

Authors:
Paper:
https://arxiv.org/abs/2408.09121
Selective Prompt Anchoring for Code Generation: A Detailed Interpretive Blog
Introduction
Background
Recent advancements in large language models (LLMs) like Copilot and ChatGPT have significantly transformed software development by automating coding tasks. These models leverage vast datasets and sophisticated algorithms to interpret natural language descriptions and generate corresponding code. Despite their impressive capabilities, LLMs still face challenges in reducing error rates and fully meeting user expectations. This study aims to address these challenges by proposing a novel approach called Selective Prompt Anchoring (SPA).
Problem Statement
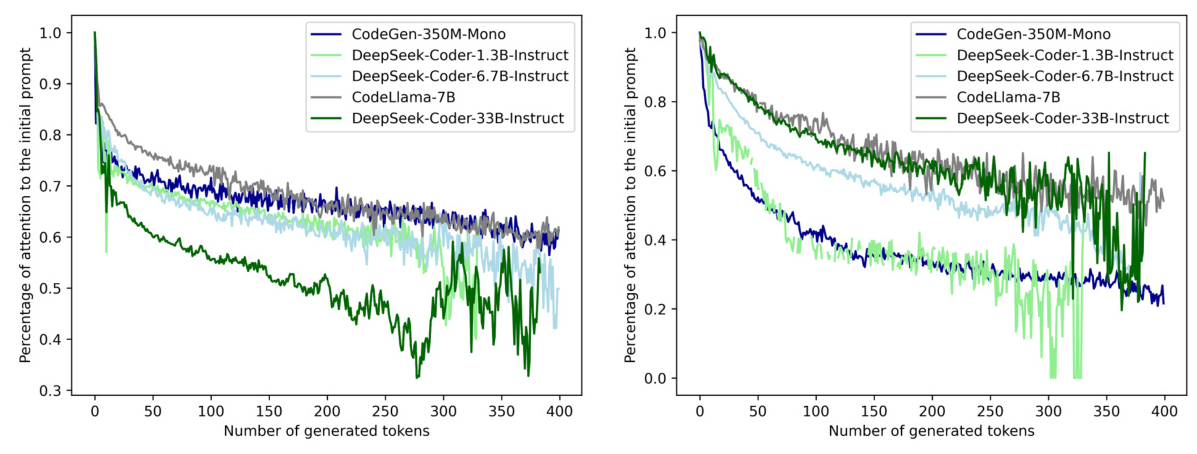
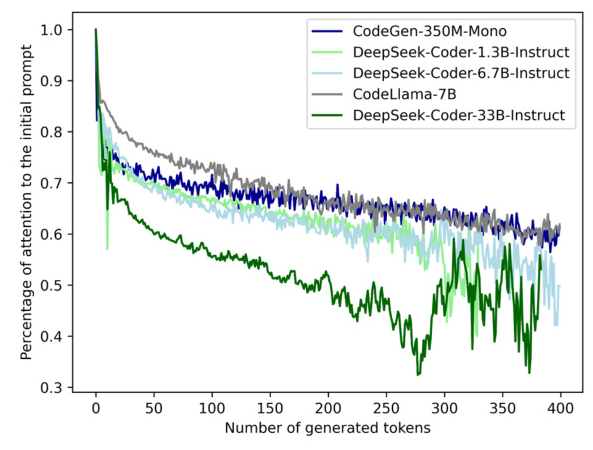
The primary issue identified in this study is the dilution of self-attention in LLMs as more code tokens are generated. This dilution leads to inaccuracies in the generated code, as the model’s focus shifts away from the initial prompt. The study hypothesizes that this self-attention dilution is a root cause of inaccuracies in LLM-generated code.
Related Work
Enhancing LLM Performance
Several approaches have been explored to improve the performance of LLMs on coding tasks. These include developing high-quality training data and designing new domain-specific training objectives. However, these methods require substantial computational resources. Training-free approaches, such as enhancing the prompting method or incorporating external knowledge, have also been explored. While effective, these methods have limitations, such as sensitivity to the quality of prompt design and retrieved data.
