

Authors:
Ananya Pandey、Dinesh Kumar Vishwakarma
Paper:
https://arxiv.org/abs/2408.10248
Introduction
In the digital age, social media platforms like Twitter, Instagram, and Facebook are inundated with multimodal content, combining text and images. Analyzing this content to understand public sentiment towards specific topics is crucial for various applications, from marketing to public opinion analysis. Traditional Aspect-Based Sentiment Analysis (ABSA) focuses on determining sentiment polarity towards specific attributes within text. However, with the rise of multimodal content, relying solely on text is insufficient. This study introduces a novel approach called the Visual-to-Emotional-Caption Translation Network (VECTN) to enhance Target-Dependent Multimodal Sentiment Analysis (TDMSA) by incorporating visual emotional clues, particularly facial expressions, into the sentiment analysis process.
Related Work
Target-Dependent Unimodal Sentiment Recognition
Aspect-based sentiment analysis has evolved significantly, with early methods relying on handcrafted features and statistical learning techniques. The advent of deep learning introduced models like Bi-LSTM and attention mechanisms, which improved the representation of semantic interactions between target aspects and context words. However, these methods primarily focused on textual data, neglecting the visual elements prevalent in social media posts.
Target-Dependent Multimodal Sentiment Recognition
Recent research has explored multimodal sentiment analysis, integrating visual and textual data to improve sentiment prediction accuracy. Pioneering works like TomBERT and ESAFN utilized visual-caption pairs for sentiment analysis, employing models like ResNet and BERT for feature extraction and fusion. Despite these advancements, existing approaches often overlook the explicit use of facial emotional clues, which are crucial for understanding sentiments in multimodal content.
Research Methodology
Problem Formulation
The TDMSA problem is defined as follows: Given a collection of visual-caption pairs, each consisting of an image and a caption with a target entity, the goal is to develop a sentiment classifier that accurately predicts the sentiment label (positive, negative, or neutral) for the target entity. The proposed VECTN framework comprises four main components: Facial Emotion Description Module, Target Alignment and Refinement of Face Descriptions, Image Captioning, and Fusion Module.
Visual-to-Emotional-Caption Translation Network (VECTN)
The VECTN framework aims to convert visual emotional clues into textual descriptions and align them with the target entity in the caption. The process involves:
- Facial Emotion Description Module: Extracts facial attributes (age, gender, emotion) from images and generates textual descriptions.
- Target Alignment and Refinement: Aligns facial descriptions with the target entity using cosine similarity and refines the descriptions based on similarity scores.
- Image Captioning: Generates captions for the visual scenes using a transformer-based model.
- Fusion Module: Combines the refined face descriptions, image captions, and textual data using pre-trained language models and a gating mechanism to reduce noise and enhance feature representation.
Experimental Design
Datasets
The model was trained and evaluated on two publicly accessible benchmark datasets, Twitter-2015 and Twitter-2017, which include tweets with visual-caption pairs. A subset of these datasets, focusing on samples with facial images, was created to form the Tweet1517-Face dataset. The statistical information for these datasets is summarized in Table 4.

Training Details
The model’s learning rate was set to 2e-5, with a batch size of 32 and a dropout rate of 0.4. The training process involved fine-tuning for 15 epochs using the PyTorch framework on a high-end NVIDIA TITAN RTX GPU system. The final results were averaged over five independent training iterations.
Baselines for Comparison
The proposed model was compared with several state-of-the-art baseline approaches for TDMSA, including TomBERT, ESAFN, and others. The experimental results demonstrated that the VECTN model outperformed these baselines in terms of accuracy and macro-F1 score.
