

Authors:
Gengwei Zhang、Liyuan Wang、Guoliang Kang、Ling Chen、Yunchao Wei
Paper:
https://arxiv.org/abs/2408.08295
Unleashing the Power of Sequential Fine-tuning for Continual Learning with Pre-training: An In-depth Look at SLCA++
Continual learning (CL) has long been a challenging problem in machine learning, primarily due to the issue of catastrophic forgetting. The advent of pre-trained models (PTMs) has revolutionized this field, offering new avenues for knowledge transfer and robustness. However, the progressive overfitting of pre-trained knowledge into specific downstream tasks remains a significant hurdle. This blog delves into the paper “SLCA++: Unleash the Power of Sequential Fine-tuning for Continual Learning with Pre-training,” which introduces the Slow Learner with Classifier Alignment (SLCA++) framework to address these challenges.
Introduction
Continual learning aims to learn new tasks sequentially without forgetting previously acquired knowledge. Traditional approaches often train models from scratch, which is computationally expensive and prone to catastrophic forgetting. The use of pre-trained models (PTMs) has shown promise in mitigating these issues, but it introduces the problem of progressive overfitting. This paper presents SLCA++, a framework that leverages sequential fine-tuning (Seq FT) to enhance continual learning with pre-training (CLPT).
Key Contributions
- In-depth Analysis of Progressive Overfitting: The paper provides a detailed analysis of the progressive overfitting problem in CLPT.
- Introduction of SLCA++: A novel framework that combines Slow Learner (SL) and Classifier Alignment (CA) to improve Seq FT.
- Parameter-efficient Fine-tuning: The paper introduces Hybrid Slow Learner (Hybrid-SL) to make Seq FT more efficient.
- Extensive Experiments: The framework is tested across various datasets and scenarios, showing substantial improvements over state-of-the-art methods.
Related Work
Continual Learning
Traditional continual learning methods focus on mitigating catastrophic forgetting through regularization, replay-based, and architecture-based strategies. Recent advances have extended these methods to the field of natural language processing.
Continual Learning with Pre-training
The use of pre-trained models in continual learning has shown promise in improving knowledge transfer and robustness. However, existing methods often suffer from limited capacity and sub-optimal performance.
Parameter-efficient Fine-tuning
Parameter-efficient fine-tuning techniques like LoRA and adapters have been introduced to improve the efficiency of fine-tuning large pre-trained models.
Self-supervised Pre-training
Self-supervised pre-training has emerged as a more scalable alternative to supervised pre-training, especially for large-scale datasets.
Continual Learning with Pre-training
Problem Formulation
The paper considers a neural network ( M_\theta ) with parameters ( \theta = {\theta_{rps}, \theta_{cls}} ) for classification tasks. The network is pre-trained on a dataset ( D_{pt} ) and then sequentially fine-tuned on incremental tasks ( D_t ).
Progressive Overfitting
The paper identifies progressive overfitting as a key challenge in CLPT. This problem arises due to the interference of new tasks with pre-trained knowledge, leading to a loss of generalizability and stability.
