

Authors:
Yuxiong Xu、Jiafeng Zhong、Sengui Zheng、Zefeng Liu、Bin Li
Paper:
https://arxiv.org/abs/2408.09933
Introduction
Background
The rapid advancements in Artificial Intelligence Generated Content (AIGC) have significantly improved the naturalness, fidelity, and variety of synthetic speech. However, these advancements have also led to an increase in sophisticated forgeries that are nearly indistinguishable from authentic speech to the human ear. This poses a significant threat to Automatic Speaker Verification (ASV) systems, which are increasingly vulnerable to spoofing and deepfake attacks. These attacks can convincingly simulate a target speaker’s voice, presenting substantial societal risks.
Problem Statement
The ASVspoof challenges have been instrumental in driving the development of robust detection solutions for spoofing and deepfake attacks. The ASVspoof 5 Challenge, held in 2024, introduces new conditions and evaluation metrics to further enhance the security and reliability of ASV systems. This paper presents the SZU-AFS anti-spoofing system designed for Track 1 of the ASVspoof 5 Challenge under open conditions. The system aims to address the challenge of detecting standalone speech deepfake attacks using a multi-stage approach involving baseline model selection, data augmentation, co-enhancement strategies, and score fusion.
Related Work
Previous ASVspoof Challenges
The ASVspoof challenges have significantly contributed to the development of anti-spoofing technologies. Previous challenges have introduced various spoofing detection methods and provided standardized benchmark protocols and comprehensive evaluation datasets. The ASVspoof 5 Challenge continues this tradition by introducing new source data, attack types, and evaluation metrics.
Spoofing Detection Methods
Recent research has shown that using speech self-supervised models as front-end feature extractors and deep learning methods as back-end classifiers can substantially improve the generalization of spoofing detection models. Various data augmentation (DA) methods and optimization techniques, such as Sharpness-Aware Minimization (SAM) and its variants, have also been explored to enhance model generalization.
Research Methodology
Baseline Model Selection
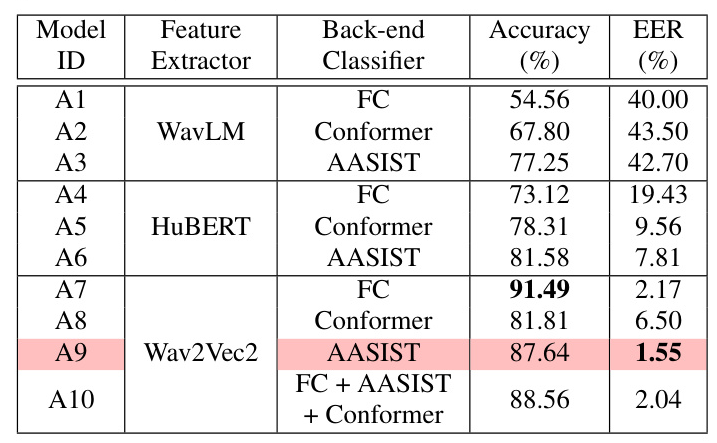
The SZU-AFS system begins with the selection of a baseline model. Three pre-trained self-supervised models—WavLM-Base, HuBERT-Base, and Wav2Vec2-Large—were evaluated as front-end feature extractors. These were combined with three different classifiers: Fully Connected (FC), Conformer, and AASIST. The Wav2Vec2-Large model paired with the AASIST classifier (A9 model) was selected as the baseline due to its superior performance in terms of Equal Error Rate (EER).
