

Authors:
Rasha Alshawi、Md Meftahul Ferdaus、Md Tamjidul Hoque、Kendall Niles、Ken Pathak、Steve Sloan、Mahdi Abdelguerfi
Paper:
https://arxiv.org/abs/2408.08879
Introduction
Accurate detection and segmentation of defects in culverts and sewer pipes are crucial for effective infrastructure management. Undetected defects can lead to severe consequences, including structural failures, increased maintenance costs, and environmental hazards. Traditional defect detection methods involve manual inspection, which is time-consuming and prone to human error. Advanced computer vision techniques, like semantic segmentation, offer potential to automate these processes, providing pixel-level labels to objects or regions in an image, making it a powerful tool for understanding and analyzing visual scenes.
Despite its potential, applying semantic segmentation to culvert and sewer pipe inspection presents several challenges. The visual characteristics of these environments are highly diverse, with variations in scale, orientation, appearance, and environmental conditions such as occlusions and lighting changes. Moreover, the datasets available for training models in this domain are often limited and imbalanced, making it challenging to achieve high performance with standard segmentation approaches.
In response to these challenges, the paper introduces SHARP-Net (Semantic Haar-Adaptive Refined Pyramid Network), an innovative approach designed to tackle the complexities inherent in semantic segmentation tasks involving culverts and sewer pipes. SHARP-Net combines hierarchical feature representations extracted by Feature Pyramid Networks (FPN) with advanced enhancements in feature extraction to improve object segmentation and localization accuracy.
Related Work
Various architectures have been developed for semantic segmentation, with prominent approaches including bottom-up top-down networks like FPNs and encoder-decoder networks (EDNs) like U-Net. FPNs efficiently address multi-scale feature extraction by constructing a hierarchical pyramid of feature maps at different resolutions, integrating contextual information to enhance robustness and accuracy. Conversely, EDNs like U-Net efficiently capture spatial dependencies and preserve high-resolution features through skip connections, making them highly effective for precise object localization.
Vision Transformers (ViTs) have become a leading method in computer vision, especially for tasks like image classification and object detection, due to their use of self-attention mechanisms that capture global dependencies across image patches. SegFormer adapts this transformer architecture for semantic segmentation, leveraging transformers’ ability to maintain global context while ensuring accurate spatial representation.
Recent work in sewer and culvert inspection using deep learning has highlighted some specialized approaches to these specific challenges. For instance, several studies have adapted convolutional neural networks (CNNs) and EDNs to detect and classify defects in sewer systems. Despite these advancements, current methods struggle to handle the diverse and complex nature of defects across varied environmental conditions.
Research Methodology
SHARP-Net Base Architecture
The proposed model represents a significant advancement over the original FPN by incorporating an enhanced inception-like block within the bottom-up pathway. This addition improves the model’s ability to learn diverse and fine-grained features essential for accurate image analysis. Additionally, the use of depth-wise separable convolutions reduces model complexity while enhancing its ability to capture detailed information effectively.
The architecture is structured around two pathways, each playing a crucial role in feature refinement:
-
Bottom-Up Pathway: Utilizes inception-like blocks to enhance the model’s ability to localize and detect objects in input images. These blocks process feature maps using a combination of filters with varying sizes (3 × 3 and 5 × 5) and parallel max-pooling layers. Depth-wise separable convolutions improve the model’s efficiency by reducing parameters and computational complexity without compromising performance.
-
Top-Down Pathway: Complements the bottom-up pathway by generating higher-resolution features through upsampling operations and feature fusion. It starts with a 1×1 convolution to reduce the channel depth of the feature maps to 128, aligning it with the depth of the final bottom-up layer. Each subsequent layer in the top-down pathway is upsampled by a factor of 2, which increases the spatial resolution of the feature maps.
-
Common Classifier: A shared classifier across all output feature maps ensures consistency with a 128-dimensional output channel configuration. This facilitates efficient decision-making across diverse image contexts while optimizing computational resources.