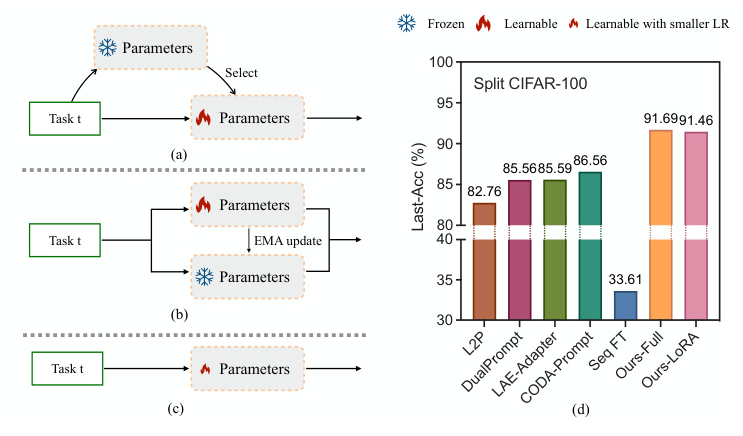
Slow Learner (SL)
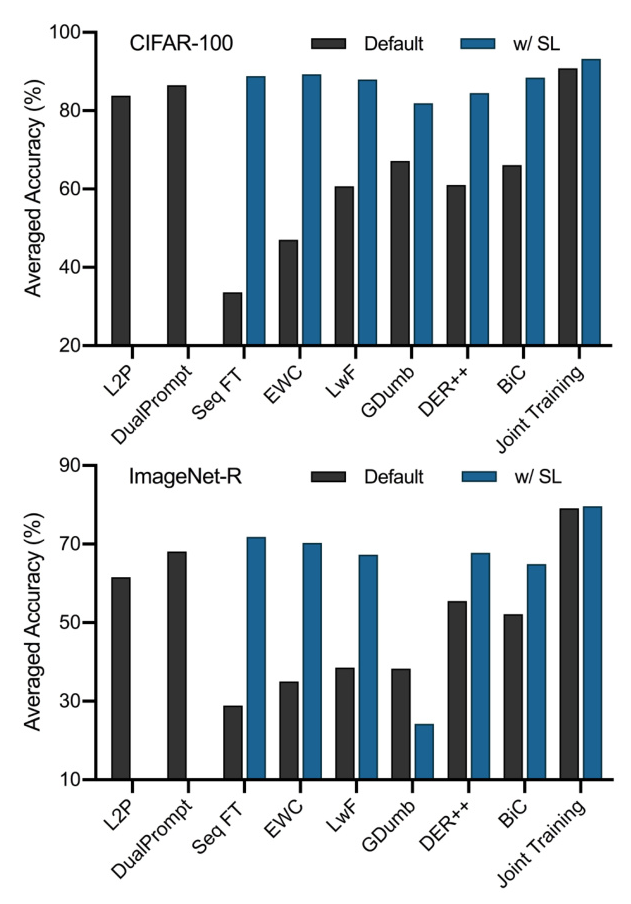
The Slow Learner (SL) strategy selectively reduces the learning rate for the representation layer, effectively balancing pre-trained and task-specific knowledge. This simple yet effective strategy significantly enhances the performance of Seq FT.
Classifier Alignment (CA)
To address the sub-optimal performance of the classification layer, the paper introduces Classifier Alignment (CA). This method saves feature statistics during training and aligns the classifiers in a post-hoc fashion.
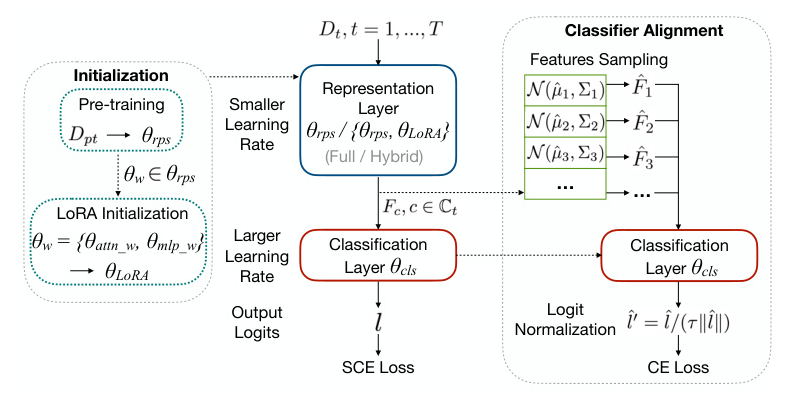
Hybrid Slow Learner (Hybrid-SL)
To make Seq FT more efficient, the paper introduces Hybrid Slow Learner (Hybrid-SL), which combines low-rank adaptation (LoRA) with SL. This approach reduces the number of learnable parameters while maintaining performance.
