Authors:
Paper:
https://arxiv.org/abs/2408.09853
Self-Directed Turing Test for Large Language Models: An In-Depth Analysis
Introduction
The Turing Test, introduced by Alan Turing in 1950, has long been a benchmark for evaluating whether a machine can exhibit human-like behavior in natural language conversations. Traditionally, this test involves a human evaluator engaging in a text-based conversation with both a human and an AI, attempting to distinguish between the two. However, the conventional Turing Test has several limitations, such as its rigid dialogue format and the need for continuous human involvement, which restricts the test duration and fails to reflect natural conversational styles.
To address these limitations, the paper “Self-Directed Turing Test for Large Language Models” by Weiqi Wu, Hongqiu Wu, and Hai Zhao proposes a novel framework called the Self-Directed Turing Test. This new approach extends the traditional Turing Test by incorporating a burst dialogue format and allowing the AI to self-direct the majority of the test process. This blog post delves into the details of this innovative framework, its methodology, experimental design, and the results obtained from evaluating various Large Language Models (LLMs).
Related Work
Turing Test and Its Variations
The Turing Test has been extensively used to assess AI’s human-like abilities across multiple domains, including dialogue interaction, question answering, text generation, and visual tasks. However, existing works have highlighted several limitations of the traditional Turing Test, questioning whether passing the test accurately or comprehensively indicates intelligence. This study builds on these insights by proposing an automated approach to reduce the significant human effort required by Turing Tests.
Role-Playing with LLMs
A common tactic in Turing Tests is to assign LLMs the role of a specific human character, leveraging their proficiency in adopting varied attributes and conversational styles. By utilizing the dialogue history of a designated individual, researchers can develop role-playing chatbots that effectively handle various dialogue forms and scenarios.
Dialogue Generation
The development of synthetic dialogue data has provided a more efficient and scalable approach to data creation and augmentation. Advancements in dialogue generation have been facilitated by LLMs, which excel at creating contextually relevant and diverse conversations. By iteratively generating dialogues that imitate interactions with a human, researchers can efficiently simulate the Turing Test over extensive turns and facilitate further judgment.
Research Methodology
Burst Dialogue vs. Ping-Pong Dialogue
Traditional Turing Tests follow a strict ping-pong structure, where each user message is followed by a system response. However, real-life conversations often involve multiple messages in rapid succession without waiting for a response. This study defines this communication pattern as Burst Dialogue and explores the performance of LLMs in this setting. Burst Dialogue is more dynamic and aligns more closely with natural human communication patterns, challenging LLMs to handle overlapping and rapidly evolving conversational contexts.
Chatbot Construction
To deploy an LLM as a chatbot for the Turing Test, the researchers construct the chatbot based on real-life dialogue history. This approach provides essential clues for generating responses that emulate the target personality, linguistic style, and content. The chatbot system enabling burst dialogue consists of three modules working synchronously: Input Listener, Model Caller, and Output Sender. This system introduces a brief time interval before processing the first batch of user inputs, allowing the user to fully express themselves.
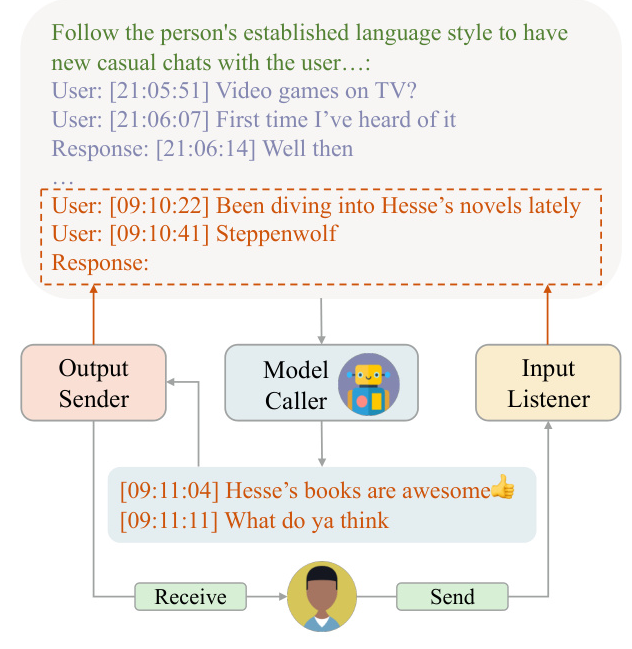
Pseudo-Dialogue Generation
To enhance the efficiency of the Turing Test, the researchers propose letting the LLMs direct the progression of the test by synthesizing extended user-machine interaction through dialogue generation. The process involves generating topics, utilizing the LLM to produce multi-turn dialogues for each topic, and appending the generated dialogue to the dialogue history for subsequent iterations. This approach allows for a comprehensive assessment of the LLM’s performance over prolonged interactions.