Data Augmentation
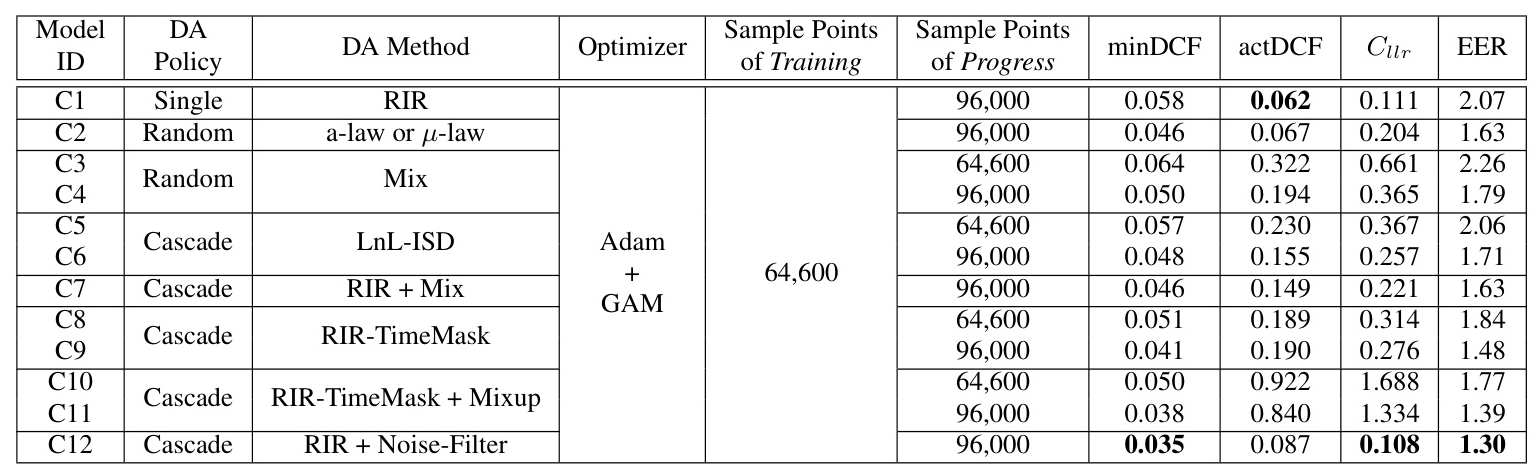
To enhance the generalization performance, three DA policies were explored: single-DA, random-DA, and cascade-DA. Various DA methods, including Room Impulse Response (RIR) noise, TimeMask, RawBoost, and Mixup, were applied to the training data. The RIR-TimeMask method was found to be the most effective, resulting in the B5 model, which was selected for further fine-tuning.
Co-enhancement Strategy
A Gradient Norm Aware Minimization (GAM)-based co-enhancement strategy was employed to further fine-tune the B5 model. This strategy combines DA methods with the GAM method to enhance model generalizability. The GAM method seeks flat minima with uniformly small curvature across all directions in the parameter space, thereby improving the generalization of models trained with the Adam optimizer.
Score-level Fusion
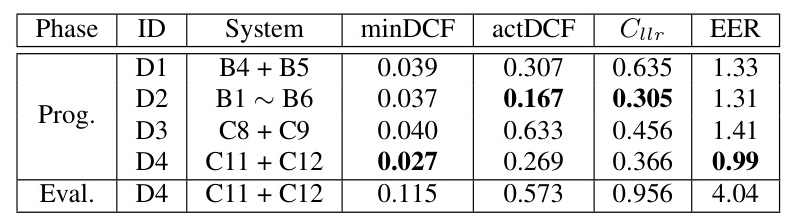
The final stage involves fusing the predicted logits scores from the two best-performing fine-tuned models (C11 and C12) using an average score-level fusion method. This fusion strategy aims to combine the strengths of individual models to achieve better overall performance.
Experimental Design
Datasets
The Track 1 database of the ASVspoof 5 Challenge was used for training and evaluation. The dataset contains 1,044,846 utterances, each encoded as a 16 kHz, 16-bit FLAC file. The training and development sets include spoofed speech generated by various text-to-speech (TTS) and voice conversion (VC) methods, while the evaluation set includes additional attack methods, including adversarial attacks.

Metrics
The primary evaluation metric for the ASVspoof 5 Challenge is the minimum Detection Cost Function (minDCF). Secondary metrics include the cost of log-likelihood ratio (Cllr) and the Equal Error Rate (EER). Accuracy (ACC) was also used to evaluate the detection model’s performance on the development set.
Training Details
The models were trained using the Adam optimizer with specific hyperparameters. The training process involved multiple stages, with early stopping applied if the development set loss did not improve within ten epochs. All experiments were conducted on two NVIDIA A100 GPUs.
Results and Analysis
Baseline Model Performance
The performance of different baseline models was evaluated on the Track 1 development set. The Wav2Vec2-based detection models achieved higher accuracy and lower EER compared to WavLM-based and HuBERT-based models. Among the classifiers, the AASIST classifier proved to be the most competitive. The A9 model, combining Wav2Vec2 and AASIST, was selected for further fine-tuning due to its outstanding EER performance.
Data Augmentation Effectiveness
Various DA methods were evaluated during the progress phase of Track 1. The RIR-TimeMask method significantly improved the model’s performance, resulting in the B5 model, which achieved the lowest minDCF, Cllr, and EER. The cascade-DA policy, particularly the RIR-TimeMask method, proved to be the most effective for data augmentation.

GAM-based Co-enhancement Strategy
The GAM-based co-enhancement strategy further improved the model’s performance. The combination of RIR-TimeMask and Mixup methods, along with the GAM method, resulted in the best-performing models (C11 and C12). These models demonstrated superior generalization capabilities.
Score-level Fusion
The score-level fusion of the C11 and C12 models (D4 system) resulted in optimal performance during the progress phase, achieving a minDCF of 0.027 and an EER of 0.99%. However, the D4 system exhibited a significant performance discrepancy between the progress and evaluation phases, highlighting the challenging nature of the evaluation set.