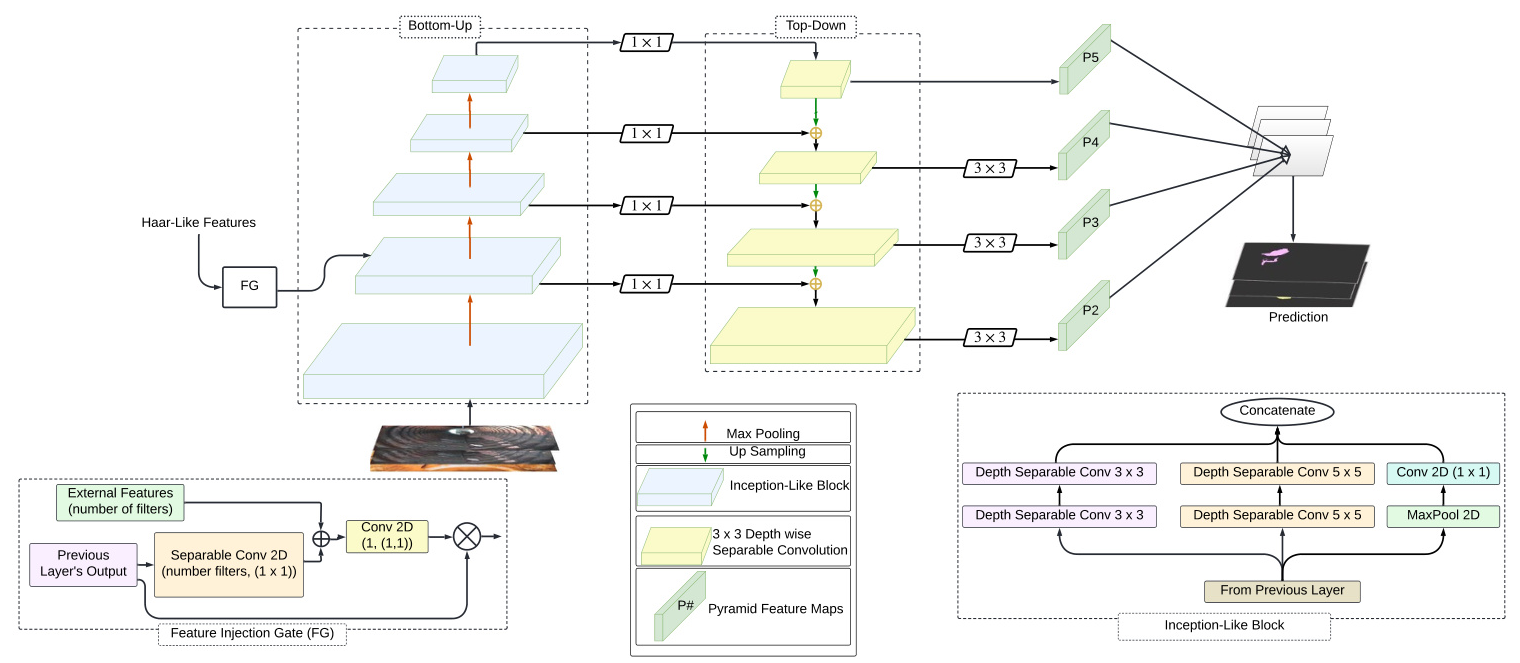
Architectural Evolution: From FPN to SHARP-Net
SHARP-Net evolved from extensive testing, incorporating key advanced elements into the FPN framework. Key architectural changes from FPN to SHARP-Net include:
-
Inception Block and Residual Connections: Enhanced the FPN’s Bottom-Up pathway by integrating Inception blocks and residual connections, improving multi-scale feature extraction and deep network training.
-
Factorized Inception Block: Improved computational efficiency by using a factorized Inception block, which breaks down large convolutions into smaller operations like 1 × 1 and 3 × 3 convolutions.
-
FPN with Atrous Convolutions: Integrated atrous convolutions into the FPN framework to expand the model’s receptive field without increasing parameters or sacrificing spatial resolution.
-
FPN with Self-Attention Mechanisms: Incorporated self-attention mechanisms to capture long-range dependencies and global context.
-
FPN with Attention Gates and Squeeze-and-Excitation Blocks: Enhanced FPN with Attention Gates and Squeeze-and-Excitation (SE) Blocks to dynamically highlight crucial regions in feature maps and recalibrate channel-wise feature responses.
Haar-Like Feature Injection
To improve SHARP-Net’s performance, Haar-like features were incorporated. Haar-like features, consisting of simple rectangular patterns, are effective for edge detection, line identification, and texture analysis. These computationally efficient features complement SHARP-Net’s deep learning capabilities, potentially addressing challenges in defect segmentation for culvert and sewer pipe imagery.

Experimental Design
Datasets
Culvert-Sewer Defects Dataset
The Culvert-Sewer Defects dataset was created by collecting inspection videos, converting them into frames, and performing pixel-wise annotation. The dataset comprises 580 annotated underground infrastructure inspection videos, capturing variations in materials, shapes, dimensions, and imaging environments typical of inspection scenarios. The dataset is representative of the challenges faced during actual inspections, with significant class imbalance reflecting the natural occurrence of various deficiencies.