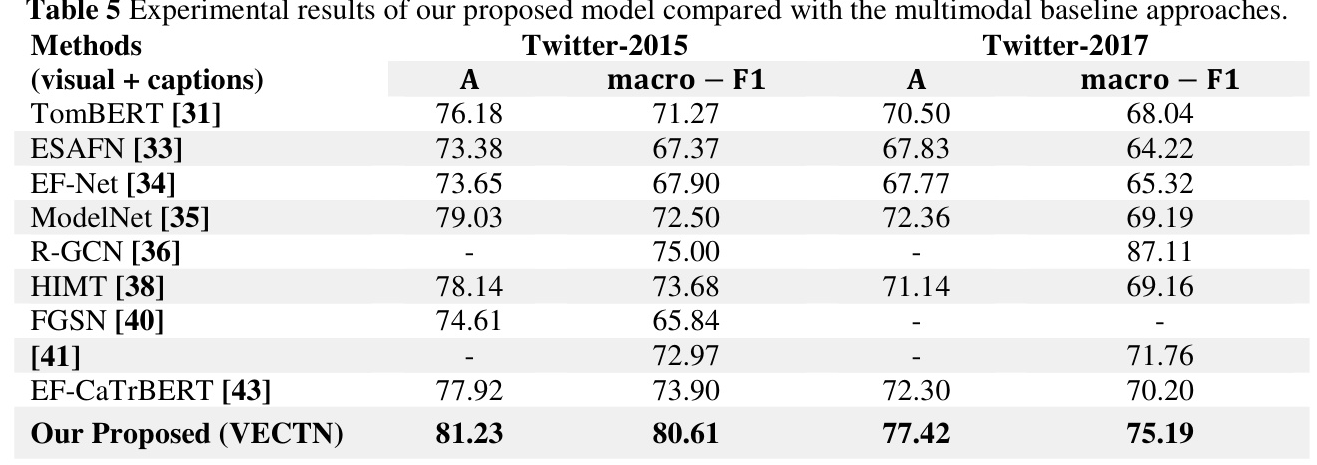
Results and Analysis
Performance Evaluation
The experimental results for the Twitter-2015, Twitter-2017, and Tweet1517-Face datasets are presented in Tables 6, 7, and 8, respectively. The VECTN model achieved superior performance compared to other multimodal baselines, highlighting the effectiveness of incorporating visual emotional clues into the sentiment analysis process.
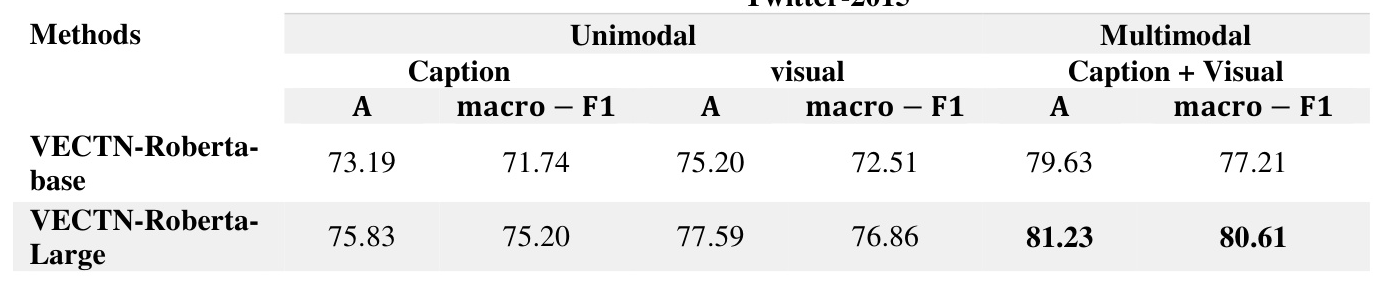


Ablation Study
An ablation study was conducted to evaluate the impact of each component of the VECTN framework. The results indicated that the gating mechanism, target alignment, and visual captioning significantly contributed to the model’s performance. Excluding any of these components resulted in a noticeable decrease in accuracy and macro-F1 scores.