Overall Conclusion
The SZU-AFS anti-spoofing system for Track 1 of the ASVspoof 5 Challenge demonstrates the effectiveness of combining data augmentation and GAM-based co-enhancement strategies to improve spoofing detection generalization. The final fused system achieved a minDCF of 0.115 and an EER of 4.04% on the evaluation set. Key findings include the effectiveness of the RIR-TimeMask method for data augmentation and the significant improvement in model generalization achieved by the GAM method. Future work could explore the use of the GAM method throughout the entire training process to potentially achieve even better results.
Acknowledgments
We would like to thank the organizers for hosting the ASVspoof 5 Challenge. This work was supported in part by NSFC (Grant U23B2022, U22B2047) and Guangdong Provincial Key Laboratory (Grant 2023B1212060076).
References
- Zhizheng Wu, Nicholas Evans, Tomi Kinnunen, Junichi Yamagishi, Federico Alegre, and Haizhou Li, “Spoofing and countermeasures for speaker verification: A survey,” Speech Communication, vol. 66, pp. 130–153, 2015.
- Zhizheng Wu, Tomi Kinnunen, Nicholas W. D. Evans, Junichi Yamagishi, Cemal Hanilc ¸i, Md. Sahidullah, and Aleksandr Sizov, “ASVspoof 2015: the first automatic speaker verification spoofing and countermeasures chal- lenge,” in Proc. Interspeech, 2015, pp. 2037–2041.
- Tomi Kinnunen, Md. Sahidullah, H´ ector Delgado, Massi- miliano Todisco, Nicholas W. D. Evans, Junichi Yamag- ishi, and Kong-Aik Lee, “The ASVspoof 2017 challenge: Assessing the limits of replay spoofing attack detection,” in Proc. Interspeech, 2017, pp. 2–6.
- Massimiliano Todisco, Xin Wang, Ville Vestman, Md. Sahidullah, H´ ector Delgado, Andreas Nautsch, Junichi Yamagishi, Nicholas W. D. Evans, Tomi H. Kinnunen, and Kong Aik Lee, “ASVspoof 2019: Future horizons in spoofed and fake audio detection,” in Proc. Interspeech, 2019, pp. 1008–1012.
- Junichi Yamagishi, Xin Wang, Massimiliano Todisco, Md Sahidullah, Jose Patino, Andreas Nautsch, Xuechen Liu, Kong Aik Lee, Tomi Kinnunen, Nicholas Evans, et al., “ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection,” in Proc. ASVspoof Chal- lenge Workshop, 2021, pp. 47–54.
- Xin Wang, H´ ector Delgado, Hemlata Tak, Jee-weon Jung, Hye-jin Shim, Massimiliano Todisco, Ivan Kukanov, Xuechen Liu, Md Sahidullah, Tomi Kinnunen, Nicholas Evans, Kong Aik Lee, and Junichi Yamagishi, “ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,” in ASVspoof Workshop 2024 (accepted), 2024.
- Tianxiang Chen, Avrosh Kumar, Parav Nagarsheth, Ganesh Sivaraman, and Elie Khoury, “Generalization of audio deepfake detection,” in Proc. Odyssey, 2020, pp. 132–137.
- Jo˜ ao Monteiro, Jahangir Alam, and Tiago H. Falk, “Gen- eralized end-to-end detection of spoofing attacks to au- tomatic speaker recognizers,” Computer Speech & Lan- guage, vol. 63, pp. 101096, 2020.
- Xin Wang and Junichi Yamagishi, “A comparative study on recent neural spoofing countermeasures for synthetic speech detection,” in Proc. Interspeech, 2021, pp. 4259– 4263.
- You Zhang, Fei Jiang, and Zhiyao Duan, “One-class learn- ing towards synthetic voice spoofing detection,” IEEE Sig- nal Processing Letters, vol. 28, pp. 937–941, 2021.
- Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert, “MLS: A large-scale multilingual dataset for speech research,” in Proc. Inter- speech, 2020, pp. 2757–2761.
- Seyed Omid Sadjadi, Craig S Greenberg, Elliot Singer, Douglas A Reynolds, and Lisa Mason, “NIST 2020 CTS speaker recognition challenge evaluation plan,” 2020.
- Hye-jin Shim, Jee-weon Jung, Tomi Kinnunen, Nicholas W. D. Evans, Jean-Franc ¸ois Bonastre, and Itshak Lapidot, “a-DCF: an architecture agnostic metric with application to spoofing-robust speaker verification,” in Proc. Odyssey, 2024, pp. 158–164.
- Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli, “Wav2vec 2.0: A framework for self- supervised learning of speech representations,” in Proc. NIPS, 2020, vol. 33, pp. 12449–12460.
