

Authors:
Chao Xu、Ang Li、Linghao Chen、Yulin Liu、Ruoxi Shi、Hao Su、Minghua Liu
Paper:
https://arxiv.org/abs/2408.10195
Introduction
3D object reconstruction is a critical task with applications in various fields such as augmented reality, virtual reality, and robotics. Traditional methods often require dense view inputs, which are not always feasible in practical scenarios. Recent advancements in single-image-to-3D methods have shown promise but often lack controllability and produce hallucinated regions that may not align with user expectations. This paper introduces SpaRP, a novel method designed to reconstruct 3D textured meshes and estimate camera poses from sparse, unposed 2D images. SpaRP leverages 2D diffusion models to infer 3D spatial relationships and achieve efficient and accurate 3D reconstruction and pose estimation.
Related Work
Sparse-View 3D Reconstruction
Sparse-view 3D reconstruction is challenging due to the lack of visual correspondence between images. Traditional methods often fail when the baseline between images is large. Some approaches incorporate priors or use 2D diffusion models to generate novel views as additional input. However, these methods typically require known camera poses and are limited to small baselines. SpaRP overcomes these limitations by not requiring camera poses and being capable of generating 360-degree meshes efficiently.
Pose-Free Reconstruction
Pose-free reconstruction methods aim to jointly optimize the NeRF representation and camera parameters. However, these methods are prone to local minima and become unreliable with sparse views. Recent approaches have proposed generalizable solutions using neural networks and large vision models. SpaRP leverages the rich priors in pre-trained 2D diffusion models to predict camera poses and 3D mesh geometry in a single feedforward pass, providing exceptional generalizability.
Open-World 3D Generation
Recent advancements in 2D generative models and vision-language models have sparked interest in open-world 3D generation. While optimization-based methods produce impressive results, they are time-consuming. SpaRP addresses both 3D reconstruction and pose estimation challenges in a time-efficient manner, leveraging 2D diffusion models to handle unposed sparse views.
Research Methodology
Tiling Sparse View Images as Input Condition
SpaRP utilizes 2D diffusion models to process sparse input views by tiling them into a multi-view grid. This composite image serves as the condition for the diffusion model, which is finetuned to predict NOCS maps and multi-view images with known camera poses. The model uses both local and global conditioning strategies to enhance its understanding of the input sparse views and the intrinsic properties of the 3D objects.
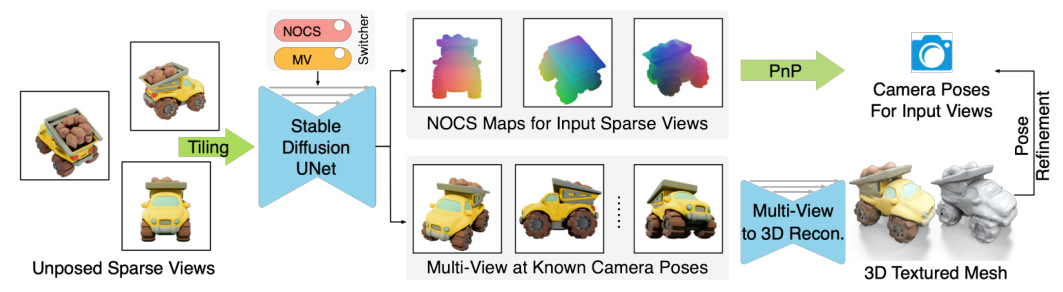
Image-to-NOCS Diffusion as a Pose Estimator
Instead of relying on local correspondences, SpaRP uses 2D diffusion models to predict NOCS maps, which represent the 3D coordinates of object points. These maps are used to estimate camera poses using the Perspective-n-Point (PnP) algorithm. The NOCS maps provide a common frame of reference, allowing the determination of relative camera poses between views.
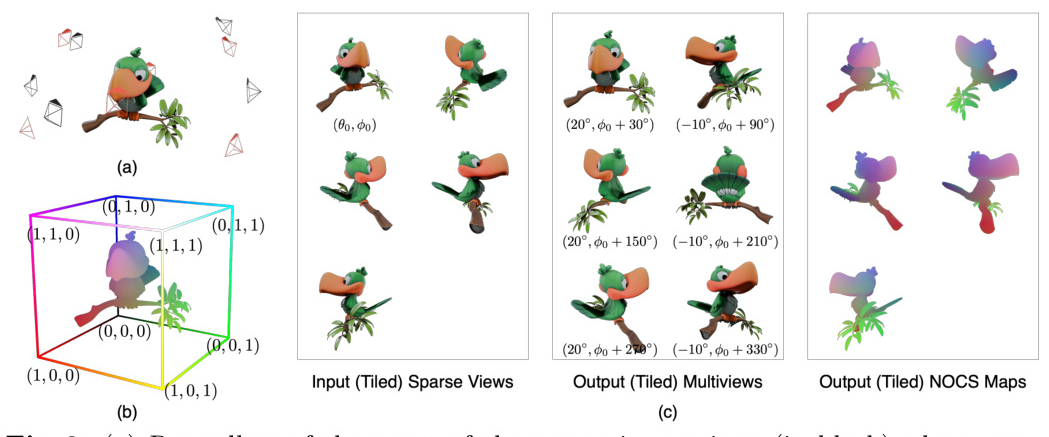
Multi-View Prediction for 3D Reconstruction
SpaRP predicts multi-view images at uniformly distributed camera poses and uses a 3D reconstruction module to convert these images into a 3D representation. The joint training of NOCS prediction and multi-view prediction branches enhances the performance of both tasks. The reconstruction module employs a two-stage coarse-to-fine approach to generate a high-resolution textured mesh.