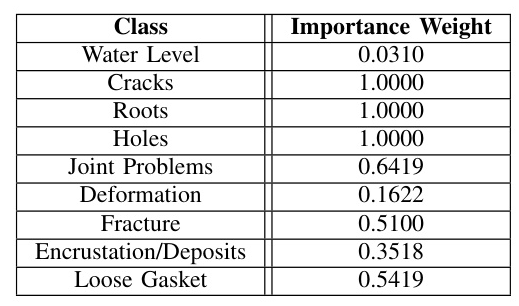
DeepGlobe Land Cover Classification Dataset
The DeepGlobe Land Cover Classification Dataset is derived from the DigitalGlobe Vivid+ collection, focusing on rural areas. It includes seven land cover classes: agriculture land, urban land, rangeland, water, barren land, forest land, and unknown. The dataset is divided into three subsets: 803 training images, 172 test images, and 171 validation images.
Experimental Setup and Training Protocol
-
Metrics Used for Evaluation: Intersection over Union (IoU), Frequency-Weighted IoU (FWIoU), F1-Score, Balanced Accuracy, and Matthews Correlation Coefficient (MCC).
-
Optimization and Loss Functions: Adam optimizer with a learning rate of 10−3 and categorical cross-entropy loss.
-
Training Procedures: All models are trained for 100 epochs on the Culvert-Sewer Defects dataset and 200 epochs on the DeepGlobe Land Cover benchmark dataset. The datasets are divided into three subsets: training (70%), validation (15%), and test (15%).
-
Hardware and Software: Models are trained using NVIDIA T4 GPUs with Keras TensorFlow.
Results and Analysis
Comparison with Baseline Architectures
The base SHARP-Net (without Haar-like features) was compared to several models, including U-Net, CBAM U-Net, ASCU-Net, FPN with ResNet, and SegFormer. SHARP-Net consistently outperformed these models, achieving higher IoU scores and demonstrating superior performance in handling complex image reconstruction tasks.

Model Efficiency and Computational Performance
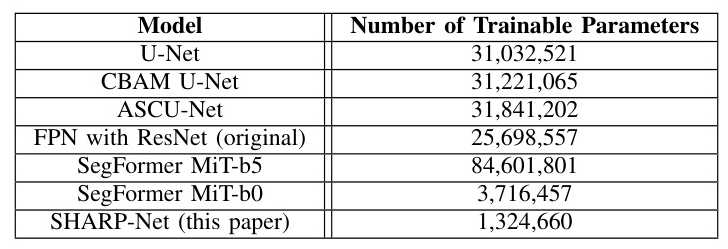
The proposed model is remarkably efficient, with only 1.32 million parameters, representing a 19-24 times reduction compared to baseline models. This reduction has important implications for model performance and applicability, particularly in resource-constrained environments.
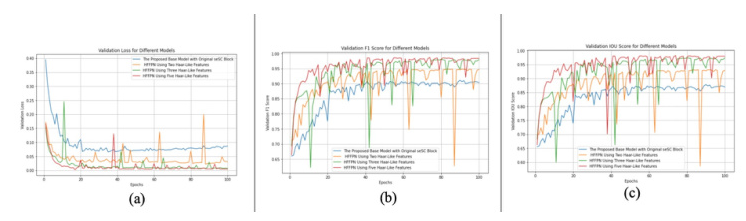
Impact of Haar-Like Features
Incorporating Haar-like features significantly improved performance. The integration of Haar-like features yielded a 20-30% improvement in IoU scores, highlighting the significant benefits of this approach. The method’s versatility is evident in its successful application across diverse models and datasets.
Overall Conclusion
SHARP-Net is a novel deep learning architecture for precise semantic segmentation on challenging multiclass datasets. It combines a bottom-up top-down structure with sparsely connected blocks, depth-wise separable convolutions, and Haar-like feature extraction. This design addresses issues like irregular defect shapes, occlusions, limited data, and class imbalance. SHARP-Net consistently outperforms state-of-the-art architectures, demonstrating superior performance and efficiency.
Future research should focus on automating feature selection, exploring cross-domain adaptability, and optimizing for edge deployment. Additionally, incorporating temporal consistency for video segmentation, integrating multimodal data, and enhancing model interpretability will be crucial. These advancements aim to broaden SHARP-Net’s applicability and push the boundaries of semantic segmentation.