Experimental Design
Test Setup
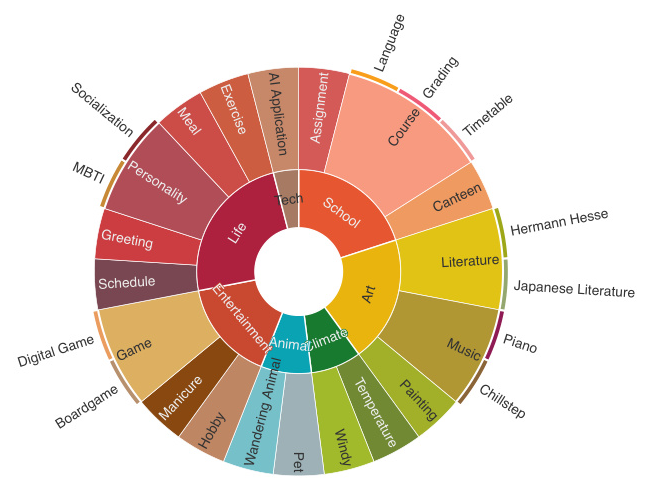
The researchers provide 100 turns of dialogue history in the context and evaluate the capabilities of GPT-4, Claude-3-Sonnet, and Qwen-110B-Chat to respond like a human in real-life conversation across 25 topics, including education, technology, art, and more. The topics are carefully selected to cover a broad range of scenarios where conversational AI can be applied while avoiding appearing in the dialogue history.
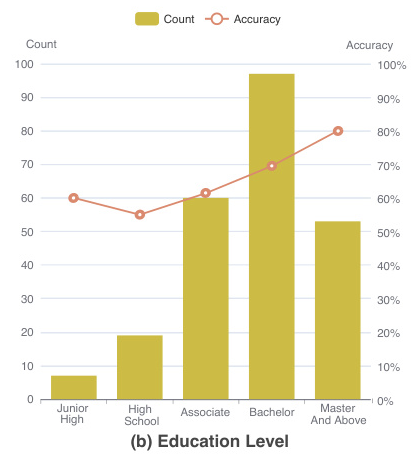
Human and LLM Judges
A total of 236 native speakers participate in the survey as human judges, evaluating pairs of conversations and distinguishing the human-human conversation from the human-machine one. Additionally, GPT-4 and Qwen-110B serve as LLM judges to explore whether LLMs can distinguish between humans and themselves.
Metric: X-Turn Pass Rate
The X-Turn Pass Rate metric evaluates the possibility that the model can pass the Turing Test within specified turns of dialogue. This metric assesses the proportion of dialogues in which the judges fail to distinguish between human and machine, with a higher pass rate indicating more human-like performance by the LLM.