Self-Attention Mechanism
The self-attention mechanism in transformer-based LLMs enables models to dynamically focus on crucial parts of the given prompt. Despite its success, prior works have found that LLMs often exhibit simple attention patterns and misalignment between LLM attention and human attention. This misalignment can lead to inaccuracies in generated code, especially when the model’s attention shifts away from the initial prompt.
Research Methodology
Selective Prompt Anchoring (SPA)
SPA is a model-agnostic approach designed to optimize LLMs’ attention by amplifying the contextual contribution of selective parts of the initial prompt, referred to as “anchored text.” SPA calculates the logit distribution difference with and without the anchored text, approximating the anchored text’s contextual contribution to the output logits. This difference is then used to create an augmented logit distribution by linearly combining the original logit distribution and the logit difference.
Mathematical Foundation
SPA introduces a mechanism to adjust the semantic impact of arbitrary groups of token embeddings in the input matrix towards the output logits. The approach involves creating an original embedding matrix and a masked embedding matrix by replacing the embeddings corresponding to the anchored text with mask embeddings. The difference between the logit distributions generated from these matrices approximates the contextual contribution of the anchored text.
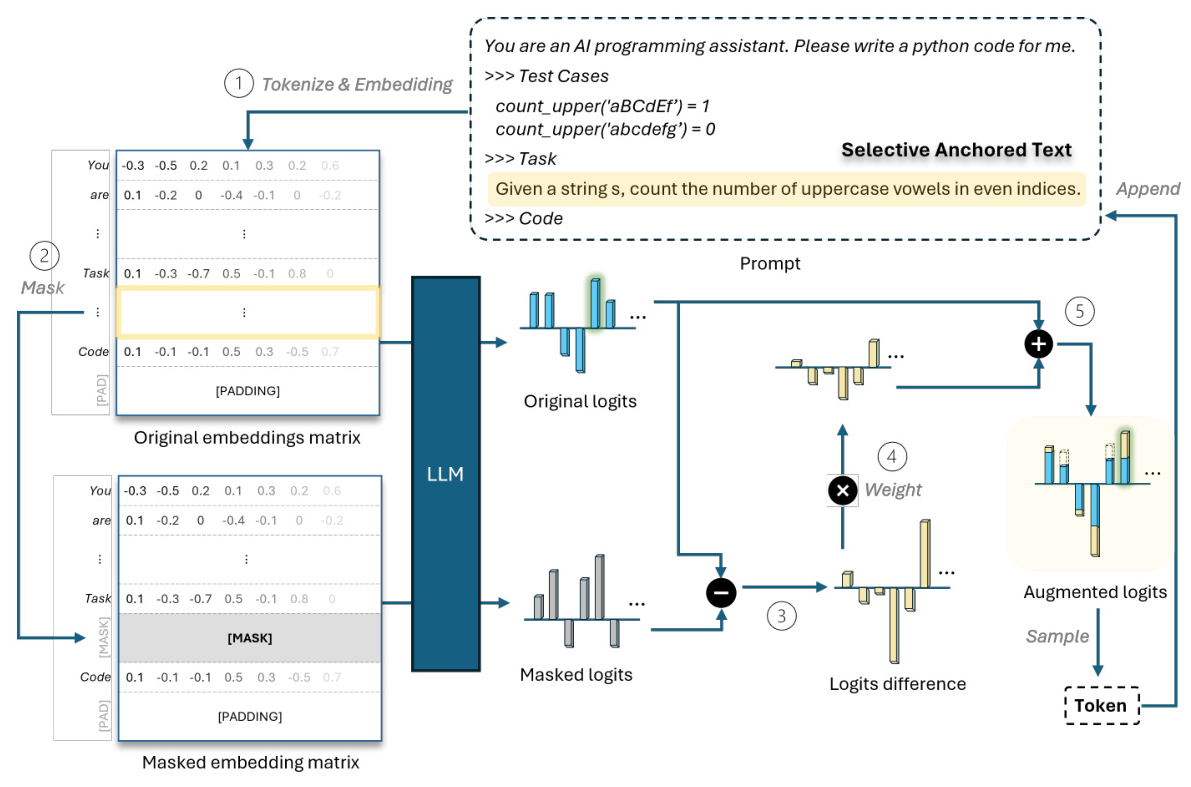
Experimental Design
Benchmarks and Models
The study evaluates SPA on four benchmarks with five different-sized LLMs. The benchmarks include HumanEval, MBPP, HumanEval+, and MBPP+. The selected models are CodeGen-Mono, CodeLlama, and three different-sized DeepSeek-Coder-Instruct models. These models have been fine-tuned for code generation tasks, covering diverse state-of-the-art code LLMs of different types and sizes.