Pose Refinement with Reconstructed 3D Model
The initial poses predicted from the NOCS maps can be further refined using the generated 3D mesh. Differentiable rendering is used to minimize the rendering loss between the input images and the rendered images from the generated mesh. A Mixture of Experts (MoE) strategy is employed to address ambiguity issues related to NOCS prediction for symmetric objects.
Experimental Design
Evaluation Settings
SpaRP is trained on a curated subset of the Objaverse dataset, filtered for high-quality data. The model is evaluated on the GSO, OmniObject3D, and ABO datasets, which include both real scans and synthetic objects. The evaluation metrics include rotation and translation errors, F-Score, CLIP-Sim, PSNR, and LPIPS.
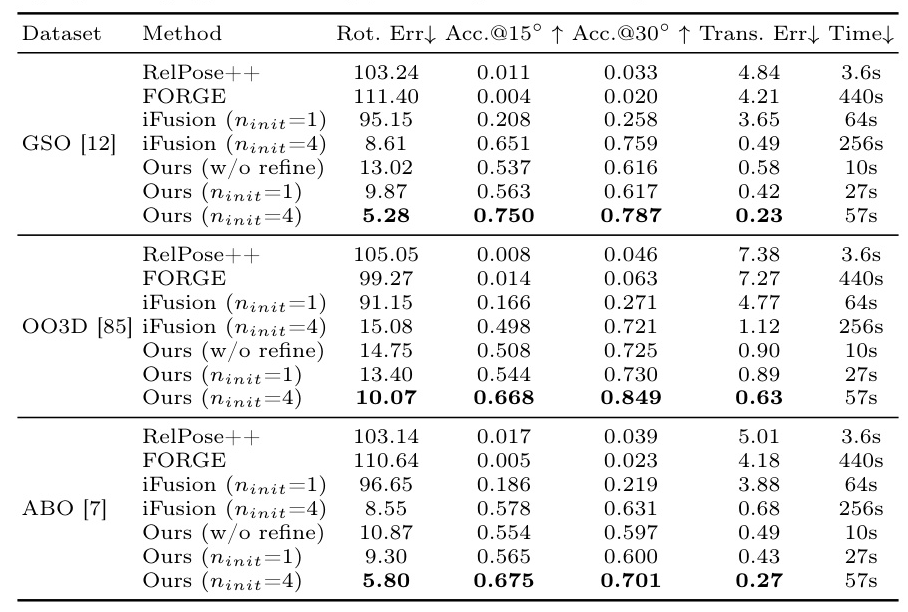
Baselines
For 3D reconstruction, SpaRP is compared with state-of-the-art single-image-to-3D and sparse-view-to-3D methods. For pose estimation, it is compared with RelPose++, FORGE, and iFusion. The evaluation demonstrates that SpaRP significantly outperforms these baselines in terms of both accuracy and efficiency.

Results and Analysis
Pose Prediction
SpaRP outperforms all baseline methods in pose estimation, demonstrating superior accuracy and efficiency. The method leverages 2D diffusion models to generate acceptable results in a single forward pass, with further refinement improving performance.