Experimental Results
Datasets and Evaluation Metrics
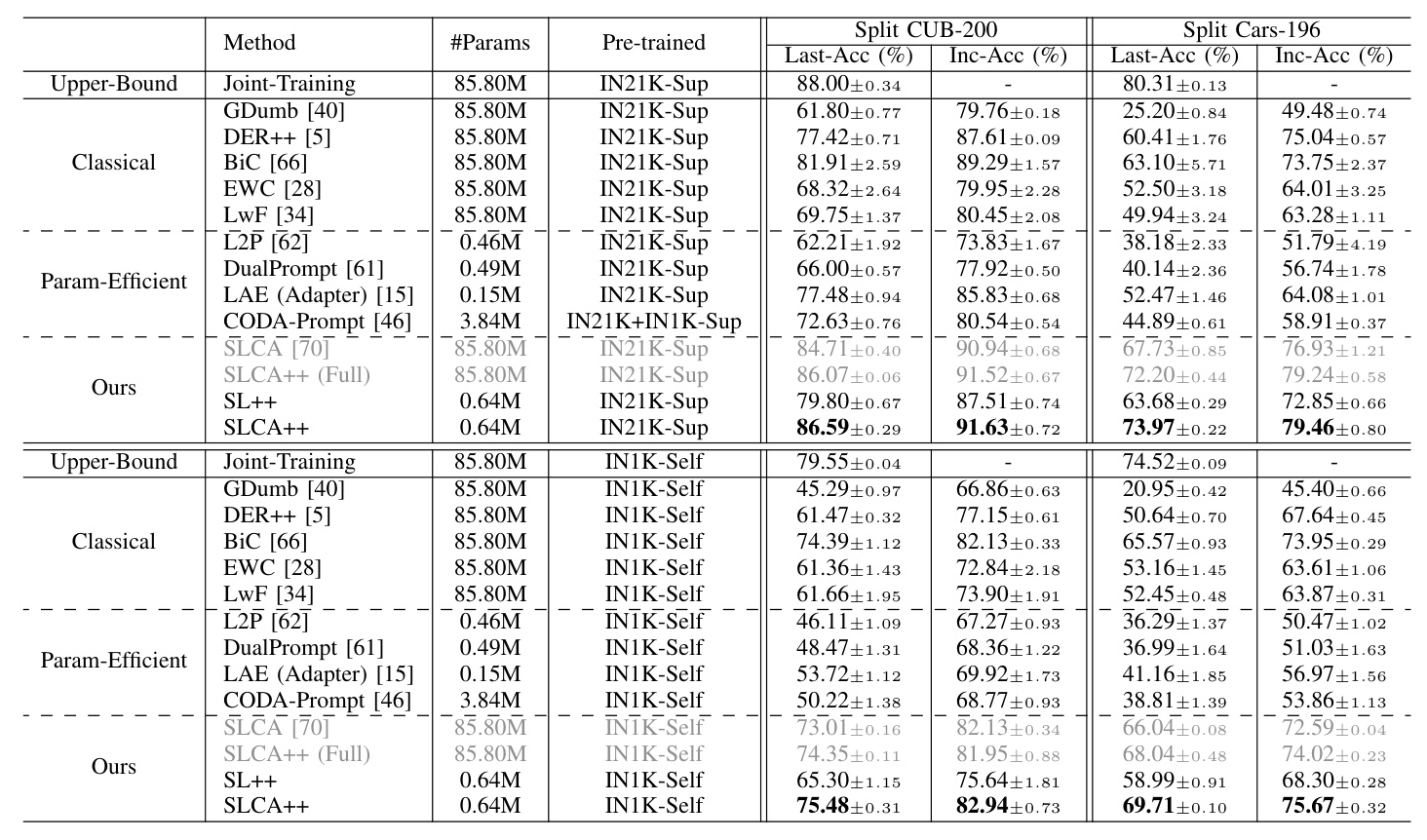
The framework is evaluated on various datasets, including CIFAR-100, ImageNet-R, CUB-200, and Cars-196, under both class-incremental and domain-incremental settings. The primary evaluation metrics are Last-Acc and Inc-Acc.
