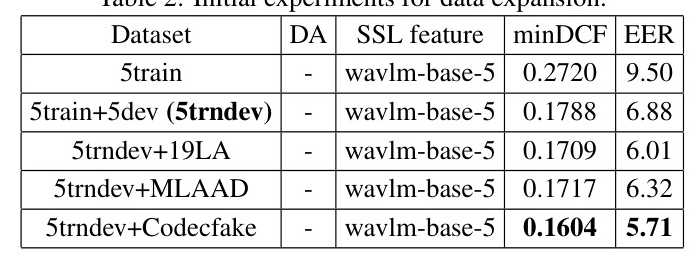
Initial Results for Data Expansion and Feature Selection
Initial experiments determined the effectiveness of various datasets and SSL features. The 5trndev dataset (combining 5train and 5dev) and the unispeech-base-5 feature were found to be the most effective.
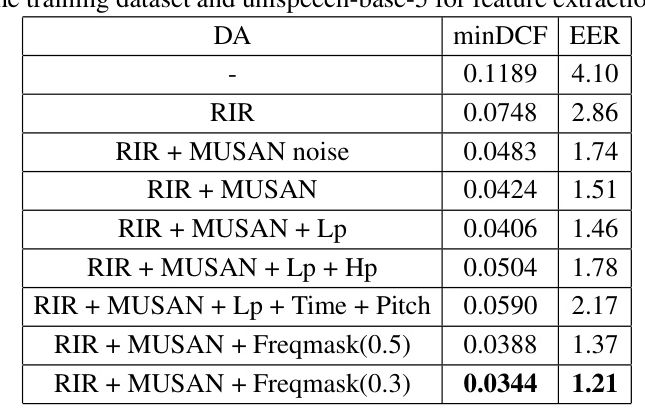
Results for Data Augmentation
Data augmentation significantly enhanced CM performance, with the combination of RIR, MUSAN, and Freqmask achieving the best results.
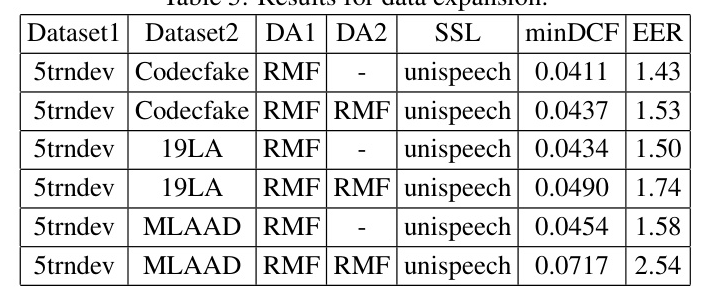
Results for Data Expansion
Applying data augmentation to additional expanded data did not significantly improve CM performance, indicating the importance of domain-specific data.
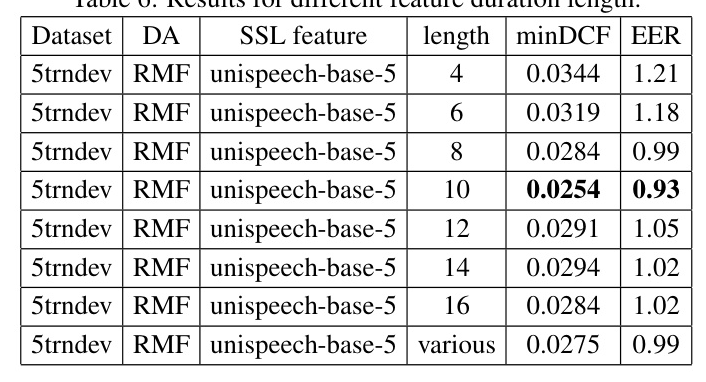
Results for Different Feature Length
The optimal feature duration for CM performance was found to be 10 seconds. Variable-length training did not outperform the fixed 10-second scheme.
Temporal Variability and Multi-Viewed SSL Fusion for Final Result
Combining CMs with different durations and SSL features provided a comprehensive evaluation of audio authenticity. The final fusion system achieved a minDCF of 0.0158 and an EER of 0.55% on the ASVspoof5 evaluation progress set.
Conclusion
This paper addressed the ASVspoof5 Track 1 open condition, proposing a novel data augmentation method (Freqmask) and integrating multiple CMs from temporal and feature-type perspectives. The results achieved promising performance on the evaluation progress set, though performance declined on the evaluation full set. Future work will focus on optimizing CM performance on the evaluation full set.
Acknowledgements
This work is supported by the National Natural Science Foundation of China (NSFC) (No.62101553).
References
A comprehensive list of references is provided, detailing the sources and related works cited in this study.