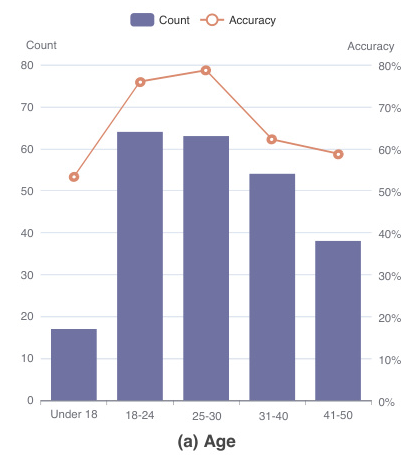
Results and Analysis
Pass Rates and Dialogue Settings
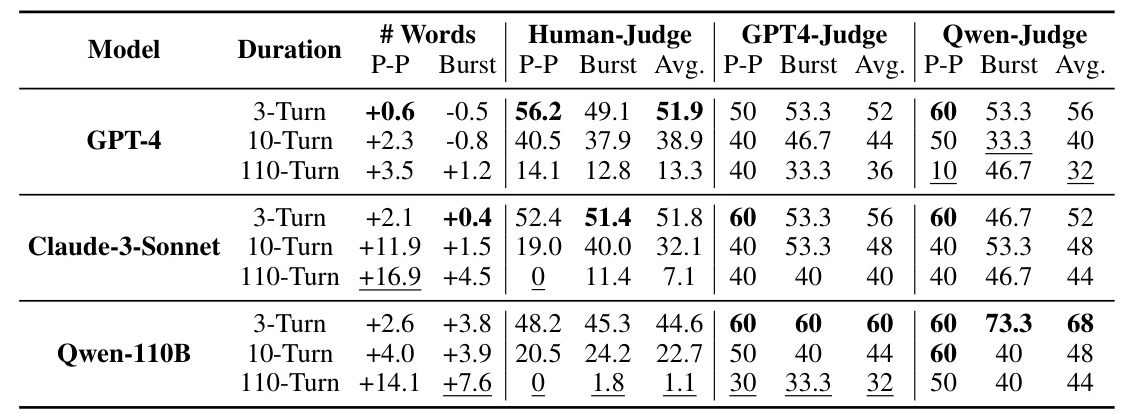
The results highlight a significant influence of dialogue length on model performance. GPT-4 maintains a consistently higher average pass rate across all tested turns compared to other models, achieving the best average 3-turn pass rate of 51.9%. However, as the dialogue progresses, the average word count per message increases, and all models exhibit a significant decrease in their pass rates, showcasing the necessity of long Turing Tests.
Gap Between Human and LLM Judgment
As the number of testing turns increases, all judges become increasingly adept at distinguishing between LLM and human interlocutors, resulting in a decreasing pass rate. However, human judges generally perceive GPT-4 and Claude-3-Sonnet as more human-like in conversations, whereas both LLMs tend to prefer Qwen-110B. This gap highlights the insufficiency of models in understanding and simulating real-world communications.
Comparison Between Dialogue Settings
Comparing the extended burst dialogue setting with the classical ping-pong setting reveals notable differences. Although characterized by more complex information exchanges, all models better mimic human messaging habits in the number of words per message under the burst setting. However, performance variations exist between the two formats, with Claude-3-Sonnet and Qwen-110B excelling in burst dialogues, while GPT-4 performs better in ping-pong dialogues.
Overall Conclusion
The Self-Directed Turing Test framework effectively and efficiently evaluates the human likeness of LLMs through pseudo-dialogue generation with extended dialogue settings. The experiments reveal that GPT-4 outperforms other tested models across most configurations and evaluation criteria, achieving an average pass rate of 51.9% and 38.9% in 3-turn and 10-turn dialogues, respectively. However, as dialogue length increases, the pass rates for all models significantly drop, highlighting the challenges in maintaining consistency and human-like responses over prolonged interactions.
Limitations
While the study presents an innovative approach to evaluating LLMs, several limitations must be acknowledged. Responses from LLMs are influenced by user inputs and previous LLM-generated dialogue quality, and using static evaluation techniques like questionnaires cannot eliminate the impact of user preferences. Additionally, the subjective nature of human judgment in evaluating AI responses can lead to inconsistencies.
Ethics Statement
The research adheres to stringent ethical guidelines to ensure the privacy, consent, and well-being of all participants involved. Key ethical considerations include informed consent, data anonymization, and data security.
In conclusion, the Self-Directed Turing Test framework offers a promising approach to evaluating the human likeness of LLMs, providing valuable insights into their capabilities and limitations in natural language conversations.