Overall Performance
SLCA++ consistently outperforms state-of-the-art methods across all datasets and scenarios. The framework shows substantial improvements in both supervised and self-supervised pre-training settings.
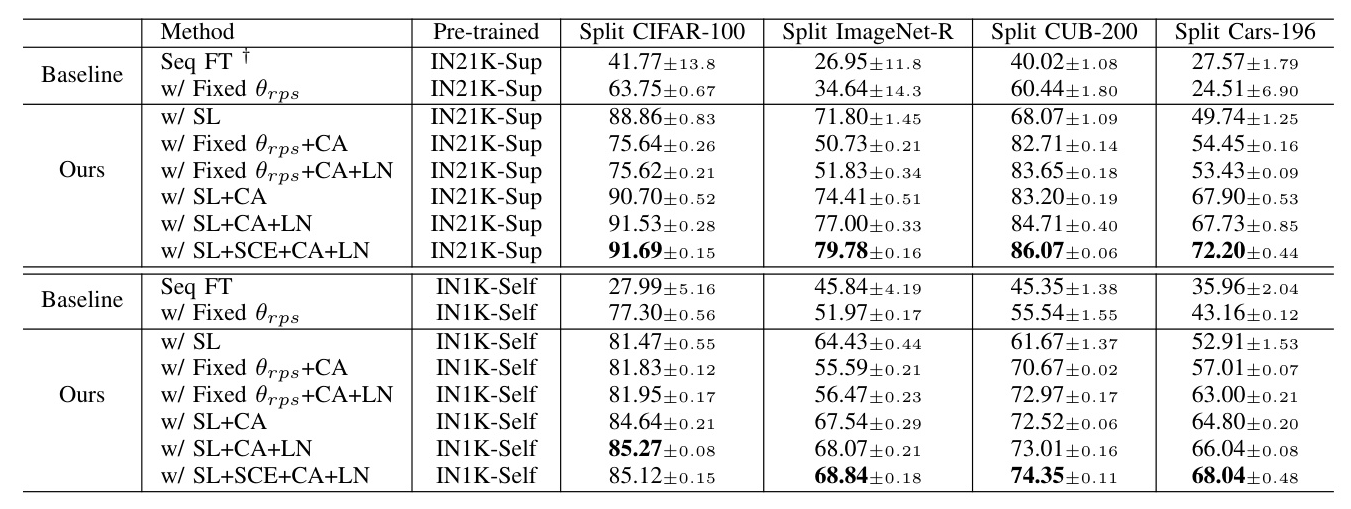
Ablation Studies
The paper conducts extensive ablation studies to evaluate the impact of different components of SLCA++, including SL, CA, and SCE loss. The results validate the effectiveness of each component in improving continual learning performance.
Discussion
Pre-training Paradigm
The paper highlights the importance of self-supervised pre-training for downstream continual learning. It suggests that future research should focus on developing self-supervised pre-training methods that are better suited for continual learning.
Scalability
The framework is designed to be scalable, with efficient computation and minimal storage requirements. The use of shared covariance further reduces the computational overhead.
Learning Rate for CL
One of the key findings is the importance of using a properly adapted learning rate for continual learning. This insight can contribute to various related topics, including continual pre-training for large language models.
Conclusion
SLCA++ is a robust and efficient framework for continual learning with pre-training. By addressing the progressive overfitting problem and introducing parameter-efficient fine-tuning, the framework sets a new benchmark in CLPT. Future work could explore better self-supervised pre-training methods and extend SLCA++ to more complex scenarios.
For more details, you can access the code and additional resources at SLCA++ GitHub Repository.
This blog provides a comprehensive overview of the SLCA++ framework, highlighting its key contributions, experimental results, and potential future directions. The illustrations included help visualize the performance improvements and the effectiveness of different components of the framework.
Code:
https://github.com/gengdavid/slca