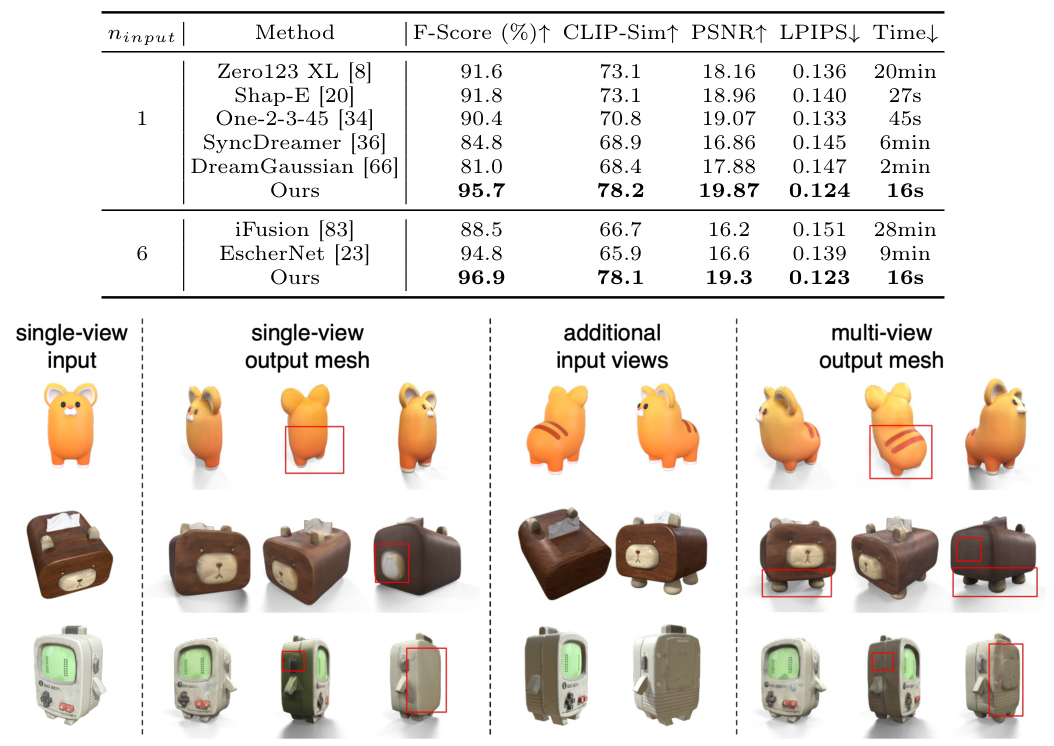
3D Reconstruction
SpaRP produces high-quality textured meshes that closely match the input sparse views. It outperforms both single-view-to-3D and sparse-view methods in terms of 2D and 3D metrics, demonstrating superior geometry and texture quality.
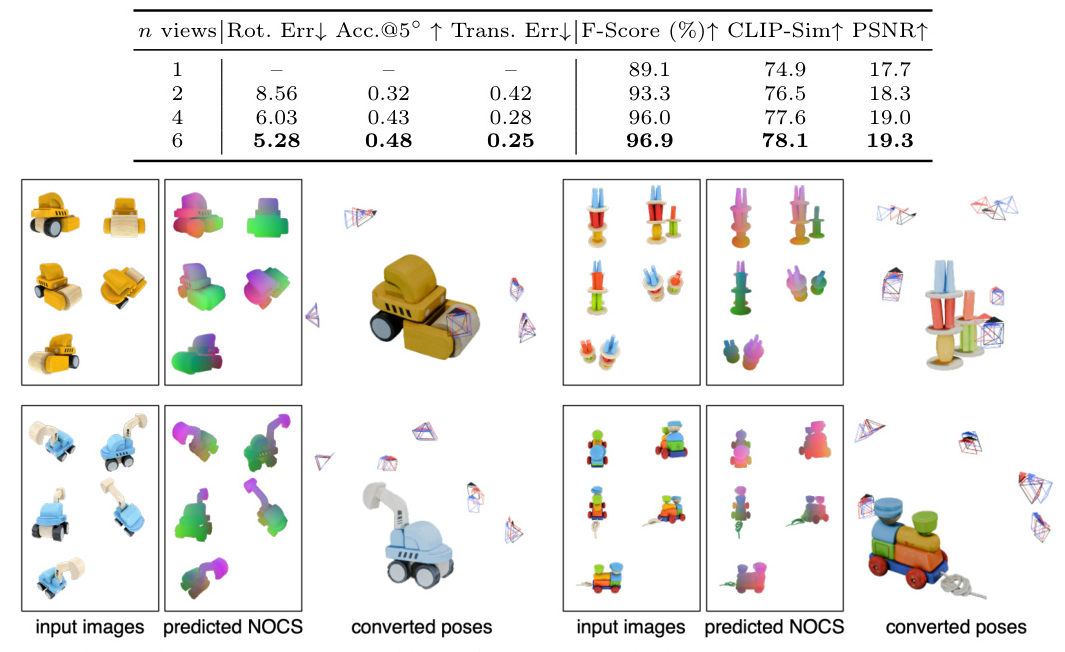
Analysis
The number of input views significantly impacts the performance of both 3D reconstruction and pose estimation. SpaRP effectively integrates information from multiple sparse views, enhancing its ability to capture the spatial relationships and underlying 3D objects. The joint training strategy further improves the performance of both tasks.

Overall Conclusion
SpaRP is a novel method for 3D reconstruction and pose estimation from unposed sparse-view images. It leverages the rich priors embedded in 2D diffusion models to achieve high-quality textured meshes and accurate camera poses in approximately 20 seconds. SpaRP demonstrates strong open-world generalizability and efficiency, significantly outperforming existing methods in both accuracy and runtime.