Experiment Setup
The experiments are conducted on eight A5500 GPUs with 192GB memory over five weeks. The models are deployed from Huggingface, and 8-bit quantization is applied to speed up evaluations. The original task descriptions from the datasets are used as prompts for the text-completion models, while the official chat template from HuggingFace is used for the DeepSeek-Coder-Instruct models. All experiments are conducted in a zero-shot setting.
Evaluation Metric
The performance of the models is measured using the Pass@k metric, which assesses whether any of k candidates can pass all the test cases. In this study, k is set to 1, meaning each task generates one code snippet using greedy sampling. The generated code is considered correct if it passes all the test cases.
Results and Analysis
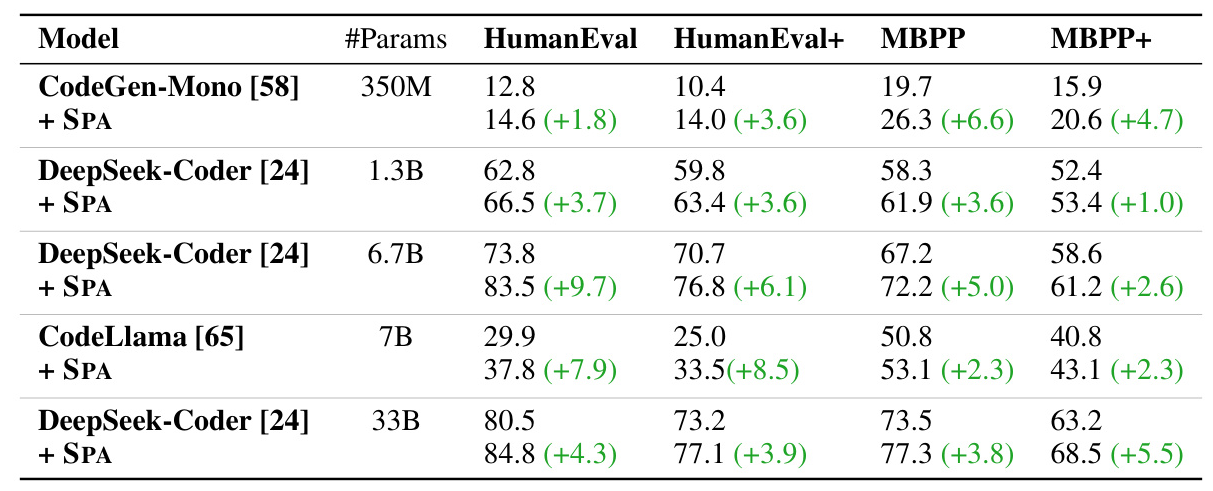
Main Results
The results indicate that using SPA consistently improves the Pass@1 rate across all benchmarks and LLMs. The improvement is up to 9.7% on HumanEval for DeepSeek-Coder (6.7B). Notably, through selective text anchoring, the small version of DeepSeek-Coder (6.7B) surpasses a much larger version (33B), supporting the hypothesis that inaccuracies in LLMs mainly stem from poor attention, not their generative capabilities.