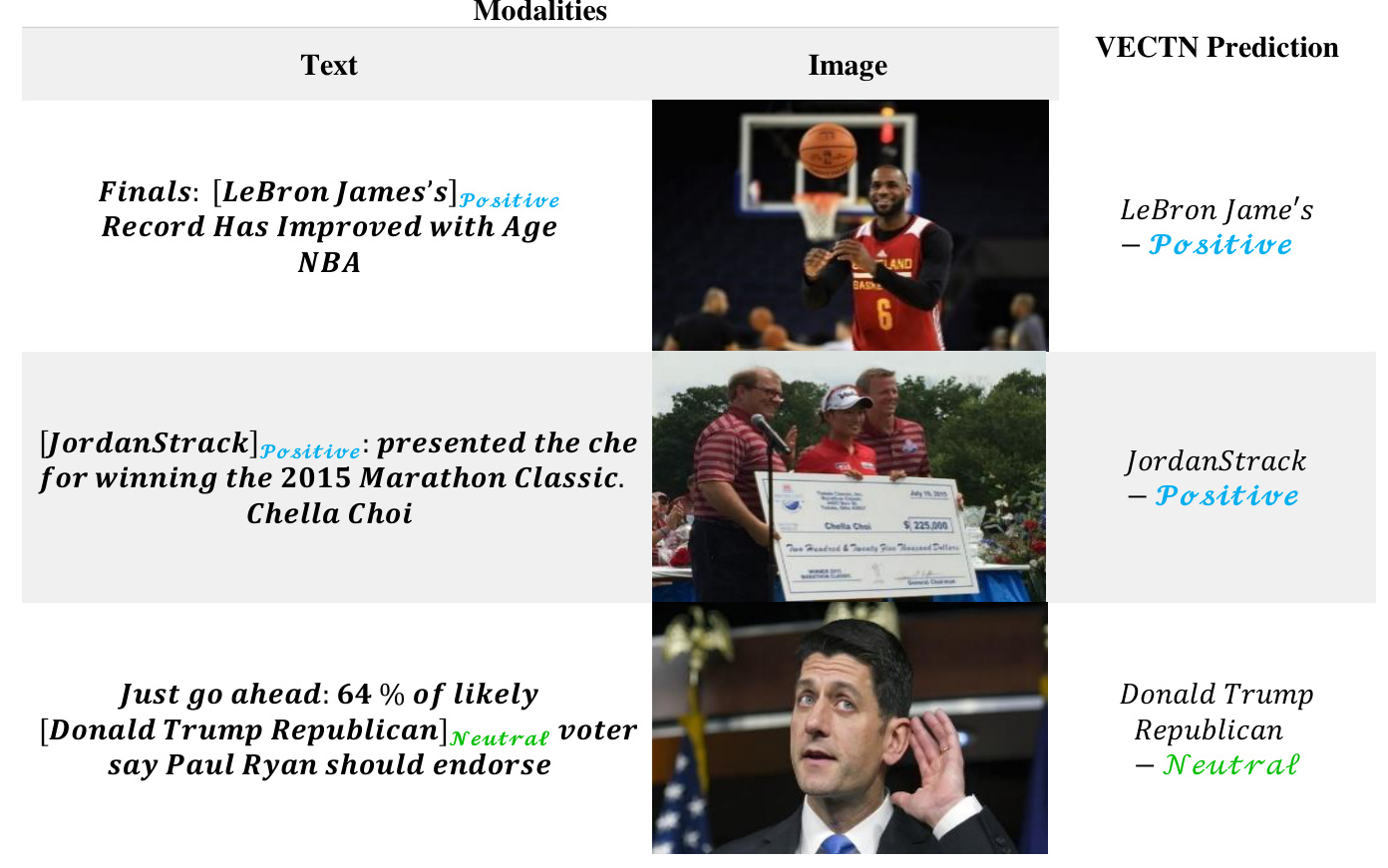
Predictive Analysis
The VECTN model’s predictions on a few samples from the Twitter-15 and Twitter-17 datasets demonstrated its ability to accurately forecast sentiments for various target entities. This analysis highlighted the model’s capability to leverage multimodal sentimental regions and establish a deeper semantic relationship between images and text.
Overall Conclusion
The study presents a novel approach to target-dependent multimodal sentiment analysis by employing the Visual-to-Emotional-Caption Translation Network (VECTN). The proposed method effectively integrates visual emotional clues, particularly facial expressions, with textual data to enhance sentiment prediction accuracy. The experimental results on benchmark datasets demonstrate the superiority of the VECTN model over existing approaches. Future work will explore extending this method to other multimodal tasks, such as hate speech detection, sarcasm identification, and fake news analysis, as well as analyzing emotions conveyed by videos.