- Jee-weon Jung, Hee-Soo Heo, Hemlata Tak, Hye-jin Shim, Joon Son Chung, Bong-Jin Lee, Ha-Jin Yu, and Nicholas W. D. Evans, “AASIST: audio anti-spoofing us- ing integrated spectro-temporal graph attention networks,” in Proc. ICASSP, 2022, pp. 6367–6371.
- Juan M. Mart´ ın-Do˜ nas and Aitor ´ Alvarez, “The vi- comtech audio deepfake detection system based on wav2vec2 for the 2022 ADD challenge,” in Proc. ICASSP, 2022, pp. 9241–9245.
- Jin Woo Lee, Eungbeom Kim, Junghyun Koo, and Kyogu Lee, “Representation selective self-distillation and wav2vec 2.0 feature exploration for spoof-aware speaker verification,” in Proc. Interspeech, 2022, pp. 2898–2902.
- Jiafeng Zhong, Bin Li, and Jiangyan Yi, “Enhancing par- tially spoofed audio localization with boundary-aware at- tention mechanism,” arXiv preprint arXiv:2407.21611, 2024.
- Yujie Yang, Haochen Qin, Hang Zhou, Chengcheng Wang, Tianyu Guo, Kai Han, and Yunhe Wang, “A robust audio deepfake detection system via multi-view feature,” in Proc. ICASSP, 2024, pp. 13131–13135.
- Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xi- angzhan Yu, and Furu Wei, “WavLM: Large-scale self- supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
- Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrah- man Mohamed, “HuBERT: Self-supervised speech repre- sentation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021.
- Xin Wang and Junichi Yamagishi, “Spoofed training data for speech spoofing countermeasure can be efficiently cre- ated using neural vocoders,” in Proc. ICASSP, 2023, pp. 1–5.
- Eros Rosello, Alejandro G´ omez Alan´ ıs, Angel M. Gomez, and Antonio M. Peinado, “A conformer-based classifier for variable-length utterance processing in anti-spoofing,” in Proc. Interspeech, 2023, pp. 5281–5285.
- Hemlata Tak, Massimiliano Todisco, Xin Wang, Jee-weon Jung, Junichi Yamagishi, and Nicholas W. D. Evans, “Au- tomatic speaker verification spoofing and deepfake detec- tion using wav2vec 2.0 and data augmentation,” in Proc. Odyssey, 2022, pp. 112–119.
- Jiangyan Yi, Chenglong Wang, Jianhua Tao, Xiaohui Zhang, Chu Yuan Zhang, and Yan Zhao, “Audio deepfake detection: A survey,” arXiv preprint arXiv:2308.14970, 2023.
- Yuxiong Xu, Bin Li, Shunquan Tan, and Jiwu Huang, “Research progress on speech deepfake and its detection techniques,” Journal of Image and Graphics, vol. 29, no. 08, pp. 2236–2268, 2024.
- Hemlata Tak, Jose Patino, Massimiliano Todisco, Andreas Nautsch, Nicholas Evans, and Anthony Larcher, “End-to- end anti-spoofing with rawnet2,” in Proc. ICASSP, 2021, pp. 6369–6373.
- Hemlata Tak, Madhu R. Kamble, Jose Patino, Massim- iliano Todisco, and Nicholas W. D. Evans, “Rawboost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing,” in Proc. ICASSP, 2022, pp. 6382–6386.
- Hongyi Zhang, Moustapha Ciss´ e, Yann N. Dauphin, and David Lopez-Paz, “Mixup: Beyond empirical risk mini- mization,” in Proc. ICLR, 2018.
- Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur, “Sharpness-aware minimization for efficiently improving generalization,” in Proc. ICLR, 2021.
- Jungmin Kwon, Jeongseop Kim, Hyunseo Park, and In Kwon Choi, “ASAM: adaptive sharpness-aware min- imization for scale-invariant learning of deep neural net- works,” in Proc. ICML, 2021, vol. 139, pp. 5905–5914.
- Hye-jin Shim, Jee-weon Jung, and Tomi Kinnunen, “Multi-dataset co-training with sharpness-aware opti- mization for audio anti-spoofing,” in Proc. Interspeech, 2023, pp. 3804–3808.
- Xingxuan Zhang, Renzhe Xu, Han Yu, Hao Zou, and Peng Cui, “Gradient norm aware minimization seeks first-order flatness and improves generalization,” in Proc. CVPR, 2023, pp. 20247–20257.
- Niko Br¨ ummer and Johan A. du Preez, “Application- independent evaluation of speaker detection,” Computer Speech & Language, vol. 20, no. 2-3, pp. 230–275, 2006.
- Diederik P. Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” in Proc. ICLR, 2015.