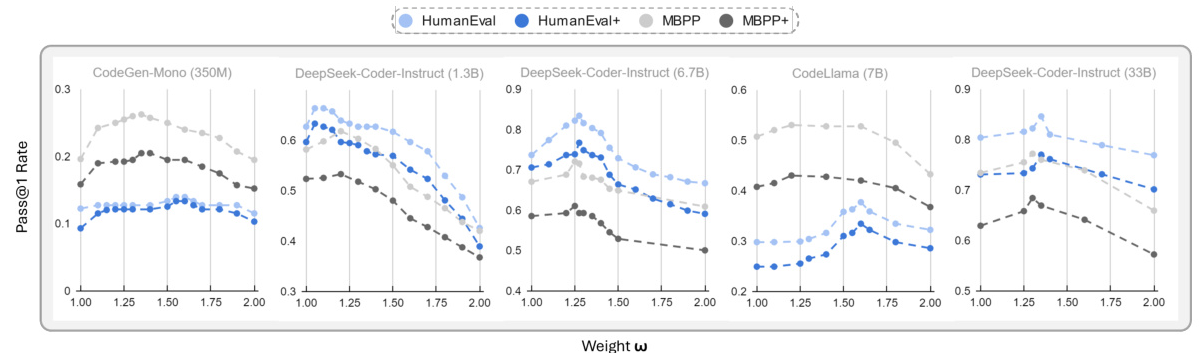
Analysis of Weighting Values
SPA introduces a single weighting hyperparameter ω, used to adjust the magnitude of the anchoring effect. The optimal ω slightly varies across different models and benchmarks, but there is a roughly unimodal relationship between the weight ω and performance. As the weight increases, the performance first improves, reaches an optimum, and then declines with further increases of ω.
Analysis of Anchored Text Selection
The study analyzes how anchored text selection impacts the performance of SPA. The results show that anchoring the task description alone yields the best performance. This implies that anchoring more tokens in the prompt may not necessarily be helpful. Narrowing down the anchored text to fewer but critical, informative tokens can lead to better performance.

Overall Conclusion
Summary
This study proposes Selective Prompt Anchoring (SPA), a training-free approach designed to enhance the quality of code generated by large language models (LLMs) by mitigating the attention dilution issue. SPA employs a novel technique to adjust the influence of arbitrary groups of input tokens based on a mathematical approximation. The empirical studies indicate that LLMs may overlook the initial prompt as more tokens are generated, leading to inaccuracies in the generated code. SPA addresses this issue by amplifying the impact of the initial prompt throughout the code generation process.
Future Work
The effectiveness of SPA highlights its potential in other domains, especially for generation tasks. The underlying principle of SPA is not confined to transformer-based LLMs and could be adapted for use in other model architectures. Future work could involve dynamically determining the anchored text and weighting value according to different contexts and sampling stages.
By addressing the attention dilution issue, SPA offers a promising direction for improving the performance and reliability of LLMs in code generation and potentially other tasks.
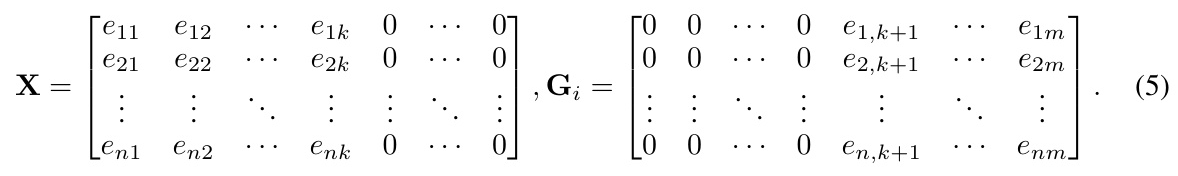
Code:
https://github.com/magic-yuantian/selective-prompt-anchoring